 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Geometry for the classification of brain states with intracortical brain-computer interfaces
Apr 07, 2025This study investigates the application of Riemannian geometry-based methods for brain decoding using invasive electrophysiological recordings. Although previously employed in non-invasive, the utility of Riemannian geometry for invasive datasets, which are typically smaller and scarcer, remains less explored. Here, we propose a Minimum Distance to Mean (MDM) classifier using a Riemannian geometry approach based on covariance matrices extracted from intracortical Local Field Potential (LFP) recordings across various regions during different brain state dynamics. For benchmarking, we evaluated the performance of our approach against Convolutional Neural Networks (CNNs) and Euclidean MDM classifiers. Our results indicate that the Riemannian geometry-based classification not only achieves a superior mean F1 macro-averaged score across different channel configurations but also requires up to two orders of magnitude less computational training time. Additionally, the geometric framework reveals distinct spatial contributions of brain regions across varying brain states, suggesting a state-dependent organization that traditional time series-based methods often fail to capture. Our findings align with previous studies supporting the efficacy of geometry-based methods and extending their application to invasive brain recordings, highlighting their potential for broader clinical use, such as brain computer interface applications.
Drift to Remember
Sep 21, 2024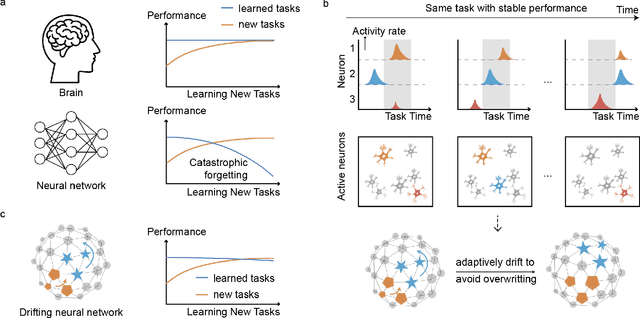
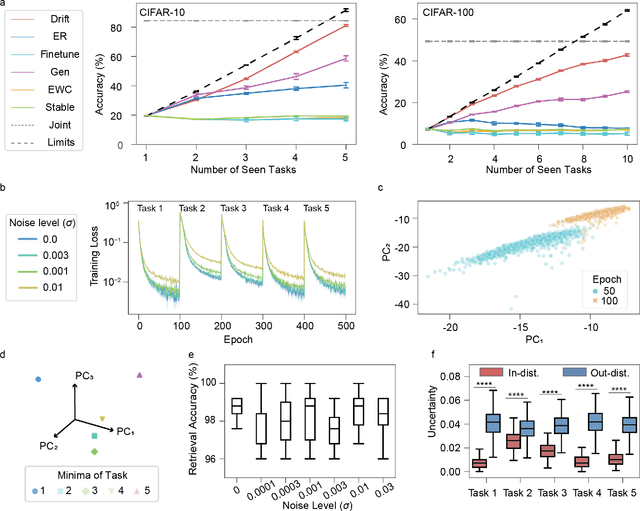
Lifelong learning in artificial intelligence (AI) aims to mimic the biological brain's ability to continuously learn and retain knowledge, yet it faces challenges such as catastrophic forgetting. Recent neuroscience research suggests that neural activity in biological systems undergoes representational drift, where neural responses evolve over time, even with consistent inputs and tasks. We hypothesize that representational drift can alleviate catastrophic forgetting in AI during new task acquisition. To test this, we introduce DriftNet, a network designed to constantly explore various local minima in the loss landscape while dynamically retrieving relevant tasks. This approach ensures efficient integration of new information and preserves existing knowledge. Experimental studies in image classification and natural language processing demonstrate that DriftNet outperforms existing models in lifelong learning. Importantly, DriftNet is scalable in handling a sequence of tasks such as sentiment analysis and question answering using large language models (LLMs) with billions of parameters on a single Nvidia A100 GPU. DriftNet efficiently updates LLMs using only new data, avoiding the need for full dataset retraining. Tested on GPT-2 and RoBERTa, DriftNet is a robust, cost-effective solution for lifelong learning in LLMs. This study not only advances AI systems to emulate biological learning, but also provides insights into the adaptive mechanisms of biological neural systems, deepening our understanding of lifelong learning in nature.
Self-Convinced Prompting: Few-Shot Question Answering with Repeated Introspection
Oct 10, 2023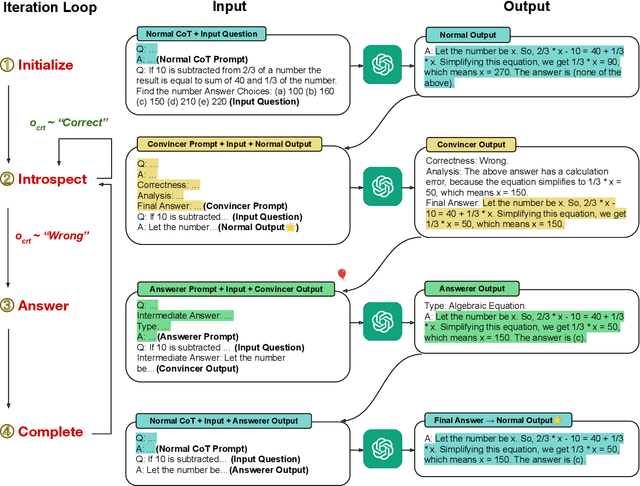
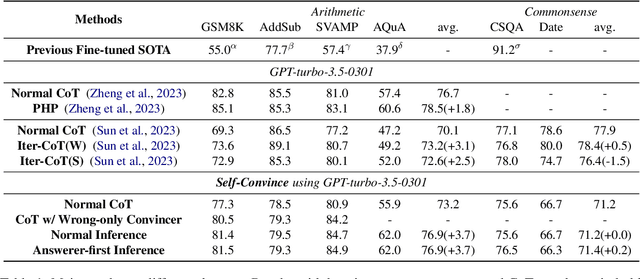
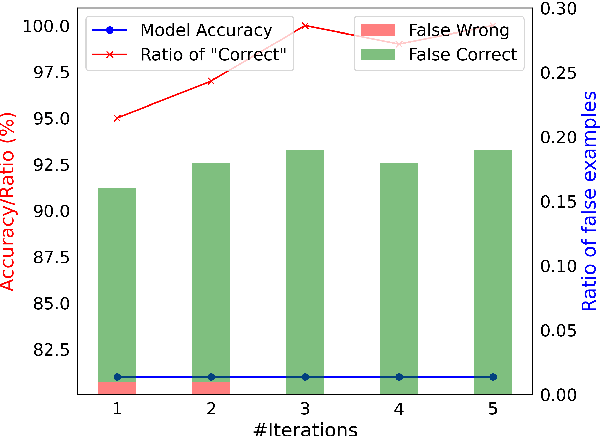
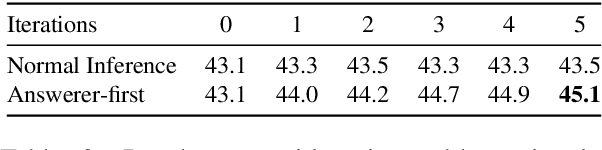
While large language models (LLMs) such as ChatGPT and PaLM have demonstrated remarkable performance in various language understanding and generation tasks, their capabilities in complex reasoning and intricate knowledge utilization still fall short of human-level proficiency. Recent studies have established the effectiveness of prompts in steering LLMs towards generating desired outputs. Building on these insights, we introduce a novel framework that harnesses the potential of large-scale pre-trained language models, to iteratively enhance performance of the LLMs. Our framework incorporates three components: \textit{Normal CoT}, a \textit{Convincer}, and an \textit{Answerer}. It processes the output of a typical few-shot chain-of-thought prompt, assesses the correctness of the response, scrutinizes the answer, refines the reasoning, and ultimately produces a new solution. Experimental results on the 7 datasets of miscellaneous problems validate the efficacy of the Self-Convince framework, achieving substantial improvements compared to the baselines. This study contributes to the burgeoning body of research focused on integrating pre-trained language models with tailored prompts and iterative refinement processes to augment their performance in complex tasks.