 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrainRL: Alleviating Factuality Hallucination of Large Language Models at the Beginning
Feb 02, 2026Large language models (LLMs), despite their powerful capabilities, suffer from factual hallucinations where they generate verifiable falsehoods. We identify a root of this issue: the imbalanced data distribution in the pretraining corpus, which leads to a state of "low-probability truth" and "high-probability falsehood". Recent approaches, such as teaching models to say "I don't know" or post-hoc knowledge editing, either evade the problem or face catastrophic forgetting. To address this issue from its root, we propose \textbf{PretrainRL}, a novel framework that integrates reinforcement learning into the pretraining phase to consolidate factual knowledge. The core principle of PretrainRL is "\textbf{debiasing then learning}." It actively reshapes the model's probability distribution by down-weighting high-probability falsehoods, thereby making "room" for low-probability truths to be learned effectively. To enable this, we design an efficient negative sampling strategy to discover these high-probability falsehoods and introduce novel metrics to evaluate the model's probabilistic state concerning factual knowledge. Extensive experiments on three public benchmarks demonstrate that PretrainRL significantly alleviates factual hallucinations and outperforms state-of-the-art methods.
Data Distribution Matters: A Data-Centric Perspective on Context Compression for Large Language Model
Feb 02, 2026The deployment of Large Language Models (LLMs) in long-context scenarios is hindered by computational inefficiency and significant information redundancy. Although recent advancements have widely adopted context compression to address these challenges, existing research only focus on model-side improvements, the impact of the data distribution itself on context compression remains largely unexplored. To bridge this gap, we are the first to adopt a data-centric perspective to systematically investigate how data distribution impacts compression quality, including two dimensions: input data and intrinsic data (i.e., the model's internal pretrained knowledge). We evaluate the semantic integrity of compressed representations using an autoencoder-based framework to systematically investigate it. Our experimental results reveal that: (1) encoder-measured input entropy negatively correlates with compression quality, while decoder-measured entropy shows no significant relationship under a frozen-decoder setting; and (2) the gap between intrinsic data of the encoder and decoder significantly diminishes compression gains, which is hard to mitigate. Based on these findings, we further present practical guidelines to optimize compression gains.
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging
May 22, 2025Model merging offers a training-free alternative to multi-task learning by combining independently fine-tuned models into a unified one without access to raw data. However, existing approaches often rely on heuristics to determine the merging coefficients, limiting their scalability and generality. In this work, we revisit model merging through the lens of least-squares optimization and show that the optimal merging weights should scale with the amount of task-specific information encoded in each model. Based on this insight, we propose NAN, a simple yet effective method that estimates model merging coefficients via the inverse of parameter norm. NAN is training-free, plug-and-play, and applicable to a wide range of merging strategies. Extensive experiments on show that NAN consistently improves performance of baseline methods.
ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models
Feb 27, 2025
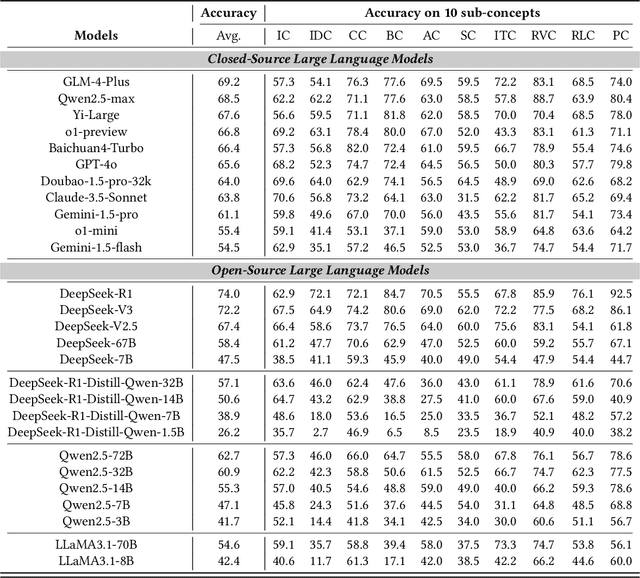
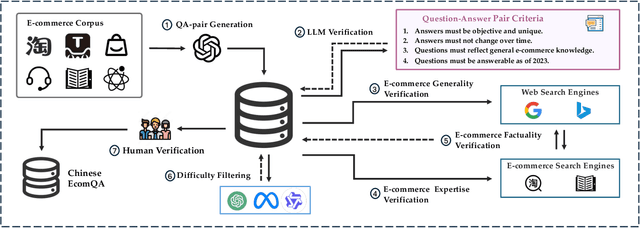

With the increasing use of Large Language Models (LLMs) in fields such as e-commerce, domain-specific concept evaluation benchmarks are crucial for assessing their domain capabilities. Existing LLMs may generate factually incorrect information within the complex e-commerce applications. Therefore, it is necessary to build an e-commerce concept benchmark. Existing benchmarks encounter two primary challenges: (1) handle the heterogeneous and diverse nature of tasks, (2) distinguish between generality and specificity within the e-commerce field. To address these problems, we propose \textbf{ChineseEcomQA}, a scalable question-answering benchmark focused on fundamental e-commerce concepts. ChineseEcomQA is built on three core characteristics: \textbf{Focus on Fundamental Concept}, \textbf{E-commerce Generality} and \textbf{E-commerce Expertise}. Fundamental concepts are designed to be applicable across a diverse array of e-commerce tasks, thus addressing the challenge of heterogeneity and diversity. Additionally, by carefully balancing generality and specificity, ChineseEcomQA effectively differentiates between broad e-commerce concepts, allowing for precise validation of domain capabilities. We achieve this through a scalable benchmark construction process that combines LLM validation, Retrieval-Augmented Generation (RAG) validation, and rigorous manual annotation. Based on ChineseEcomQA, we conduct extensive evaluations on mainstream LLMs and provide some valuable insights. We hope that ChineseEcomQA could guide future domain-specific evaluations, and facilitate broader LLM adoption in e-commerce applications.
Hyper Adversarial Tuning for Boosting Adversarial Robustness of Pretrained Large Vision Models
Oct 08, 2024



Large vision models have been found vulnerable to adversarial examples, emphasizing the need for enhancing their adversarial robustness. While adversarial training is an effective defense for deep convolutional models, it often faces scalability issues with large vision models due to high computational costs. Recent approaches propose robust fine-tuning methods, such as adversarial tuning of low-rank adaptation (LoRA) in large vision models, but they still struggle to match the accuracy of full parameter adversarial fine-tuning. The integration of various defense mechanisms offers a promising approach to enhancing the robustness of large vision models, yet this paradigm remains underexplored. To address this, we propose hyper adversarial tuning (HyperAT), which leverages shared defensive knowledge among different methods to improve model robustness efficiently and effectively simultaneously. Specifically, adversarial tuning of each defense method is formulated as a learning task, and a hypernetwork generates LoRA specific to this defense. Then, a random sampling and tuning strategy is proposed to extract and facilitate the defensive knowledge transfer between different defenses. Finally, diverse LoRAs are merged to enhance the adversarial robustness. Experiments on various datasets and model architectures demonstrate that HyperAT significantly enhances the adversarial robustness of pretrained large vision models without excessive computational overhead, establishing a new state-of-the-art benchmark.
HyperDet: Generalizable Detection of Synthesized Images by Generating and Merging A Mixture of Hyper LoRAs
Oct 08, 2024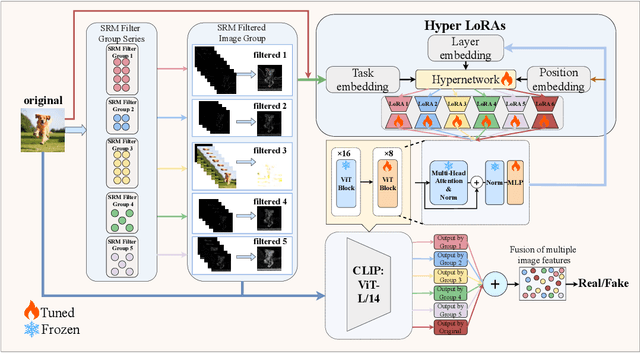



The emergence of diverse generative vision models has recently enabled the synthesis of visually realistic images, underscoring the critical need for effectively detecting these generated images from real photos. Despite advances in this field, existing detection approaches often struggle to accurately identify synthesized images generated by different generative models. In this work, we introduce a novel and generalizable detection framework termed HyperDet, which innovatively captures and integrates shared knowledge from a collection of functionally distinct and lightweight expert detectors. HyperDet leverages a large pretrained vision model to extract general detection features while simultaneously capturing and enhancing task-specific features. To achieve this, HyperDet first groups SRM filters into five distinct groups to efficiently capture varying levels of pixel artifacts based on their different functionality and complexity. Then, HyperDet utilizes a hypernetwork to generate LoRA model weights with distinct embedding parameters. Finally, we merge the LoRA networks to form an efficient model ensemble. Also, we propose a novel objective function that balances the pixel and semantic artifacts effectively. Extensive experiments on the UnivFD and Fake2M datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance. Moreover, our work paves a new way to establish generalizable domain-specific fake image detectors based on pretrained large vision models.