 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Convinced Prompting: Few-Shot Question Answering with Repeated Introspection
Paper and Code
Oct 10, 2023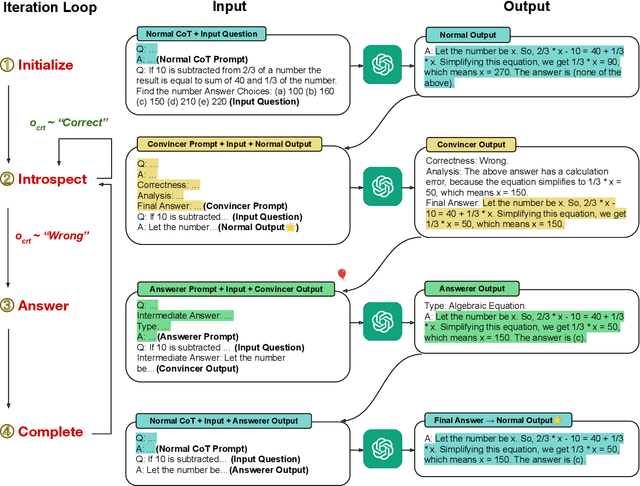
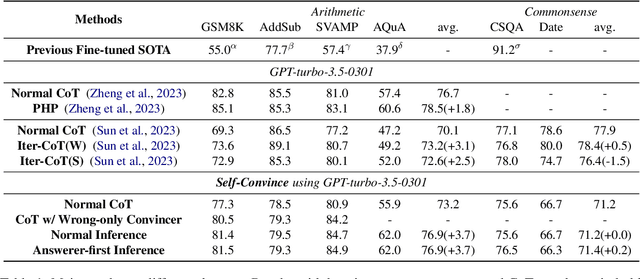
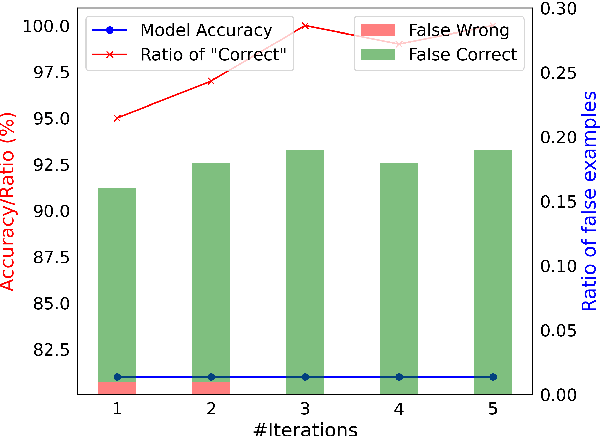
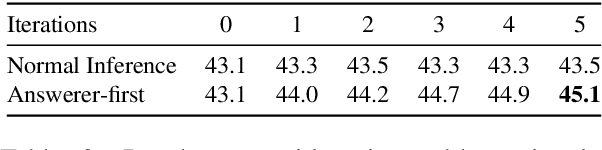
While large language models (LLMs) such as ChatGPT and PaLM have demonstrated remarkable performance in various language understanding and generation tasks, their capabilities in complex reasoning and intricate knowledge utilization still fall short of human-level proficiency. Recent studies have established the effectiveness of prompts in steering LLMs towards generating desired outputs. Building on these insights, we introduce a novel framework that harnesses the potential of large-scale pre-trained language models, to iteratively enhance performance of the LLMs. Our framework incorporates three components: \textit{Normal CoT}, a \textit{Convincer}, and an \textit{Answerer}. It processes the output of a typical few-shot chain-of-thought prompt, assesses the correctness of the response, scrutinizes the answer, refines the reasoning, and ultimately produces a new solution. Experimental results on the 7 datasets of miscellaneous problems validate the efficacy of the Self-Convince framework, achieving substantial improvements compared to the baselines. This study contributes to the burgeoning body of research focused on integrating pre-trained language models with tailored prompts and iterative refinement processes to augment their performance in complex tasks.