 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
OrchMLLM: Orchestrate Multimodal Data with Batch Post-Balancing to Accelerate Multimodal Large Language Model Training
Mar 31, 2025Multimodal large language models (MLLMs), such as GPT-4o, are garnering significant attention. During the exploration of MLLM training, we identified Modality Composition Incoherence, a phenomenon that the proportion of a certain modality varies dramatically across different examples. It exacerbates the challenges of addressing mini-batch imbalances, which lead to uneven GPU utilization between Data Parallel (DP) instances and severely degrades the efficiency and scalability of MLLM training, ultimately affecting training speed and hindering further research on MLLMs. To address these challenges, we introduce OrchMLLM, a comprehensive framework designed to mitigate the inefficiencies in MLLM training caused by Modality Composition Incoherence. First, we propose Batch Post-Balancing Dispatcher, a technique that efficiently eliminates mini-batch imbalances in sequential data. Additionally, we integrate MLLM Global Orchestrator into the training framework to orchestrate multimodal data and tackle the issues arising from Modality Composition Incoherence. We evaluate OrchMLLM across various MLLM sizes, demonstrating its efficiency and scalability. Experimental results reveal that OrchMLLM achieves a Model FLOPs Utilization (MFU) of $41.6\%$ when training an 84B MLLM with three modalities on $2560$ H100 GPUs, outperforming Megatron-LM by up to $3.1\times$ in throughput.
Data-Centric and Heterogeneity-Adaptive Sequence Parallelism for Efficient LLM Training
Dec 02, 2024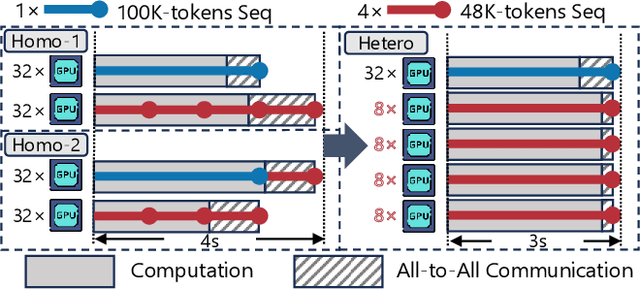
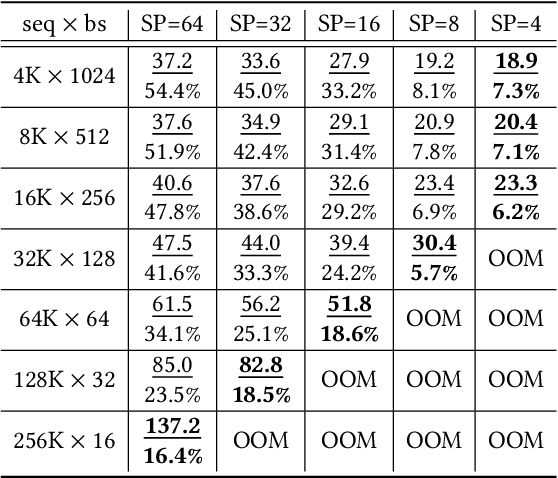
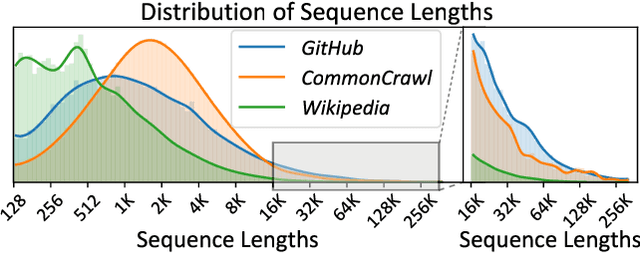

Extending the context length (i.e., the maximum supported sequence length) of LLMs is of paramount significance. To facilitate long context training of LLMs, sequence parallelism has emerged as an essential technique, which scatters each input sequence across multiple devices and necessitates communication to process the sequence. In essence, existing sequence parallelism methods assume homogeneous sequence lengths (i.e., all input sequences are equal in length) and therefore leverages a single, static scattering strategy for all input sequences. However, in reality, the sequence lengths in LLM training corpora exhibit substantial variability, often following a long-tail distribution, which leads to workload heterogeneity. In this paper, we show that employing a single, static strategy results in inefficiency and resource under-utilization, highlighting the need for adaptive approaches to handle the heterogeneous workloads across sequences. To address this, we propose a heterogeneity-adaptive sequence parallelism method. For each training step, our approach captures the variability in sequence lengths and assigns the optimal combination of scattering strategies based on workload characteristics. We model this problem as a linear programming optimization and design an efficient and effective solver to find the optimal solution. Furthermore, we implement our method in a high-performance system that supports adaptive parallelization in distributed LLM training. Experimental results demonstrate that our system outperforms state-of-the-art training frameworks by up to 1.98x.