 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEach Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models
Feb 27, 2025
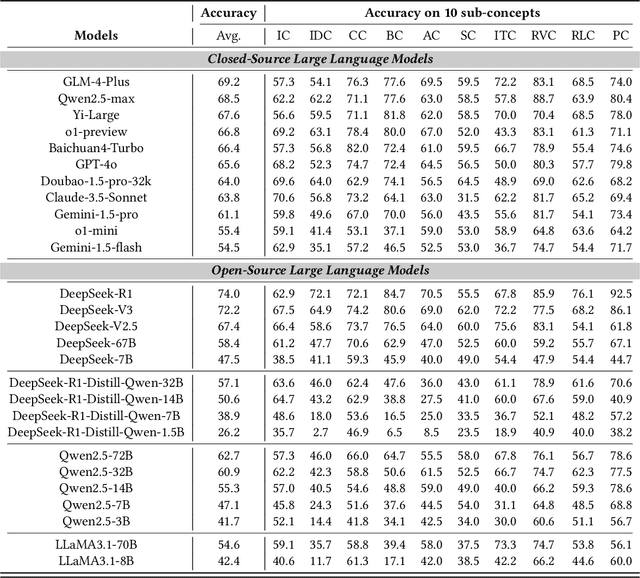
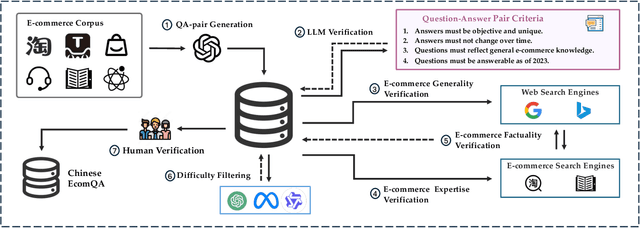

With the increasing use of Large Language Models (LLMs) in fields such as e-commerce, domain-specific concept evaluation benchmarks are crucial for assessing their domain capabilities. Existing LLMs may generate factually incorrect information within the complex e-commerce applications. Therefore, it is necessary to build an e-commerce concept benchmark. Existing benchmarks encounter two primary challenges: (1) handle the heterogeneous and diverse nature of tasks, (2) distinguish between generality and specificity within the e-commerce field. To address these problems, we propose \textbf{ChineseEcomQA}, a scalable question-answering benchmark focused on fundamental e-commerce concepts. ChineseEcomQA is built on three core characteristics: \textbf{Focus on Fundamental Concept}, \textbf{E-commerce Generality} and \textbf{E-commerce Expertise}. Fundamental concepts are designed to be applicable across a diverse array of e-commerce tasks, thus addressing the challenge of heterogeneity and diversity. Additionally, by carefully balancing generality and specificity, ChineseEcomQA effectively differentiates between broad e-commerce concepts, allowing for precise validation of domain capabilities. We achieve this through a scalable benchmark construction process that combines LLM validation, Retrieval-Augmented Generation (RAG) validation, and rigorous manual annotation. Based on ChineseEcomQA, we conduct extensive evaluations on mainstream LLMs and provide some valuable insights. We hope that ChineseEcomQA could guide future domain-specific evaluations, and facilitate broader LLM adoption in e-commerce applications.
Equilibrate RLHF: Towards Balancing Helpfulness-Safety Trade-off in Large Language Models
Feb 17, 2025Fine-tuning large language models (LLMs) based on human preferences, commonly achieved through reinforcement learning from human feedback (RLHF), has been effective in improving their performance. However, maintaining LLM safety throughout the fine-tuning process remains a significant challenge, as resolving conflicts between safety and helpfulness can be non-trivial. Typically, the safety alignment of LLM is trained on data with safety-related categories. However, our experiments find that naively increasing the scale of safety training data usually leads the LLMs to an ``overly safe'' state rather than a ``truly safe'' state, boosting the refusal rate through extensive safety-aligned data without genuinely understanding the requirements for safe responses. Such an approach can inadvertently diminish the models' helpfulness. To understand the phenomenon, we first investigate the role of safety data by categorizing them into three different groups, and observe that each group behaves differently as training data scales up. To boost the balance between safety and helpfulness, we propose an Equilibrate RLHF framework including a Fine-grained Data-centric (FDC) approach that achieves better safety alignment even with fewer training data, and an Adaptive Message-wise Alignment (AMA) approach, which selectively highlight the key segments through a gradient masking strategy. Extensive experimental results demonstrate that our approach significantly enhances the safety alignment of LLMs while balancing safety and helpfulness.
Adaptive Dense Reward: Understanding the Gap Between Action and Reward Space in Alignment
Oct 23, 2024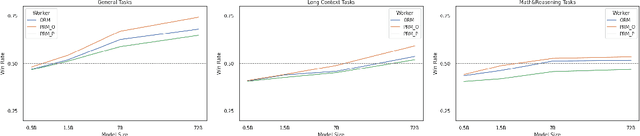
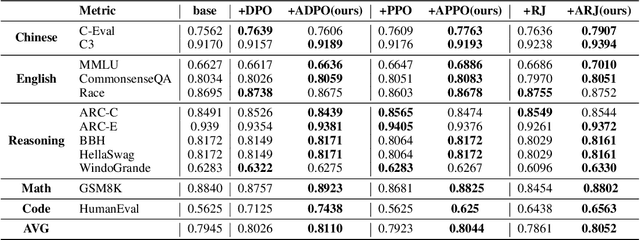
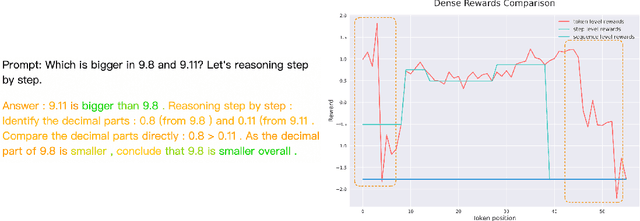
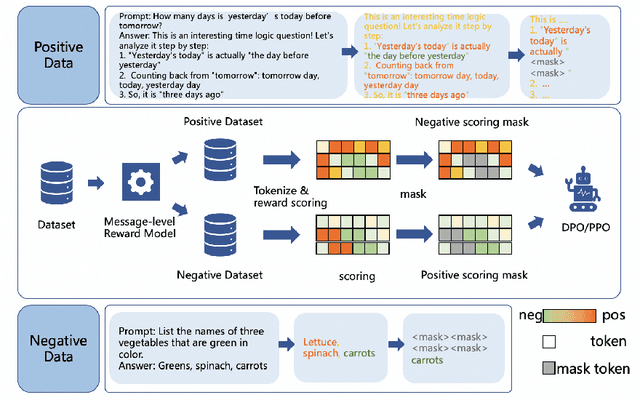
Reinforcement Learning from Human Feedback (RLHF) has proven highly effective in aligning Large Language Models (LLMs) with human preferences. However, the original RLHF typically optimizes under an overall reward, which can lead to a suboptimal learning process. This limitation stems from RLHF's lack of awareness regarding which specific tokens should be reinforced or suppressed. Moreover, conflicts in supervision can arise, for instance, when a chosen response includes erroneous tokens, while a rejected response contains accurate elements. To rectify these shortcomings, increasing dense reward methods, such as step-wise and token-wise RLHF, have been proposed. However, these existing methods are limited to specific tasks (like mathematics). In this paper, we propose the ``Adaptive Message-wise RLHF'' method, which robustly applies to various tasks. By defining pivot tokens as key indicators, our approach adaptively identifies essential information and converts sample-level supervision into fine-grained, subsequence-level supervision. This aligns the density of rewards and action spaces more closely with the information density of the input. Experiments demonstrate that our method can be integrated into various training methods, significantly mitigating hallucinations and catastrophic forgetting problems while outperforming other methods on multiple evaluation metrics. Our method improves the success rate on adversarial samples by 10\% compared to the sample-wise approach and achieves a 1.3\% improvement on evaluation benchmarks such as MMLU, GSM8K, and HumanEval et al.