 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass-Thinker-7B Technical Report
Aug 12, 2025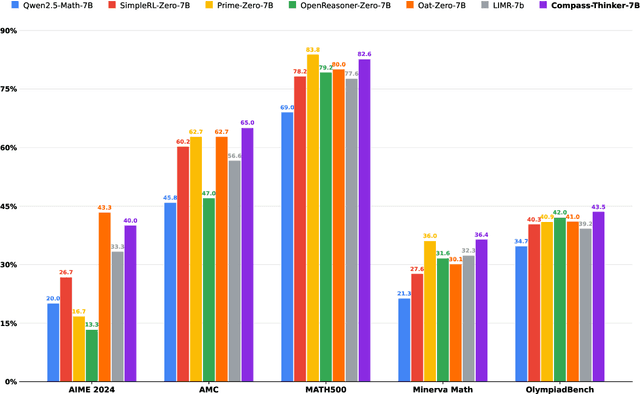

Recent R1-Zero-like research further demonstrates that reasoning extension has given large language models (LLMs) unprecedented reasoning capabilities, and Reinforcement Learning is the core technology to elicit its complex reasoning. However, conducting RL experiments directly on hyperscale models involves high computational costs and resource demands, posing significant risks. We propose the Compass-Thinker-7B model, which aims to explore the potential of Reinforcement Learning with less computational resources and costs, and provides insights for further research into RL recipes for larger models. Compass-Thinker-7B is trained from an open source model through a specially designed Reinforcement Learning Pipeline. we curate a dataset of 30k verifiable mathematics problems for the Reinforcement Learning Pipeline. By configuring data and training settings with different difficulty distributions for different stages, the potential of the model is gradually released and the training efficiency is improved. Extensive evaluations show that Compass-Thinker-7B possesses exceptional reasoning potential, and achieves superior performance on mathematics compared to the same-sized RL model.Especially in the challenging AIME2024 evaluation, Compass-Thinker-7B achieves 40% accuracy.
Adaptive Dense Reward: Understanding the Gap Between Action and Reward Space in Alignment
Oct 23, 2024
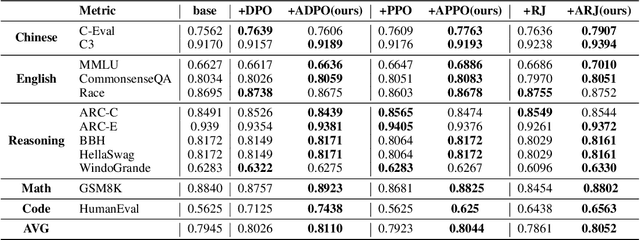
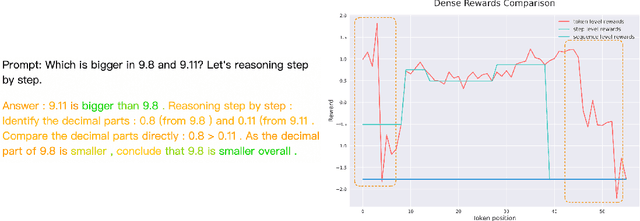
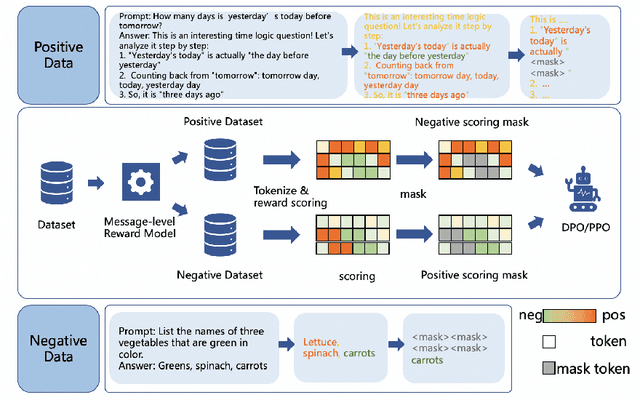
Reinforcement Learning from Human Feedback (RLHF) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. However, the original RLHF typically optimizes under an overall reward, which can lead to a suboptimal learning process. This limitation stems from RLHF's lack of awareness regarding which specific tokens should be reinforced or suppressed. Moreover, conflicts in supervision can arise, for instance, when a chosen response includes erroneous tokens, while a rejected response contains accurate elements. To rectify these shortcomings, increasing dense reward methods, such as step-wise and token-wise RLHF, have been proposed. However, these existing methods are limited to specific tasks (like mathematics). In this paper, we propose the ``Adaptive Message-wise RLHF'' method, which robustly applies to various tasks. By defining pivot tokens as key indicators, our approach adaptively identifies essential information and converts sample-level supervision into fine-grained, subsequence-level supervision. This aligns the density of rewards and action spaces more closely with the information density of the input. Experiments demonstrate that our method can be integrated into various training methods, significantly mitigating hallucinations and catastrophic forgetting problems while outperforming other methods on multiple evaluation metrics. Our method improves the success rate on adversarial samples by 10\% compared to the sample-wise approach and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, and HumanEval et al.
Synthesizing Tensor Transformations for Visual Self-attention
Jan 05, 2022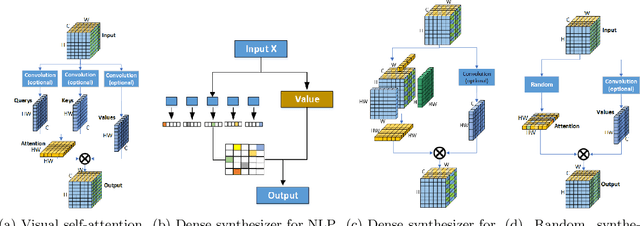
Self-attention shows outstanding competence in capturing long-range relationships while enhancing performance on vision tasks, such as image classification and image captioning. However, the self-attention module highly relies on the dot product multiplication and dimension alignment among query-key-value features, which cause two problems: (1) The dot product multiplication results in exhaustive and redundant computation. (2) Due to the visual feature map often appearing as a multi-dimensional tensor, reshaping the scale of the tensor feature to adapt to the dimension alignment might destroy the internal structure of the tensor feature map. To address these problems, this paper proposes a self-attention plug-in module with its variants, namely, Synthesizing Tensor Transformations (STT), for directly processing image tensor features. Without computing the dot-product multiplication among query-key-value, the basic STT is composed of the tensor transformation to learn the synthetic attention weight from visual information. The effectiveness of STT series is validated on the image classification and image caption. Experiments show that the proposed STT achieves competitive performance while keeping robustness compared to self-attention based above vision tasks.
Learning Robust and Lightweight Model through Separable Structured Transformations
Dec 29, 2021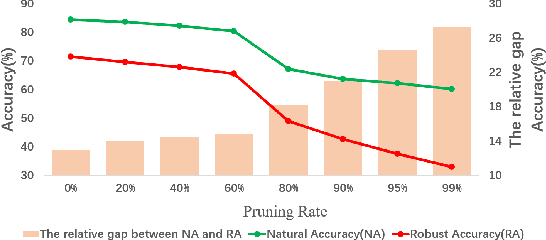

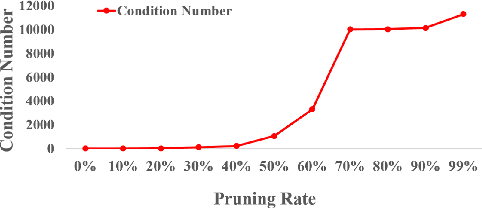
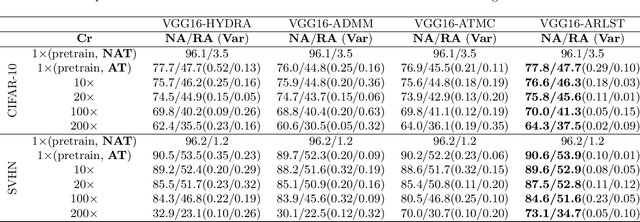
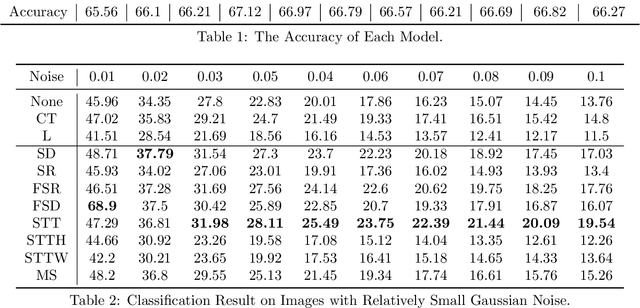
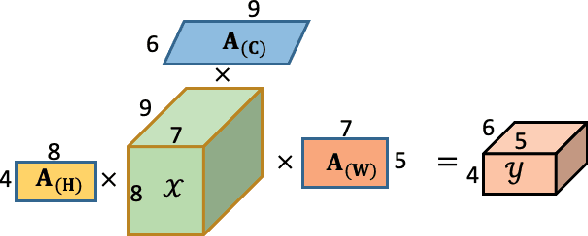
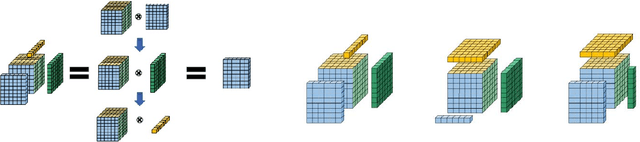
With the proliferation of mobile devices and the Internet of Things, deep learning models are increasingly deployed on devices with limited computing resources and memory, and are exposed to the threat of adversarial noise. Learning deep models with both lightweight and robustness is necessary for these equipments. However, current deep learning solutions are difficult to learn a model that possesses these two properties without degrading one or the other. As is well known, the fully-connected layers contribute most of the parameters of convolutional neural networks. We perform a separable structural transformation of the fully-connected layer to reduce the parameters, where the large-scale weight matrix of the fully-connected layer is decoupled by the tensor product of several separable small-sized matrices. Note that data, such as images, no longer need to be flattened before being fed to the fully-connected layer, retaining the valuable spatial geometric information of the data. Moreover, in order to further enhance both lightweight and robustness, we propose a joint constraint of sparsity and differentiable condition number, which is imposed on these separable matrices. We evaluate the proposed approach on MLP, VGG-16 and Vision Transformer. The experimental results on datasets such as ImageNet, SVHN, CIFAR-100 and CIFAR10 show that we successfully reduce the amount of network parameters by 90%, while the robust accuracy loss is less than 1.5%, which is better than the SOTA methods based on the original fully-connected layer. Interestingly, it can achieve an overwhelming advantage even at a high compression rate, e.g., 200 times.