 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Driven Semantic Quantization and Imitation Learning for Goal-Oriented Communications
Feb 25, 2025



Semantic communication marks a new paradigm shift from bit-wise data transmission to semantic information delivery for the purpose of bandwidth reduction. To more effectively carry out specialized downstream tasks at the receiver end, it is crucial to define the most critical semantic message in the data based on the task or goal-oriented features. In this work, we propose a novel goal-oriented communication (GO-COM) framework, namely Goal-Oriented Semantic Variational Autoencoder (GOS-VAE), by focusing on the extraction of the semantics vital to the downstream tasks. Specifically, we adopt a Vector Quantized Variational Autoencoder (VQ-VAE) to compress media data at the transmitter side. Instead of targeting the pixel-wise image data reconstruction, we measure the quality-of-service at the receiver end based on a pre-defined task-incentivized model. Moreover, to capture the relevant semantic features in the data reconstruction, imitation learning is adopted to measure the data regeneration quality in terms of goal-oriented semantics. Our experimental results demonstrate the power of imitation learning in characterizing goal-oriented semantics and bandwidth efficiency of our proposed GOS-VAE.
LaMI-GO: Latent Mixture Integration for Goal-Oriented Communications Achieving High Spectrum Efficiency
Dec 18, 2024



The recent rise of semantic-style communications includes the development of goal-oriented communications (GOCOMs) remarkably efficient multimedia information transmissions. The concept of GO-COMS leverages advanced artificial intelligence (AI) tools to address the rising demand for bandwidth efficiency in applications, such as edge computing and Internet-of-Things (IoT). Unlike traditional communication systems focusing on source data accuracy, GO-COMs provide intelligent message delivery catering to the special needs critical to accomplishing downstream tasks at the receiver. In this work, we present a novel GO-COM framework, namely LaMI-GO that utilizes emerging generative AI for better quality-of-service (QoS) with ultra-high communication efficiency. Specifically, we design our LaMI-GO system backbone based on a latent diffusion model followed by a vector-quantized generative adversarial network (VQGAN) for efficient latent embedding and information representation. The system trains a common feature codebook the receiver side. Our experimental results demonstrate substantial improvement in perceptual quality, accuracy of downstream tasks, and bandwidth consumption over the state-of-the-art GOCOM systems and establish the power of our proposed LaMI-GO communication framework.
Diff-GO$^\text{n}$: Enhancing Diffusion Models for Goal-Oriented Communications
Dec 09, 2024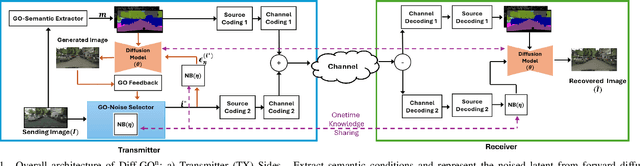
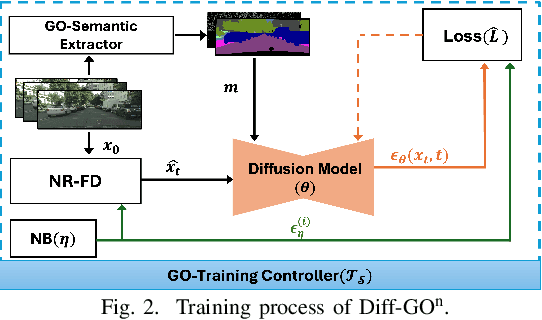
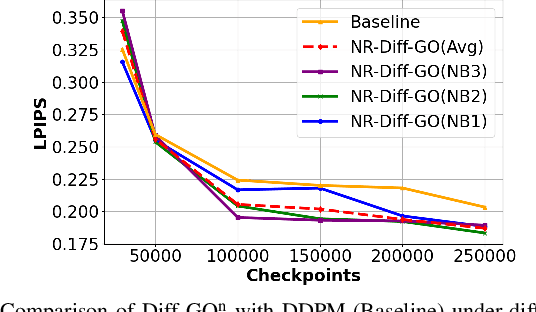

The rapid expansion of edge devices and Internet-of-Things (IoT) continues to heighten the demand for data transport under limited spectrum resources. The goal-oriented communications (GO-COM), unlike traditional communication systems designed for bit-level accuracy, prioritizes more critical information for specific application goals at the receiver. To improve the efficiency of generative learning models for GO-COM, this work introduces a novel noise-restricted diffusion-based GO-COM (Diff-GO$^\text{n}$) framework for reducing bandwidth overhead while preserving the media quality at the receiver. Specifically, we propose an innovative Noise-Restricted Forward Diffusion (NR-FD) framework to accelerate model training and reduce the computation burden for diffusion-based GO-COMs by leveraging a pre-sampled pseudo-random noise bank (NB). Moreover, we design an early stopping criterion for improving computational efficiency and convergence speed, allowing high-quality generation in fewer training steps. Our experimental results demonstrate superior perceptual quality of data transmission at a reduced bandwidth usage and lower computation, making Diff-GO$^\text{n}$ well-suited for real-time communications and downstream applications.
Not All LLM-Generated Data Are Equal: Rethinking Data Weighting in Text Classification
Oct 28, 2024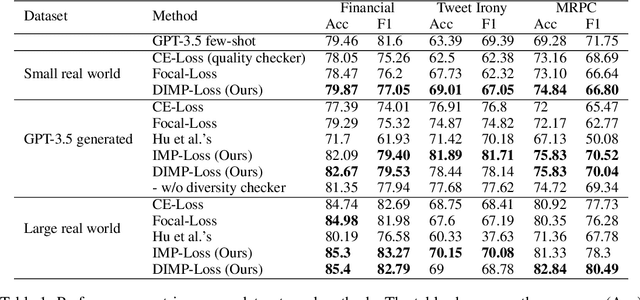
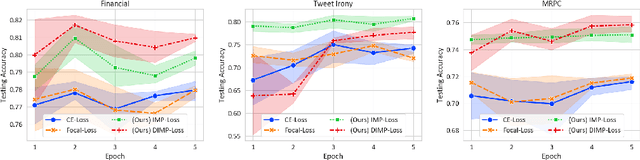
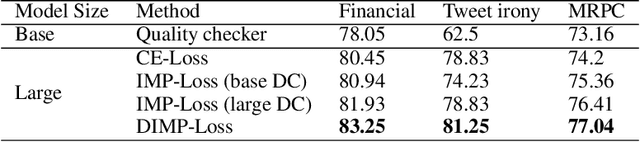
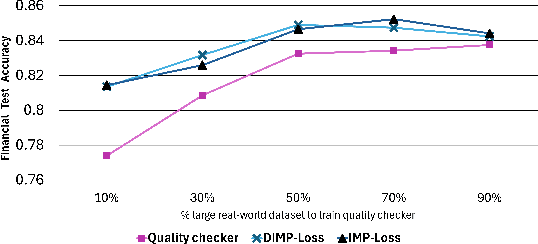
Synthetic data augmentation via large language models (LLMs) allows researchers to leverage additional training data, thus enhancing the performance of downstream tasks, especially when real-world data is scarce. However, the generated data can deviate from the real-world data, and this misalignment can bring deficient outcomes while applying the trained model to applications. Therefore, we proposed efficient weighted-loss approaches to align synthetic data with real-world distribution by emphasizing high-quality and diversified data generated by LLMs with using merely a little real-world data. We empirically assessed the effectiveness of our method on multiple text classification tasks, and the results showed leveraging our approaches on a BERT-level model robustly outperformed standard cross-entropy and other data weighting approaches, providing potential solutions to effectively leveraging synthetic data from any suitable data generator for model training.
Predict and Use Latent Patterns for Short-Text Conversation
Oct 27, 2020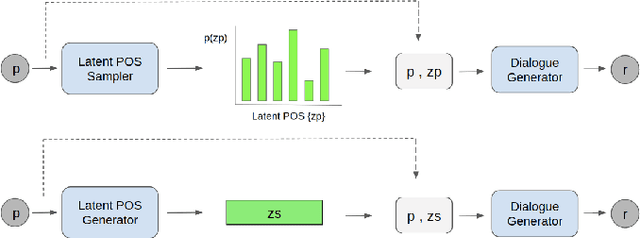
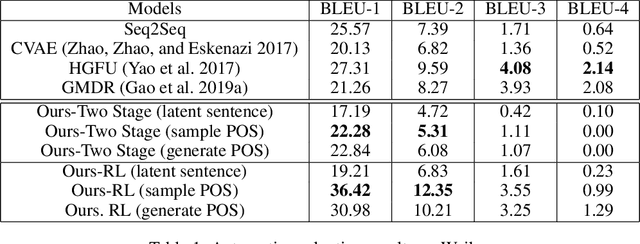

Many neural network models nowadays have achieved promising performances in Chit-chat settings. The majority of them rely on an encoder for understanding the post and a decoder for generating the response. Without given assigned semantics, the models lack the fine-grained control over responses as the semantic mapping between posts and responses is hidden on the fly within the end-to-end manners. Some previous works utilize sampled latent words as a controllable semantic form to drive the generated response around the work, but few works attempt to use more complex semantic forms to guide the generation. In this paper, we propose to use more detailed semantic forms, including latent responses and part-of-speech sequences sampled from the corresponding distributions, as the controllable semantics to guide the generation. Our experimental results show that the richer semantics are not only able to provide informative and diverse responses, but also increase the overall performance of response quality, including fluency and coherence.