 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction Assessment: A Framework for Conditional Coverage Evaluation and Selection
Mar 28, 2026Conformal prediction provides rigorous distribution-free finite-sample guarantees for marginal coverage under the assumption of exchangeability, but may exhibit systematic undercoverage or overcoverage for specific subpopulations. Assessing conditional validity is challenging, as standard stratification methods suffer from the curse of dimensionality. We propose Conformal Prediction Assessment (CPA), a framework that reframes the evaluation of conditional coverage as a supervised learning task by training a reliability estimator that predicts instance-level coverage probabilities. Building on this estimator, we introduce the Conditional Validity Index (CVI), which decomposes reliability into safety (undercoverage risk) and efficiency (overcoverage cost). We establish convergence rates for the reliability estimator and prove the consistency of CVI-based model selection. Extensive experiments on synthetic and real-world datasets demonstrate that CPA effectively diagnoses local failure modes and that CC-Select, our CVI-based model selection algorithm, consistently identifies predictors with superior conditional coverage performance.
Tutor-Student Reinforcement Learning: A Dynamic Curriculum for Robust Deepfake Detection
Mar 25, 2026Standard supervised training for deepfake detection treats all samples with uniform importance, which can be suboptimal for learning robust and generalizable features. In this work, we propose a novel Tutor-Student Reinforcement Learning (TSRL) framework to dynamically optimize the training curriculum. Our method models the training process as a Markov Decision Process where a ``Tutor'' agent learns to guide a ``Student'' (the deepfake detector). The Tutor, implemented as a Proximal Policy Optimization (PPO) agent, observes a rich state representation for each training sample, encapsulating not only its visual features but also its historical learning dynamics, such as EMA loss and forgetting counts. Based on this state, the Tutor takes an action by assigning a continuous weight (0-1) to the sample's loss, thereby dynamically re-weighting the training batch. The Tutor is rewarded based on the Student's immediate performance change, specifically rewarding transitions from incorrect to correct predictions. This strategy encourages the Tutor to learn a curriculum that prioritizes high-value samples, such as hard-but-learnable examples, leading to a more efficient and effective training process. We demonstrate that this adaptive curriculum improves the Student's generalization capabilities against unseen manipulation techniques compared to traditional training methods. Code is available at https://github.com/wannac1/TSRL.
* Accepted to CVPR 2026
DeformTrace: A Deformable State Space Model with Relay Tokens for Temporal Forgery Localization
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments in video and audio, offering strong interpretability for security and forensics. While recent State Space Models (SSMs) show promise in precise temporal reasoning, their use in TFL is hindered by ambiguous boundaries, sparse forgeries, and limited long-range modeling. We propose DeformTrace, which enhances SSMs with deformable dynamics and relay mechanisms to address these challenges. Specifically, Deformable Self-SSM (DS-SSM) introduces dynamic receptive fields into SSMs for precise temporal localization. To further enhance its capacity for temporal reasoning and mitigate long-range decay, a Relay Token Mechanism is integrated into DS-SSM. Besides, Deformable Cross-SSM (DC-SSM) partitions the global state space into query-specific subspaces, reducing non-forgery information accumulation and boosting sensitivity to sparse forgeries. These components are integrated into a hybrid architecture that combines the global modeling of Transformers with the efficiency of SSMs. Extensive experiments show that DeformTrace achieves state-of-the-art performance with fewer parameters, faster inference, and stronger robustness.
GEM-TFL: Bridging Weak and Full Supervision for Forgery Localization through EM-Guided Decomposition and Temporal Refinement
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments within videos or audio streams, providing interpretable evidence for multimedia forensics and security. While most existing TFL methods rely on dense frame-level labels in a fully supervised manner, Weakly Supervised TFL (WS-TFL) reduces labeling cost by learning only from binary video-level labels. However, current WS-TFL approaches suffer from mismatched training and inference objectives, limited supervision from binary labels, gradient blockage caused by non-differentiable top-k aggregation, and the absence of explicit modeling of inter-proposal relationships. To address these issues, we propose GEM-TFL (Graph-based EM-powered Temporal Forgery Localization), a two-phase classification-regression framework that effectively bridges the supervision gap between training and inference. Built upon this foundation, (1) we enhance weak supervision by reformulating binary labels into multi-dimensional latent attributes through an EM-based optimization process; (2) we introduce a training-free temporal consistency refinement that realigns frame-level predictions for smoother temporal dynamics; and (3) we design a graph-based proposal refinement module that models temporal-semantic relationships among proposals for globally consistent confidence estimation. Extensive experiments on benchmark datasets demonstrate that GEM-TFL achieves more accurate and robust temporal forgery localization, substantially narrowing the gap with fully supervised methods.
On damage of interpolation to adversarial robustness in regression
Jan 22, 2026Deep neural networks (DNNs) typically involve a large number of parameters and are trained to achieve zero or near-zero training error. Despite such interpolation, they often exhibit strong generalization performance on unseen data, a phenomenon that has motivated extensive theoretical investigations. Comforting results show that interpolation indeed may not affect the minimax rate of convergence under the squared error loss. In the mean time, DNNs are well known to be highly vulnerable to adversarial perturbations in future inputs. A natural question then arises: Can interpolation also escape from suboptimal performance under a future $X$-attack? In this paper, we investigate the adversarial robustness of interpolating estimators in a framework of nonparametric regression. A finding is that interpolating estimators must be suboptimal even under a subtle future $X$-attack, and achieving perfect fitting can substantially damage their robustness. An interesting phenomenon in the high interpolation regime, which we term the curse of simple size, is also revealed and discussed. Numerical experiments support our theoretical findings.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
RayFlow: Instance-Aware Diffusion Acceleration via Adaptive Flow Trajectories
Mar 10, 2025



Diffusion models have achieved remarkable success across various domains. However, their slow generation speed remains a critical challenge. Existing acceleration methods, while aiming to reduce steps, often compromise sample quality, controllability, or introduce training complexities. Therefore, we propose RayFlow, a novel diffusion framework that addresses these limitations. Unlike previous methods, RayFlow guides each sample along a unique path towards an instance-specific target distribution. This method minimizes sampling steps while preserving generation diversity and stability. Furthermore, we introduce Time Sampler, an importance sampling technique to enhance training efficiency by focusing on crucial timesteps. Extensive experiments demonstrate RayFlow's superiority in generating high-quality images with improved speed, control, and training efficiency compared to existing acceleration techniques.
Improving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Feb 22, 2025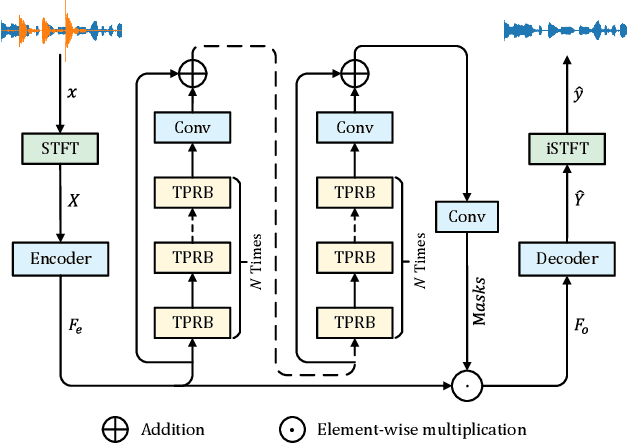
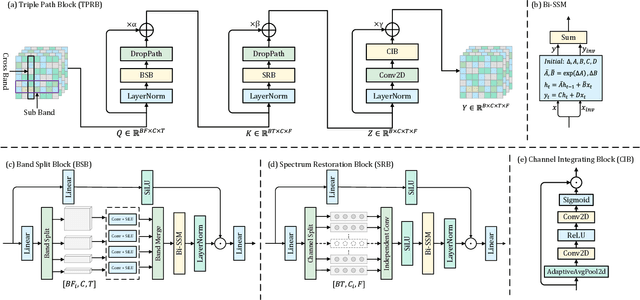

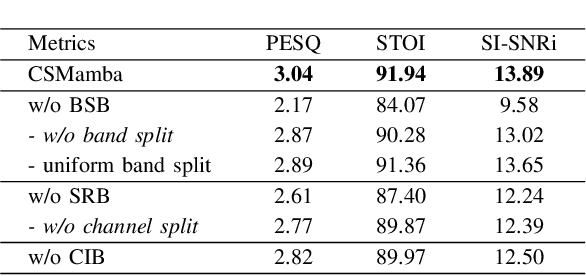
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.
Model Privacy: A Unified Framework to Understand Model Stealing Attacks and Defenses
Feb 21, 2025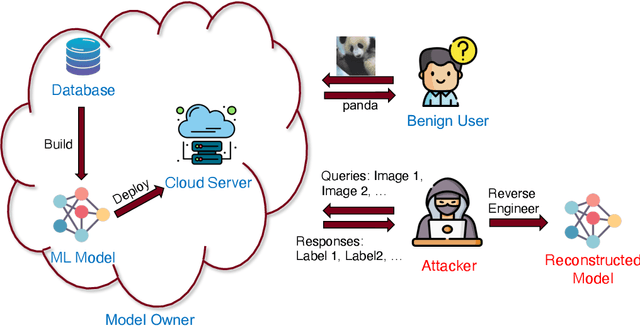

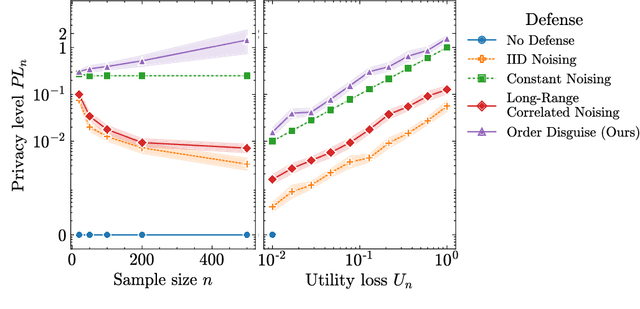
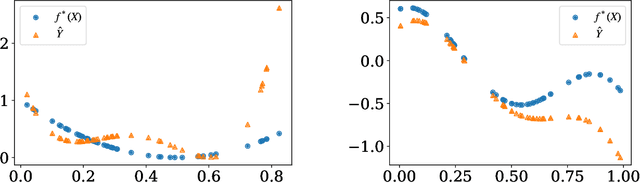
The use of machine learning (ML) has become increasingly prevalent in various domains, highlighting the importance of understanding and ensuring its safety. One pressing concern is the vulnerability of ML applications to model stealing attacks. These attacks involve adversaries attempting to recover a learned model through limited query-response interactions, such as those found in cloud-based services or on-chip artificial intelligence interfaces. While existing literature proposes various attack and defense strategies, these often lack a theoretical foundation and standardized evaluation criteria. In response, this work presents a framework called ``Model Privacy'', providing a foundation for comprehensively analyzing model stealing attacks and defenses. We establish a rigorous formulation for the threat model and objectives, propose methods to quantify the goodness of attack and defense strategies, and analyze the fundamental tradeoffs between utility and privacy in ML models. Our developed theory offers valuable insights into enhancing the security of ML models, especially highlighting the importance of the attack-specific structure of perturbations for effective defenses. We demonstrate the application of model privacy from the defender's perspective through various learning scenarios. Extensive experiments corroborate the insights and the effectiveness of defense mechanisms developed under the proposed framework.
FreeCodec: A disentangled neural speech codec with fewer tokens
Dec 02, 2024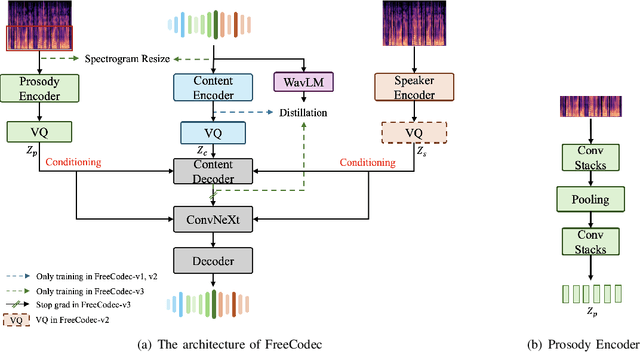
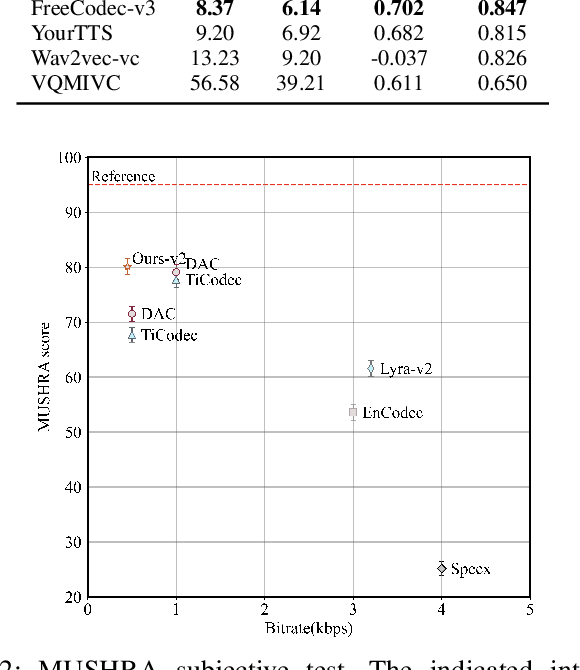
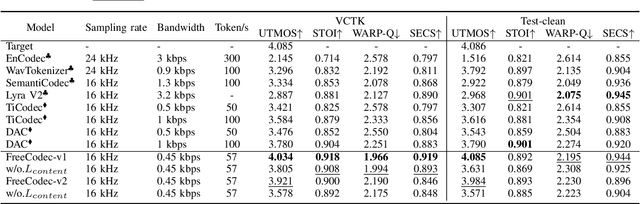
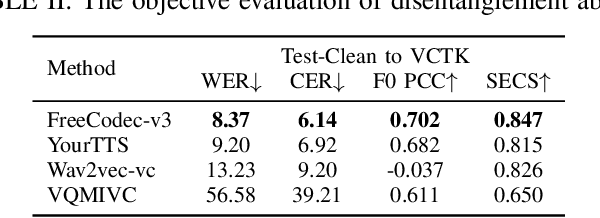
Neural speech codecs have gained great attention for their outstanding reconstruction with discrete token representations. It is a crucial component in generative tasks such as speech coding and large language models (LLM). However, most works based on residual vector quantization perform worse with fewer tokens due to low coding efficiency for modeling complex coupled information. In this paper, we propose a neural speech codec named FreeCodec which employs a more effective encoding framework by decomposing intrinsic properties of speech into different components: 1) a global vector is extracted as the timbre information, 2) a prosody encoder with a long stride level is used to model the prosody information, 3) the content information is from a content encoder. Using different training strategies, FreeCodec achieves state-of-the-art performance in reconstruction and disentanglement scenarios. Results from subjective and objective experiments demonstrate that our framework outperforms existing methods.