 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Labels: Noisy Label Correction for Robust Scene Graph Generation
Paper and Code
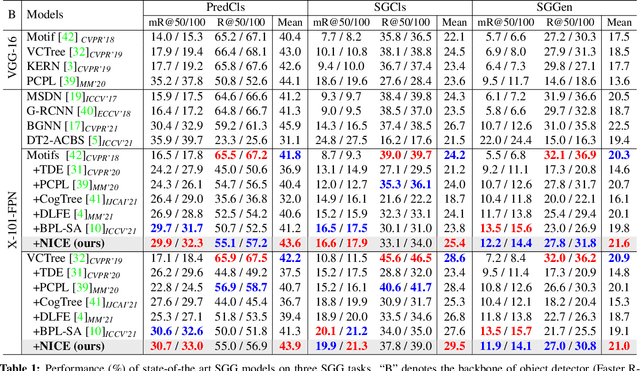
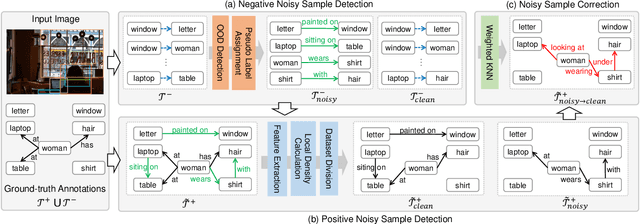
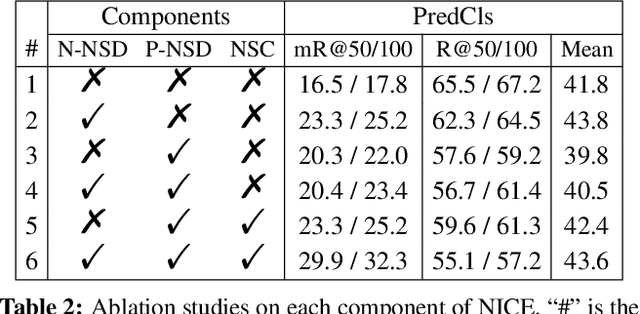
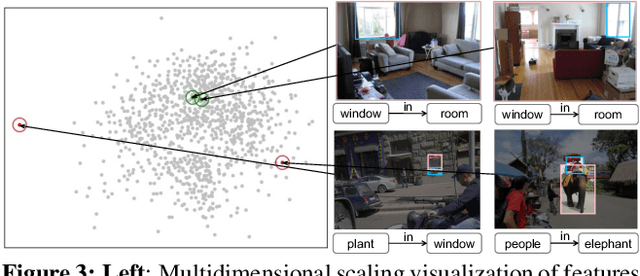
Unbiased SGG has achieved significant progress over recent years. However, almost all existing SGG models have overlooked the ground-truth annotation qualities of prevailing SGG datasets, i.e., they always assume: 1) all the manually annotated positive samples are equally correct; 2) all the un-annotated negative samples are absolutely background. In this paper, we argue that both assumptions are inapplicable to SGG: there are numerous "noisy" groundtruth predicate labels that break these two assumptions, and these noisy samples actually harm the training of unbiased SGG models. To this end, we propose a novel model-agnostic NoIsy label CorrEction strategy for SGG: NICE. NICE can not only detect noisy samples but also reassign more high-quality predicate labels to them. After the NICE training, we can obtain a cleaner version of SGG dataset for model training. Specifically, NICE consists of three components: negative Noisy Sample Detection (Neg-NSD), positive NSD (Pos-NSD), and Noisy Sample Correction (NSC). Firstly, in Neg-NSD, we formulate this task as an out-of-distribution detection problem, and assign pseudo labels to all detected noisy negative samples. Then, in Pos-NSD, we use a clustering-based algorithm to divide all positive samples into multiple sets, and treat the samples in the noisiest set as noisy positive samples. Lastly, in NSC, we use a simple but effective weighted KNN to reassign new predicate labels to noisy positive samples. Extensive results on different backbones and tasks have attested to the effectiveness and generalization abilities of each component of NICE.