 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robustness of Text-to-Visualization Translation against Lexical and Phrasal Variability
Apr 11, 2024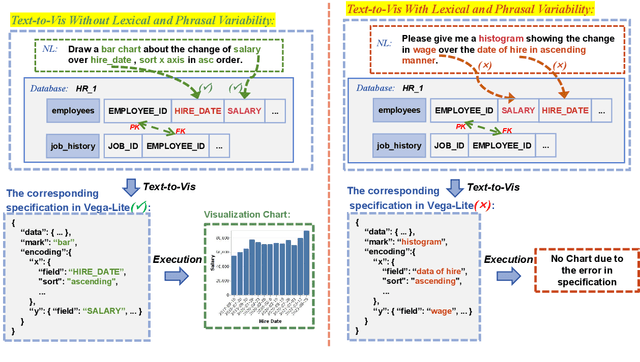
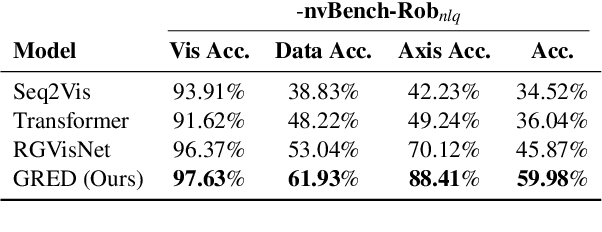
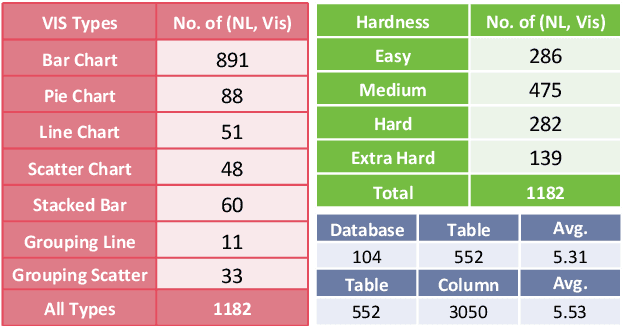
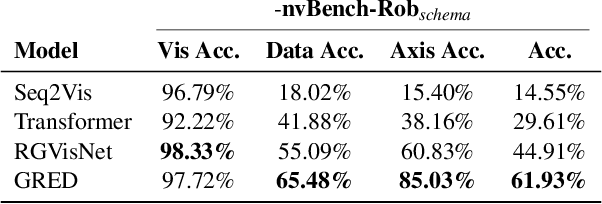
Text-to-Vis is an emerging task in the natural language processing (NLP) area that aims to automatically generate data visualizations from natural language questions (NLQs). Despite their progress, existing text-to-vis models often heavily rely on lexical matching between words in the questions and tokens in data schemas. This overreliance on lexical matching may lead to a diminished level of model robustness against input variations. In this study, we thoroughly examine the robustness of current text-to-vis models, an area that has not previously been explored. In particular, we construct the first robustness dataset nvBench-Rob, which contains diverse lexical and phrasal variations based on the original text-to-vis benchmark nvBench. Then, we found that the performance of existing text-to-vis models on this new dataset dramatically drops, implying that these methods exhibit inadequate robustness overall. Finally, we propose a novel framework based on Retrieval-Augmented Generation (RAG) technique, named GRED, specifically designed to address input perturbations in these two variants. The framework consists of three parts: NLQ-Retrieval Generator, Visualization Query-Retrieval Retuner and Annotation-based Debugger, which are used to tackle the challenges posed by natural language variants, programming style differences and data schema variants, respectively. Extensive experimental evaluations show that, compared to the state-of-the-art model RGVisNet in the Text-to-Vis field, GRED performs better in terms of model robustness, with a 32% increase in accuracy on the proposed nvBench-Rob dataset.
Self-Convinced Prompting: Few-Shot Question Answering with Repeated Introspection
Oct 10, 2023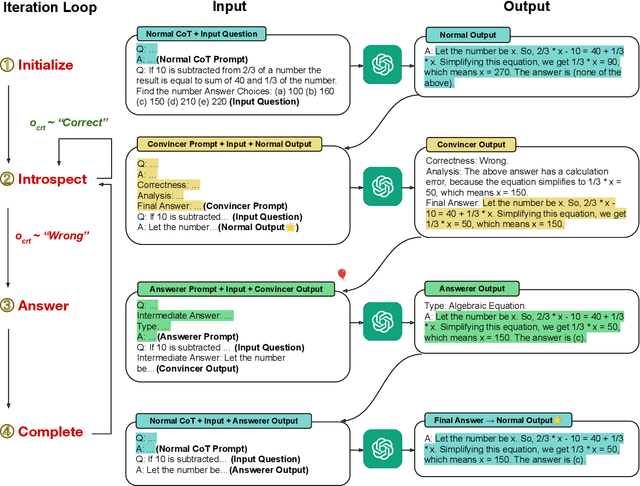
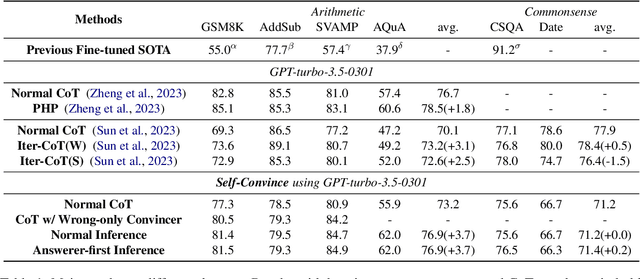
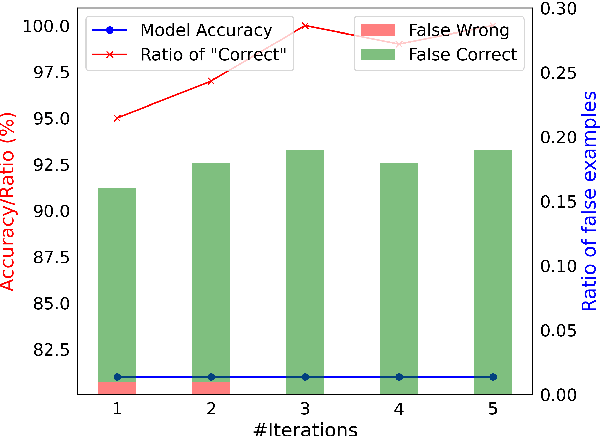
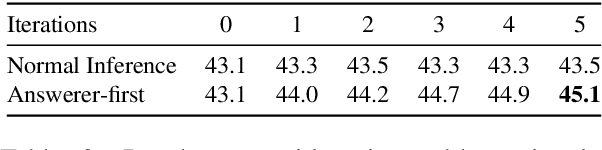
While large language models (LLMs) such as ChatGPT and PaLM have demonstrated remarkable performance in various language understanding and generation tasks, their capabilities in complex reasoning and intricate knowledge utilization still fall short of human-level proficiency. Recent studies have established the effectiveness of prompts in steering LLMs towards generating desired outputs. Building on these insights, we introduce a novel framework that harnesses the potential of large-scale pre-trained language models, to iteratively enhance performance of the LLMs. Our framework incorporates three components: \textit{Normal CoT}, a \textit{Convincer}, and an \textit{Answerer}. It processes the output of a typical few-shot chain-of-thought prompt, assesses the correctness of the response, scrutinizes the answer, refines the reasoning, and ultimately produces a new solution. Experimental results on the 7 datasets of miscellaneous problems validate the efficacy of the Self-Convince framework, achieving substantial improvements compared to the baselines. This study contributes to the burgeoning body of research focused on integrating pre-trained language models with tailored prompts and iterative refinement processes to augment their performance in complex tasks.
MMLN: Leveraging Domain Knowledge for Multimodal Diagnosis
Feb 09, 2022
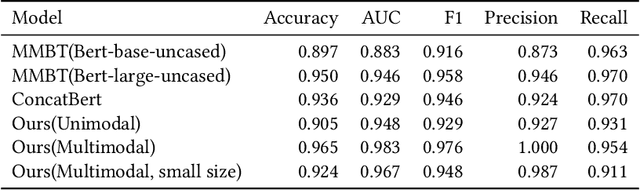
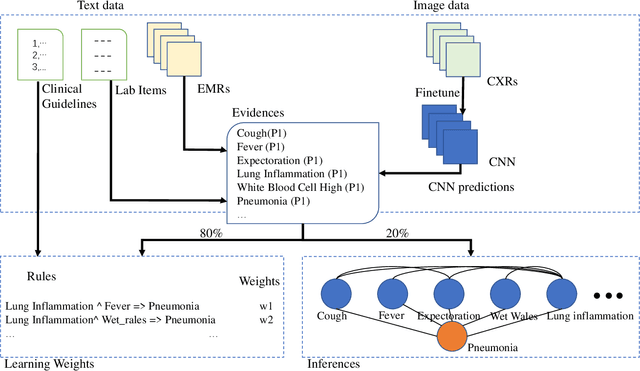

Recent studies show that deep learning models achieve good performance on medical imaging tasks such as diagnosis prediction. Among the models, multimodality has been an emerging trend, integrating different forms of data such as chest X-ray (CXR) images and electronic medical records (EMRs). However, most existing methods incorporate them in a model-free manner, which lacks theoretical support and ignores the intrinsic relations between different data sources. To address this problem, we propose a knowledge-driven and data-driven framework for lung disease diagnosis. By incorporating domain knowledge, machine learning models can reduce the dependence on labeled data and improve interpretability. We formulate diagnosis rules according to authoritative clinical medicine guidelines and learn the weights of rules from text data. Finally, a multimodal fusion consisting of text and image data is designed to infer the marginal probability of lung disease. We conduct experiments on a real-world dataset collected from a hospital. The results show that the proposed method outperforms the state-of-the-art multimodal baselines in terms of accuracy and interpretability.
Faster and Safer Training by Embedding High-Level Knowledge into Deep Reinforcement Learning
Oct 22, 2019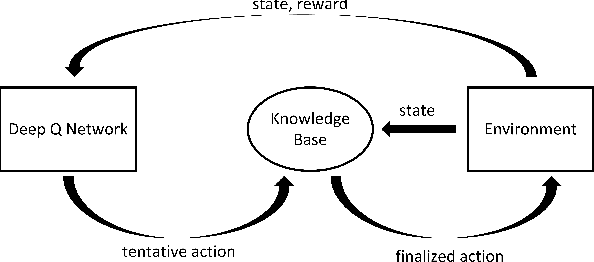
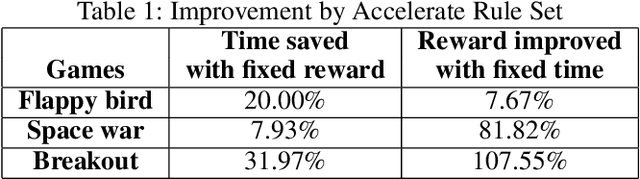

Deep reinforcement learning has been successfully used in many dynamic decision making domains, especially those with very large state spaces. However, it is also well-known that deep reinforcement learning can be very slow and resource intensive. The resulting system is often brittle and difficult to explain. In this paper, we attempt to address some of these problems by proposing a framework of Rule-interposing Learning (RIL) that embeds high level rules into the deep reinforcement learning. With some good rules, this framework not only can accelerate the learning process, but also keep it away from catastrophic explorations, thus making the system relatively stable even during the very early stage of training. Moreover, given the rules are high level and easy to interpret, they can be easily maintained, updated and shared with other similar tasks.