 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGER-LLM: Enhancing Large Language Models as Recommenders through Exogenous Behavior-Semantic Integration
Feb 20, 2025Large language models (LLMs) are increasingly leveraged as foundational backbones in the development of advanced recommender systems, offering enhanced capabilities through their extensive knowledge and reasoning. Existing llm-based recommender systems (RSs) often face challenges due to the significant differences between the linguistic semantics of pre-trained LLMs and the collaborative semantics essential for RSs. These systems use pre-trained linguistic semantics but learn collaborative semantics from scratch via the llm-Backbone. However, LLMs are not designed for recommendations, leading to inefficient collaborative learning, weak result correlations, and poor integration of traditional RS features. To address these challenges, we propose EAGER-LLM, a decoder-only llm-based generative recommendation framework that integrates endogenous and exogenous behavioral and semantic information in a non-intrusive manner. Specifically, we propose 1)dual-source knowledge-rich item indices that integrates indexing sequences for exogenous signals, enabling efficient link-wide processing; 2)non-invasive multiscale alignment reconstruction tasks guide the model toward a deeper understanding of both collaborative and semantic signals; 3)an annealing adapter designed to finely balance the model's recommendation performance with its comprehension capabilities. We demonstrate EAGER-LLM's effectiveness through rigorous testing on three public benchmarks.
Hyper Adversarial Tuning for Boosting Adversarial Robustness of Pretrained Large Vision Models
Oct 08, 2024



Large vision models have been found vulnerable to adversarial examples, emphasizing the need for enhancing their adversarial robustness. While adversarial training is an effective defense for deep convolutional models, it often faces scalability issues with large vision models due to high computational costs. Recent approaches propose robust fine-tuning methods, such as adversarial tuning of low-rank adaptation (LoRA) in large vision models, but they still struggle to match the accuracy of full parameter adversarial fine-tuning. The integration of various defense mechanisms offers a promising approach to enhancing the robustness of large vision models, yet this paradigm remains underexplored. To address this, we propose hyper adversarial tuning (HyperAT), which leverages shared defensive knowledge among different methods to improve model robustness efficiently and effectively simultaneously. Specifically, adversarial tuning of each defense method is formulated as a learning task, and a hypernetwork generates LoRA specific to this defense. Then, a random sampling and tuning strategy is proposed to extract and facilitate the defensive knowledge transfer between different defenses. Finally, diverse LoRAs are merged to enhance the adversarial robustness. Experiments on various datasets and model architectures demonstrate that HyperAT significantly enhances the adversarial robustness of pretrained large vision models without excessive computational overhead, establishing a new state-of-the-art benchmark.
HyperDet: Generalizable Detection of Synthesized Images by Generating and Merging A Mixture of Hyper LoRAs
Oct 08, 2024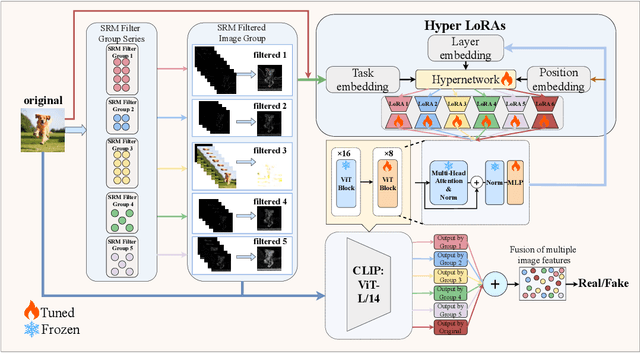



The emergence of diverse generative vision models has recently enabled the synthesis of visually realistic images, underscoring the critical need for effectively detecting these generated images from real photos. Despite advances in this field, existing detection approaches often struggle to accurately identify synthesized images generated by different generative models. In this work, we introduce a novel and generalizable detection framework termed HyperDet, which innovatively captures and integrates shared knowledge from a collection of functionally distinct and lightweight expert detectors. HyperDet leverages a large pretrained vision model to extract general detection features while simultaneously capturing and enhancing task-specific features. To achieve this, HyperDet first groups SRM filters into five distinct groups to efficiently capture varying levels of pixel artifacts based on their different functionality and complexity. Then, HyperDet utilizes a hypernetwork to generate LoRA model weights with distinct embedding parameters. Finally, we merge the LoRA networks to form an efficient model ensemble. Also, we propose a novel objective function that balances the pixel and semantic artifacts effectively. Extensive experiments on the UnivFD and Fake2M datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance. Moreover, our work paves a new way to establish generalizable domain-specific fake image detectors based on pretrained large vision models.
Norface: Improving Facial Expression Analysis by Identity Normalization
Jul 22, 2024



Facial Expression Analysis remains a challenging task due to unexpected task-irrelevant noise, such as identity, head pose, and background. To address this issue, this paper proposes a novel framework, called Norface, that is unified for both Action Unit (AU) analysis and Facial Emotion Recognition (FER) tasks. Norface consists of a normalization network and a classification network. First, the carefully designed normalization network struggles to directly remove the above task-irrelevant noise, by maintaining facial expression consistency but normalizing all original images to a common identity with consistent pose, and background. Then, these additional normalized images are fed into the classification network. Due to consistent identity and other factors (e.g. head pose, background, etc.), the normalized images enable the classification network to extract useful expression information more effectively. Additionally, the classification network incorporates a Mixture of Experts to refine the latent representation, including handling the input of facial representations and the output of multiple (AU or emotion) labels. Extensive experiments validate the carefully designed framework with the insight of identity normalization. The proposed method outperforms existing SOTA methods in multiple facial expression analysis tasks, including AU detection, AU intensity estimation, and FER tasks, as well as their cross-dataset tasks. For the normalized datasets and code please visit {https://norface-fea.github.io/}.
Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment
Apr 16, 2024A song is a combination of singing voice and accompaniment. However, existing works focus on singing voice synthesis and music generation independently. Little attention was paid to explore song synthesis. In this work, we propose a novel task called text-to-song synthesis which incorporating both vocals and accompaniments generation. We develop Melodist, a two-stage text-to-song method that consists of singing voice synthesis (SVS) and vocal-to-accompaniment (V2A) synthesis. Melodist leverages tri-tower contrastive pretraining to learn more effective text representation for controllable V2A synthesis. A Chinese song dataset mined from a music website is built up to alleviate data scarcity for our research. The evaluation results on our dataset demonstrate that Melodist can synthesize songs with comparable quality and style consistency. Audio samples can be found in https://text2songMelodist.github.io/Sample/.
FlowFace++: Explicit Semantic Flow-supervised End-to-End Face Swapping
Jun 26, 2023



This work proposes a novel face-swapping framework FlowFace++, utilizing explicit semantic flow supervision and end-to-end architecture to facilitate shape-aware face-swapping. Specifically, our work pretrains a facial shape discriminator to supervise the face swapping network. The discriminator is shape-aware and relies on a semantic flow-guided operation to explicitly calculate the shape discrepancies between the target and source faces, thus optimizing the face swapping network to generate highly realistic results. The face swapping network is a stack of a pre-trained face-masked autoencoder (MAE), a cross-attention fusion module, and a convolutional decoder. The MAE provides a fine-grained facial image representation space, which is unified for the target and source faces and thus facilitates final realistic results. The cross-attention fusion module carries out the source-to-target face swapping in a fine-grained latent space while preserving other attributes of the target image (e.g. expression, head pose, hair, background, illumination, etc). Lastly, the convolutional decoder further synthesizes the swapping results according to the face-swapping latent embedding from the cross-attention fusion module. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace++ outperforms the state-of-the-art significantly, particularly while the source face is obstructed by uneven lighting or angle offset.
DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
Mar 07, 2023



For few-shot learning, it is still a critical challenge to realize photo-realistic face visually dubbing on high-resolution videos. Previous works fail to generate high-fidelity dubbing results. To address the above problem, this paper proposes a Deformation Inpainting Network (DINet) for high-resolution face visually dubbing. Different from previous works relying on multiple up-sample layers to directly generate pixels from latent embeddings, DINet performs spatial deformation on feature maps of reference images to better preserve high-frequency textural details. Specifically, DINet consists of one deformation part and one inpainting part. In the first part, five reference facial images adaptively perform spatial deformation to create deformed feature maps encoding mouth shapes at each frame, in order to align with the input driving audio and also the head poses of the input source images. In the second part, to produce face visually dubbing, a feature decoder is responsible for adaptively incorporating mouth movements from the deformed feature maps and other attributes (i.e., head pose and upper facial expression) from the source feature maps together. Finally, DINet achieves face visually dubbing with rich textural details. We conduct qualitative and quantitative comparisons to validate our DINet on high-resolution videos. The experimental results show that our method outperforms state-of-the-art works.
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Dec 06, 2022In this work, we propose a semantic flow-guided two-stage framework for shape-aware face swapping, namely FlowFace. Unlike most previous methods that focus on transferring the source inner facial features but neglect facial contours, our FlowFace can transfer both of them to a target face, thus leading to more realistic face swapping. Concretely, our FlowFace consists of a face reshaping network and a face swapping network. The face reshaping network addresses the shape outline differences between the source and target faces. It first estimates a semantic flow (i.e., face shape differences) between the source and the target face, and then explicitly warps the target face shape with the estimated semantic flow. After reshaping, the face swapping network generates inner facial features that exhibit the identity of the source face. We employ a pre-trained face masked autoencoder (MAE) to extract facial features from both the source face and the target face. In contrast to previous methods that use identity embedding to preserve identity information, the features extracted by our encoder can better capture facial appearances and identity information. Then, we develop a cross-attention fusion module to adaptively fuse inner facial features from the source face with the target facial attributes, thus leading to better identity preservation. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace outperforms the state-of-the-art significantly.
Rethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
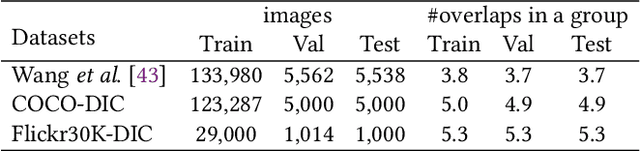
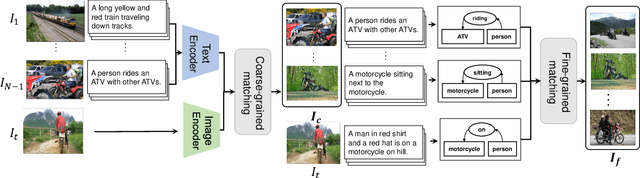
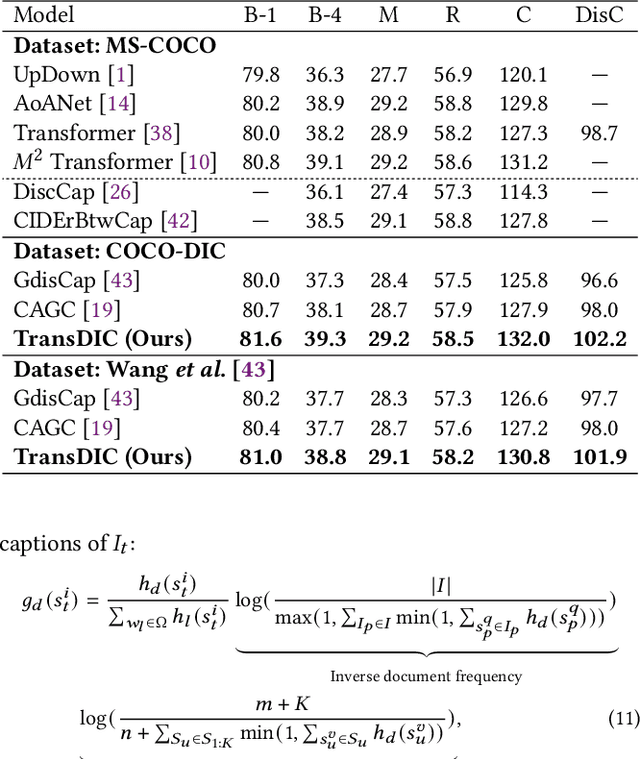
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
The Devil is in the Labels: Noisy Label Correction for Robust Scene Graph Generation
Jun 07, 2022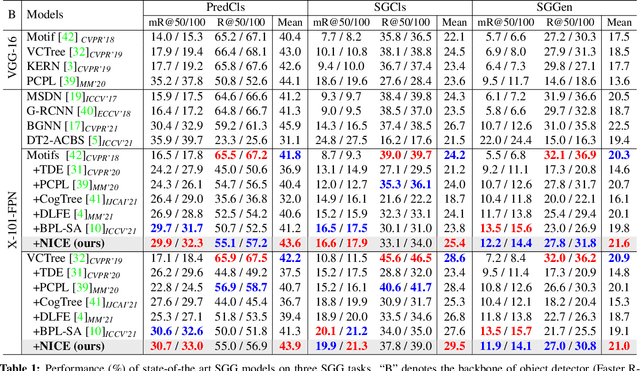
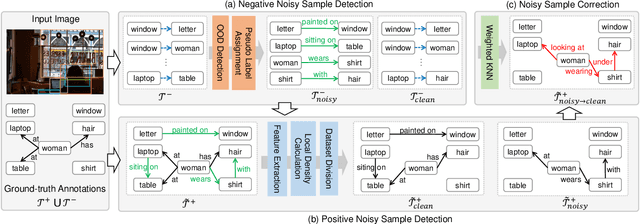
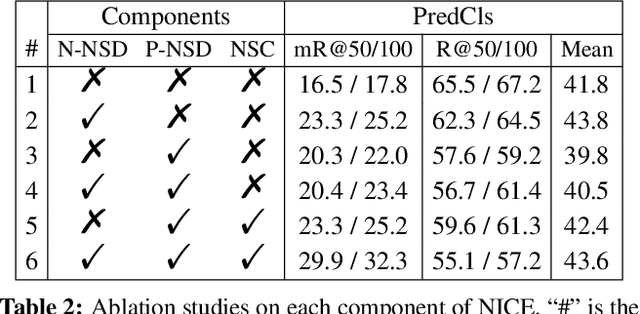
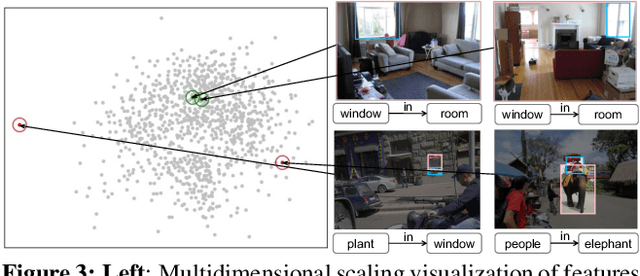
Unbiased SGG has achieved significant progress over recent years. However, almost all existing SGG models have overlooked the ground-truth annotation qualities of prevailing SGG datasets, i.e., they always assume: 1) all the manually annotated positive samples are equally correct; 2) all the un-annotated negative samples are absolutely background. In this paper, we argue that both assumptions are inapplicable to SGG: there are numerous "noisy" groundtruth predicate labels that break these two assumptions, and these noisy samples actually harm the training of unbiased SGG models. To this end, we propose a novel model-agnostic NoIsy label CorrEction strategy for SGG: NICE. NICE can not only detect noisy samples but also reassign more high-quality predicate labels to them. After the NICE training, we can obtain a cleaner version of SGG dataset for model training. Specifically, NICE consists of three components: negative Noisy Sample Detection (Neg-NSD), positive NSD (Pos-NSD), and Noisy Sample Correction (NSC). Firstly, in Neg-NSD, we formulate this task as an out-of-distribution detection problem, and assign pseudo labels to all detected noisy negative samples. Then, in Pos-NSD, we use a clustering-based algorithm to divide all positive samples into multiple sets, and treat the samples in the noisiest set as noisy positive samples. Lastly, in NSC, we use a simple but effective weighted KNN to reassign new predicate labels to noisy positive samples. Extensive results on different backbones and tasks have attested to the effectiveness and generalization abilities of each component of NICE.