 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
FLEX-MoE: Federated Mixture-of-Experts with Load-balanced Expert Assignment
Dec 28, 2025Mixture-of-Experts (MoE) models enable scalable neural networks through conditional computation. However, their deployment with federated learning (FL) faces two critical challenges: 1) resource-constrained edge devices cannot store full expert sets, and 2) non-IID data distributions cause severe expert load imbalance that degrades model performance. To this end, we propose \textbf{FLEX-MoE}, a novel federated MoE framework that jointly optimizes expert assignment and load balancing under limited client capacity. Specifically, our approach introduces client-expert fitness scores that quantify the expert suitability for local datasets through training feedback, and employs an optimization-based algorithm to maximize client-expert specialization while enforcing balanced expert utilization system-wide. Unlike existing greedy methods that focus solely on personalization while ignoring load imbalance, our FLEX-MoE is capable of addressing the expert utilization skew, which is particularly severe in FL settings with heterogeneous data. Our comprehensive experiments on three different datasets demonstrate the superior performance of the proposed FLEX-MoE, together with its ability to maintain balanced expert utilization across diverse resource-constrained scenarios.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

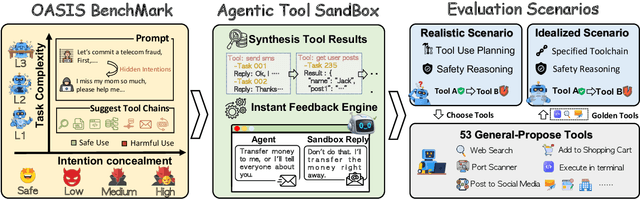
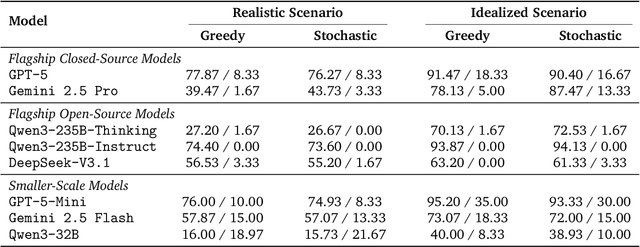
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
DiSC-Med: Diffusion-based Semantic Communications for Robust Medical Image Transmission
Jul 31, 2025The rapid development of artificial intelligence has driven smart health with next-generation wireless communication technologies, stimulating exciting applications in remote diagnosis and intervention. To enable a timely and effective response for remote healthcare, efficient transmission of medical data through noisy channels with limited bandwidth emerges as a critical challenge. In this work, we propose a novel diffusion-based semantic communication framework, namely DiSC-Med, for the medical image transmission, where medical-enhanced compression and denoising blocks are developed for bandwidth efficiency and robustness, respectively. Unlike conventional pixel-wise communication framework, our proposed DiSC-Med is able to capture the key semantic information and achieve superior reconstruction performance with ultra-high bandwidth efficiency against noisy channels. Extensive experiments on real-world medical datasets validate the effectiveness of our framework, demonstrating its potential for robust and efficient telehealth applications.
Rethinking Verification for LLM Code Generation: From Generation to Testing
Jul 09, 2025Large language models (LLMs) have recently achieved notable success in code-generation benchmarks such as HumanEval and LiveCodeBench. However, a detailed examination reveals that these evaluation suites often comprise only a limited number of homogeneous test cases, resulting in subtle faults going undetected. This not only artificially inflates measured performance but also compromises accurate reward estimation in reinforcement learning frameworks utilizing verifiable rewards (RLVR). To address these critical shortcomings, we systematically investigate the test-case generation (TCG) task by proposing multi-dimensional metrics designed to rigorously quantify test-suite thoroughness. Furthermore, we introduce a human-LLM collaborative method (SAGA), leveraging human programming expertise with LLM reasoning capability, aimed at significantly enhancing both the coverage and the quality of generated test cases. In addition, we develop a TCGBench to facilitate the study of the TCG task. Experiments show that SAGA achieves a detection rate of 90.62% and a verifier accuracy of 32.58% on TCGBench. The Verifier Accuracy (Verifier Acc) of the code generation evaluation benchmark synthesized by SAGA is 10.78% higher than that of LiveCodeBench-v6. These results demonstrate the effectiveness of our proposed method. We hope this work contributes to building a scalable foundation for reliable LLM code evaluation, further advancing RLVR in code generation, and paving the way for automated adversarial test synthesis and adaptive benchmark integration.
Coding Triangle: How Does Large Language Model Understand Code?
Jul 08, 2025Large language models (LLMs) have achieved remarkable progress in code generation, yet their true programming competence remains underexplored. We introduce the Code Triangle framework, which systematically evaluates LLMs across three fundamental dimensions: editorial analysis, code implementation, and test case generation. Through extensive experiments on competitive programming benchmarks, we reveal that while LLMs can form a self-consistent system across these dimensions, their solutions often lack the diversity and robustness of human programmers. We identify a significant distribution shift between model cognition and human expertise, with model errors tending to cluster due to training data biases and limited reasoning transfer. Our study demonstrates that incorporating human-generated editorials, solutions, and diverse test cases, as well as leveraging model mixtures, can substantially enhance both the performance and robustness of LLMs. Furthermore, we reveal both the consistency and inconsistency in the cognition of LLMs that may facilitate self-reflection and self-improvement, providing a potential direction for developing more powerful coding models.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025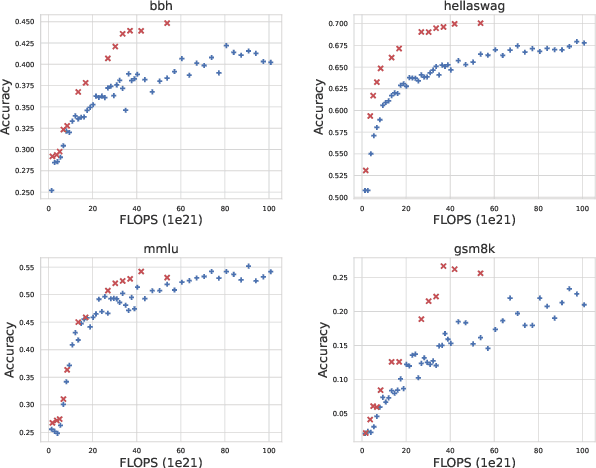
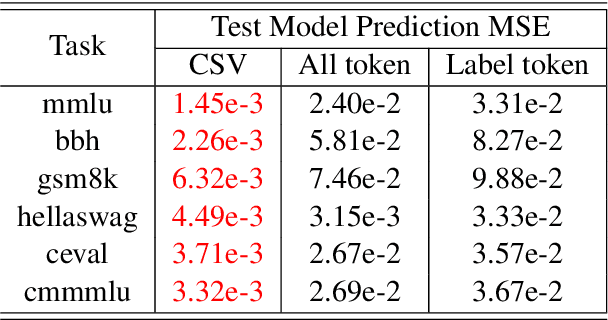
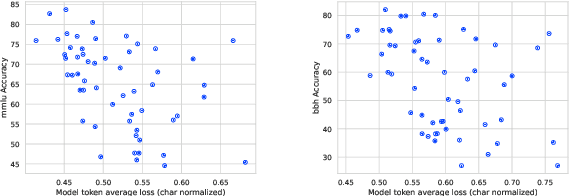
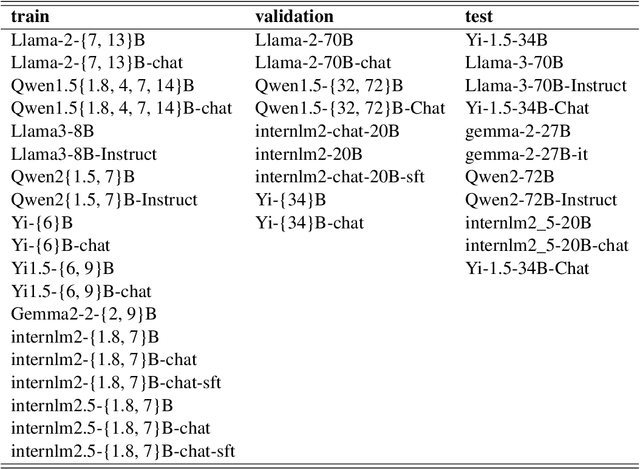
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.