 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGamma: State-Dependent Discounting for Temporal Adaptation in Reinforcement Learning
May 07, 2026The discount factor in reinforcement learning controls both the effective planning horizon and the strength of bootstrapping, yet most deep RL methods use a single fixed value across all states. While state-dependent discounting is conceptually appealing, naive deep actor--critic implementations can become unstable and degenerate toward TD-error collapse. We propose AdaGamma, a practical deep actor--critic method for state-dependent discounting that learns a state-dependent discount function together with a return-consistency objective to regularize the induced backup structure. On the theory side, we analyze the Bellman operator induced by state-dependent discounting and establish its basic well-posedness properties under suitable conditions. Empirically, AdaGamma integrates into both SAC and PPO, yielding consistent improvements on continuous-control benchmarks, and achieves statistically significant gains in an online A/B test on the JD Logistics platform. These results suggest that state-dependent discounting can be made effective in deep RL when coupled with a return-consistency objective that prevents degenerate target manipulation.
Opportunistic Bone-Loss Screening from Routine Knee Radiographs Using a Multi-Task Deep Learning Framework with Sensitivity-Constrained Threshold Optimization
Apr 22, 2026Background: Osteoporosis and osteopenia are often undiagnosed until fragility fractures occur. Dual-energy X-ray absorptiometry (DXA) is the reference standard for bone mineral density (BMD) assessment, but access remains limited. Knee radiographs are obtained at high volume for osteoarthritis evaluation and may offer an opportunity for opportunistic bone-loss screening. Objective: To develop and evaluate a multi-task deep learning system for opportunistic bone-loss screening from routine knee radiographs without additional imaging or patient visits. Methods: We developed STR-Net, a multi-task framework for single-channel grayscale knee radiographs. The model includes a shared backbone, global average pooling feature aggregation, a shared neck, and a task-aware representation routing module connected to three task-specific heads: binary screening (Normal vs. Bone Loss), severity sub-classification (Osteopenia vs. Osteoporosis), and weakly coupled T-score regression with optional clinical variables. A sensitivity-constrained threshold optimization strategy (minimum sensitivity >= 0.86) was applied. The dataset included 1,570 knee radiographs, split at the patient level into training (n=1,120), validation (n=226), and test (n=224) sets. Results: On the held-out test set, STR-Net achieved an AUROC of 0.933, sensitivity of 0.904, specificity of 0.773, and AUPRC of 0.956 for binary screening. Severity sub-classification achieved an AUROC of 0.898. The T-score regression branch showed a Pearson correlation of 0.801 with DXA-measured T-scores in a pilot subset (n=31), with MAE of 0.279 and RMSE of 0.347. Conclusions: STR-Net enables single-pass bone-loss screening, severity stratification, and quantitative T-score estimation from routine knee radiographs. Prospective clinical validation is needed before deployment.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
AGE-Net: Spectral--Spatial Fusion and Anatomical Graph Reasoning with Evidential Ordinal Regression for Knee Osteoarthritis Grading
Jan 24, 2026Automated Kellgren--Lawrence (KL) grading from knee radiographs is challenging due to subtle structural changes, long-range anatomical dependencies, and ambiguity near grade boundaries. We propose AGE-Net, a ConvNeXt-based framework that integrates Spectral--Spatial Fusion (SSF), Anatomical Graph Reasoning (AGR), and Differential Refinement (DFR). To capture predictive uncertainty and preserve label ordinality, AGE-Net employs a Normal-Inverse-Gamma (NIG) evidential regression head and a pairwise ordinal ranking constraint. On a knee KL dataset, AGE-Net achieves a quadratic weighted kappa (QWK) of 0.9017 +/- 0.0045 and a mean squared error (MSE) of 0.2349 +/- 0.0028 over three random seeds, outperforming strong CNN baselines and showing consistent gains in ablation studies. We further outline evaluations of uncertainty quality, robustness, and explainability, with additional experimental figures to be included in the full manuscript.
ClinNet: Evidential Ordinal Regression with Bilateral Asymmetry and Prototype Memory for Knee Osteoarthritis Grading
Jan 24, 2026Knee osteoarthritis (KOA) grading based on radiographic images is a critical yet challenging task due to subtle inter-grade differences, annotation uncertainty, and the inherently ordinal nature of disease progression. Conventional deep learning approaches typically formulate this problem as deterministic multi-class classification, ignoring both the continuous progression of degeneration and the uncertainty in expert annotations. In this work, we propose ClinNet, a novel trustworthy framework that addresses KOA grading as an evidential ordinal regression problem. The proposed method integrates three key components: (1) a Bilateral Asymmetry Encoder (BAE) that explicitly models medial-lateral structural discrepancies; (2) a Diagnostic Memory Bank that maintains class-wise prototypes to stabilize feature representations; and (3) an Evidential Ordinal Head based on the Normal-Inverse-Gamma (NIG) distribution to jointly estimate continuous KL grades and epistemic uncertainty. Extensive experiments demonstrate that ClinNet achieves a Quadratic Weighted Kappa of 0.892 and Accuracy of 0.768, statistically outperforming state-of-the-art baselines (p < 0.001). Crucially, we demonstrate that the model's uncertainty estimates successfully flag out-of-distribution samples and potential misdiagnoses, paving the way for safe clinical deployment.
Codebook Design for Limited Feedback in Near-Field XL-MIMO Systems
Jan 15, 2026In this paper, we study efficient codebook design for limited feedback in extremely large-scale multiple-input-multiple-output (XL-MIMO) frequency division duplexing (FDD) systems. It is worth noting that existing codebook designs for XL-MIMO, such as polar-domain codebook, have not well taken into account user (location) distribution in practice, thereby incurring excessive feedback overhead. To address this issue, we propose in this paper a novel and efficient feedback codebook tailored to user distribution. To this end, we first consider a typical scenario where users are uniformly distributed within a specific polar-region, based on which a sum-rate maximization problem is formulated to jointly optimize angle-range samples and bit allocation among angle/range feedback. This problem is challenging to solve due to the lack of a closed-form expression for the received power in terms of angle and range samples. By leveraging a Voronoi partitioning approach, we show that uniform angle sampling is optimal for received power maximization. For more challenging range sampling design, we obtain a tight lower-bound on the received power and show that geometric sampling, where the ratio between adjacent samples is constant, can maximize the lower bound and thus serves as a high-quality suboptimal solution. We then extend the proposed framework to accommodate more general non-uniform user distribution via an alternating sampling method. Furthermore, theoretical analysis reveals that as the array size increases, the optimal allocation of feedback bits increasingly favors range samples at the expense of angle samples. Finally, numerical results validate the superior rate performance and robustness of the proposed codebook design under various system setups, achieving significant gains over benchmark schemes, including the widely used polar-domain codebook.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Distinguishing Visually Similar Actions: Prompt-Guided Semantic Prototype Modulation for Few-Shot Action Recognition
Dec 22, 2025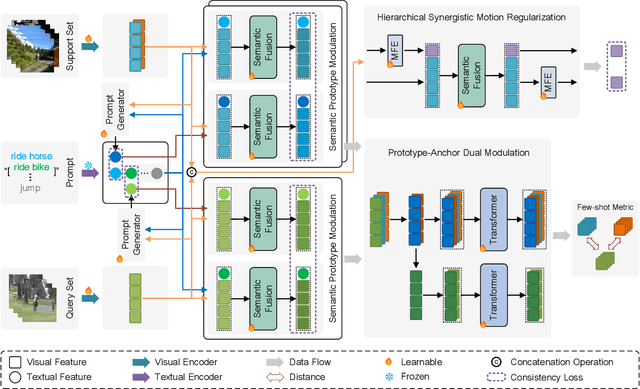
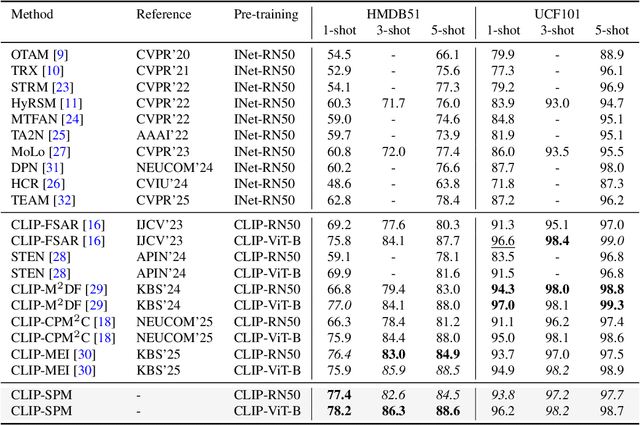
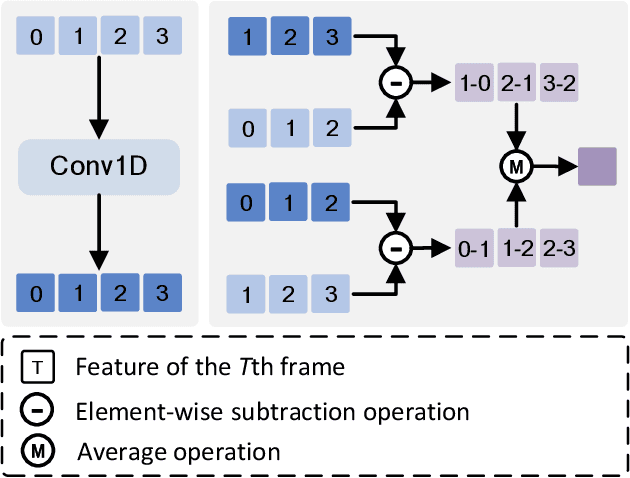
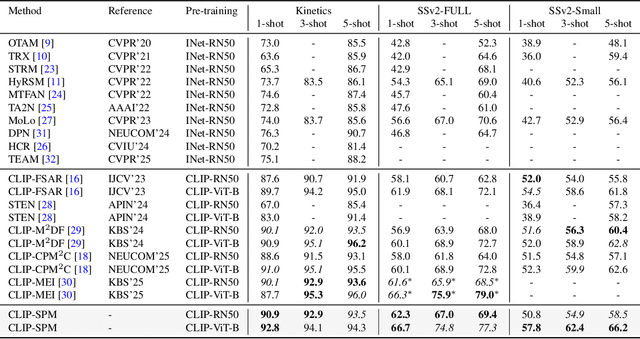
Few-shot action recognition aims to enable models to quickly learn new action categories from limited labeled samples, addressing the challenge of data scarcity in real-world applications. Current research primarily addresses three core challenges: (1) temporal modeling, where models are prone to interference from irrelevant static background information and struggle to capture the essence of dynamic action features; (2) visual similarity, where categories with subtle visual differences are difficult to distinguish; and (3) the modality gap between visual-textual support prototypes and visual-only queries, which complicates alignment within a shared embedding space. To address these challenges, this paper proposes a CLIP-SPM framework, which includes three components: (1) the Hierarchical Synergistic Motion Refinement (HSMR) module, which aligns deep and shallow motion features to improve temporal modeling by reducing static background interference; (2) the Semantic Prototype Modulation (SPM) strategy, which generates query-relevant text prompts to bridge the modality gap and integrates them with visual features, enhancing the discriminability between similar actions; and (3) the Prototype-Anchor Dual Modulation (PADM) method, which refines support prototypes and aligns query features with a global semantic anchor, improving consistency across support and query samples. Comprehensive experiments across standard benchmarks, including Kinetics, SSv2-Full, SSv2-Small, UCF101, and HMDB51, demonstrate that our CLIP-SPM achieves competitive performance under 1-shot, 3-shot, and 5-shot settings. Extensive ablation studies and visual analyses further validate the effectiveness of each component and its contributions to addressing the core challenges. The source code and models are publicly available at GitHub.
Context-Aware Network Based on Multi-scale Spatio-temporal Attention for Action Recognition in Videos
Dec 21, 2025Action recognition is a critical task in video understanding, requiring the comprehensive capture of spatio-temporal cues across various scales. However, existing methods often overlook the multi-granularity nature of actions. To address this limitation, we introduce the Context-Aware Network (CAN). CAN consists of two core modules: the Multi-scale Temporal Cue Module (MTCM) and the Group Spatial Cue Module (GSCM). MTCM effectively extracts temporal cues at multiple scales, capturing both fast-changing motion details and overall action flow. GSCM, on the other hand, extracts spatial cues at different scales by grouping feature maps and applying specialized extraction methods to each group. Experiments conducted on five benchmark datasets (Something-Something V1 and V2, Diving48, Kinetics-400, and UCF101) demonstrate the effectiveness of CAN. Our approach achieves competitive performance, outperforming most mainstream methods, with accuracies of 50.4% on Something-Something V1, 63.9% on Something-Something V2, 88.4% on Diving48, 74.9% on Kinetics-400, and 86.9% on UCF101. These results highlight the importance of capturing multi-scale spatio-temporal cues for robust action recognition.