 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2Query++: Topic-Coverage based Document Expansion and its Application to Dense Retrieval via Dual-Index Fusion
Oct 10, 2025
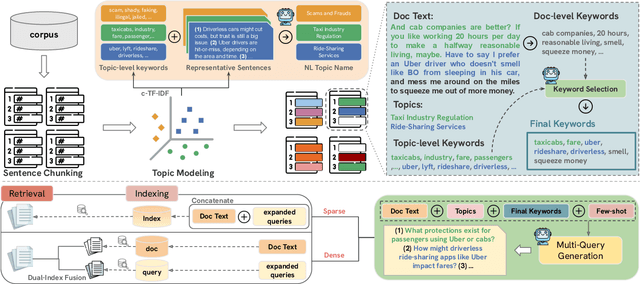
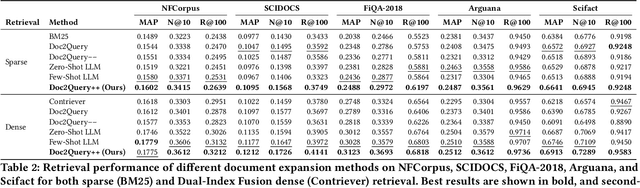
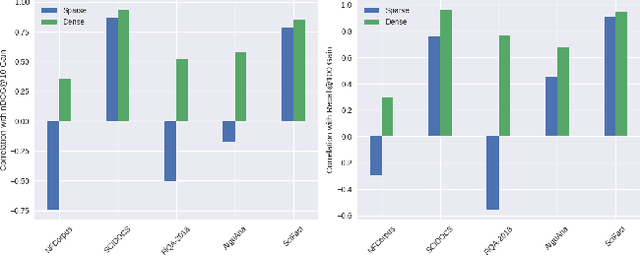
Document expansion (DE) via query generation tackles vocabulary mismatch in sparse retrieval, yet faces limitations: uncontrolled generation producing hallucinated or redundant queries with low diversity; poor generalization from in-domain training (e.g., MS MARCO) to out-of-domain data like BEIR; and noise from concatenation harming dense retrieval. While Large Language Models (LLMs) enable cross-domain query generation, basic prompting lacks control, and taxonomy-based methods rely on domain-specific structures, limiting applicability. To address these challenges, we introduce Doc2Query++, a DE framework that structures query generation by first inferring a document's latent topics via unsupervised topic modeling for cross-domain applicability, then using hybrid keyword selection to create a diverse and relevant keyword set per document. This guides LLM not only to leverage keywords, which ensure comprehensive topic representation, but also to reduce redundancy through diverse, relevant terms. To prevent noise from query appending in dense retrieval, we propose Dual-Index Fusion strategy that isolates text and query signals, boosting performance in dense settings. Extensive experiments show Doc2Query++ significantly outperforms state-of-the-art baselines, achieving substantial gains in MAP, nDCG@10 and Recall@100 across diverse datasets on both sparse and dense retrieval.
Not All LLM-Generated Data Are Equal: Rethinking Data Weighting in Text Classification
Oct 28, 2024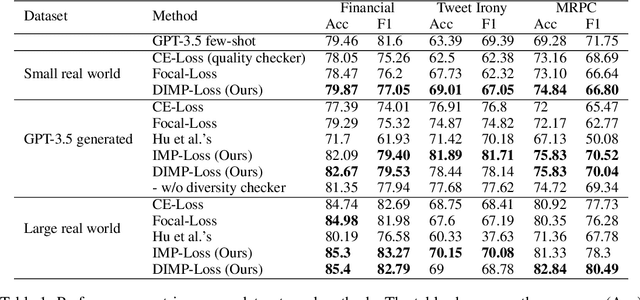
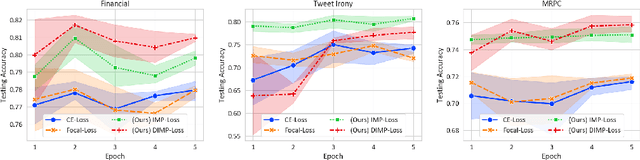
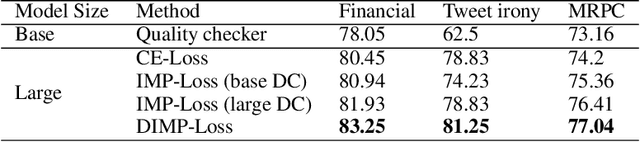
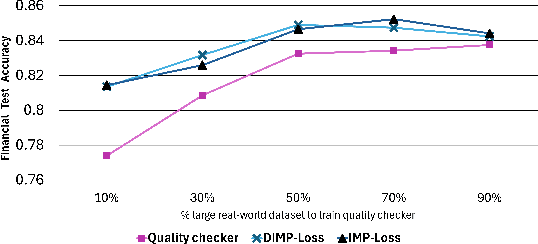
Synthetic data augmentation via large language models (LLMs) allows researchers to leverage additional training data, thus enhancing the performance of downstream tasks, especially when real-world data is scarce. However, the generated data can deviate from the real-world data, and this misalignment can bring deficient outcomes while applying the trained model to applications. Therefore, we proposed efficient weighted-loss approaches to align synthetic data with real-world distribution by emphasizing high-quality and diversified data generated by LLMs with using merely a little real-world data. We empirically assessed the effectiveness of our method on multiple text classification tasks, and the results showed leveraging our approaches on a BERT-level model robustly outperformed standard cross-entropy and other data weighting approaches, providing potential solutions to effectively leveraging synthetic data from any suitable data generator for model training.
Generating Attractive and Authentic Copywriting from Customer Reviews
Apr 22, 2024



The goal of product copywriting is to capture the interest of potential buyers by emphasizing the features of products through text descriptions. As e-commerce platforms offer a wide range of services, it's becoming essential to dynamically adjust the styles of these auto-generated descriptions. Typical approaches to copywriting generation often rely solely on specified product attributes, which may result in dull and repetitive content. To tackle this issue, we propose to generate copywriting based on customer reviews, as they provide firsthand practical experiences with products, offering a richer source of information than just product attributes. We have developed a sequence-to-sequence framework, enhanced with reinforcement learning, to produce copywriting that is attractive, authentic, and rich in information. Our framework outperforms all existing baseline and zero-shot large language models, including LLaMA-2-chat-7B and GPT-3.5, in terms of both attractiveness and faithfulness. Furthermore, this work features the use of LLMs for aspect-based summaries collection and argument allure assessment. Experiments demonstrate the effectiveness of using LLMs for marketing domain corpus construction. The code and the dataset is publicly available at: https://github.com/YuXiangLin1234/Copywriting-Generation.
Extending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
Roof-BERT: Divide Understanding Labour and Join in Work
Dec 13, 2021



Recent work on enhancing BERT-based language representation models with knowledge graphs (KGs) has promising results on multiple NLP tasks. State-of-the-art approaches typically integrate the original input sentences with triples in KGs, and feed the combined representation into a BERT model. However, as the sequence length of a BERT model is limited, the framework can not contain too much knowledge besides the original input sentences and is thus forced to discard some knowledge. The problem is especially severe for those downstream tasks that input is a long paragraph or even a document, such as QA or reading comprehension tasks. To address the problem, we propose Roof-BERT, a model with two underlying BERTs and a fusion layer on them. One of the underlying BERTs encodes the knowledge resources and the other one encodes the original input sentences, and the fusion layer like a roof integrates both BERTs' encodings. Experiment results on QA task reveal the effectiveness of the proposed model.
DCT: Dynamic Compressive Transformer for Modeling Unbounded Sequence
Oct 10, 2021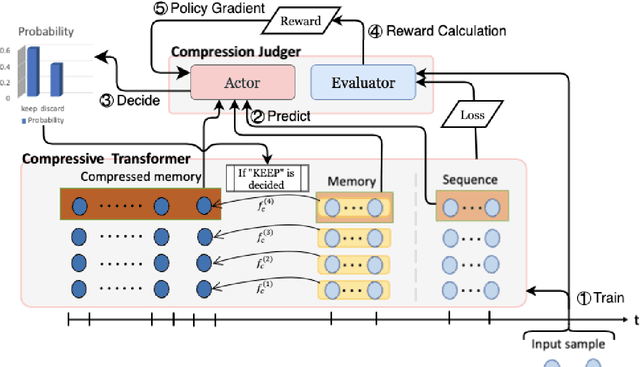

In this paper, we propose Dynamic Compressive Transformer (DCT), a transformer-based framework for modeling the unbounded sequence. In contrast to the previous baselines which append every sentence representation to memory, conditionally selecting and appending them is a more reasonable solution to deal with unlimited long sequences. Our model uses a policy that determines whether the sequence should be kept in memory with a compressed state or discarded during the training process. With the benefits of retaining semantically meaningful sentence information in the memory system, our experiment results on Enwik8 benchmark show that DCT outperforms the previous state-of-the-art (SOTA) model.
H-FND: Hierarchical False-Negative Denoising for Distant Supervision Relation Extraction
Dec 14, 2020
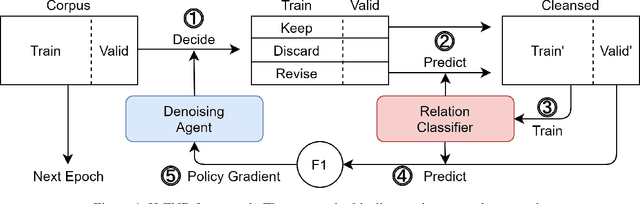
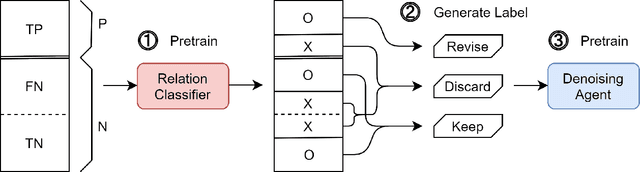
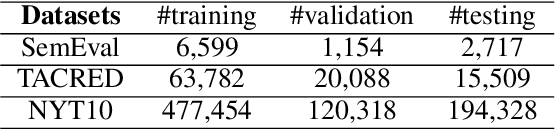
Although distant supervision automatically generates training data for relation extraction, it also introduces false-positive (FP) and false-negative (FN) training instances to the generated datasets. Whereas both types of errors degrade the final model performance, previous work on distant supervision denoising focuses more on suppressing FP noise and less on resolving the FN problem. We here propose H-FND, a hierarchical false-negative denoising framework for robust distant supervision relation extraction, as an FN denoising solution. H-FND uses a hierarchical policy which first determines whether non-relation (NA) instances should be kept, discarded, or revised during the training process. For those learning instances which are to be revised, the policy further reassigns them appropriate relations, making them better training inputs. Experiments on SemEval-2010 and TACRED were conducted with controlled FN ratios that randomly turn the relations of training and validation instances into negatives to generate FN instances. In this setting, H-FND can revise FN instances correctly and maintains high F1 scores even when 50% of the instances have been turned into negatives. Experiment on NYT10 is further conducted to shows that H-FND is applicable in a realistic setting.
Predict and Use Latent Patterns for Short-Text Conversation
Oct 27, 2020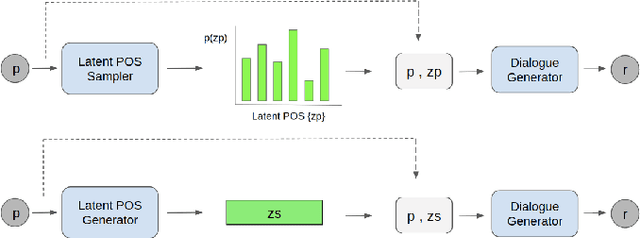
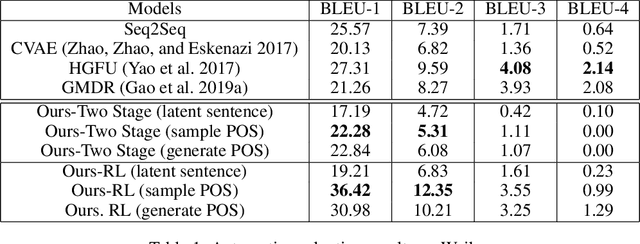

Many neural network models nowadays have achieved promising performances in Chit-chat settings. The majority of them rely on an encoder for understanding the post and a decoder for generating the response. Without given assigned semantics, the models lack the fine-grained control over responses as the semantic mapping between posts and responses is hidden on the fly within the end-to-end manners. Some previous works utilize sampled latent words as a controllable semantic form to drive the generated response around the work, but few works attempt to use more complex semantic forms to guide the generation. In this paper, we propose to use more detailed semantic forms, including latent responses and part-of-speech sequences sampled from the corresponding distributions, as the controllable semantics to guide the generation. Our experimental results show that the richer semantics are not only able to provide informative and diverse responses, but also increase the overall performance of response quality, including fluency and coherence.
Why Attention? Analyzing and Remedying BiLSTM Deficiency in Modeling Cross-Context for NER
Oct 07, 2019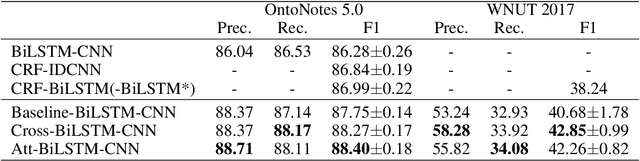



State-of-the-art approaches of NER have used sequence-labeling BiLSTM as a core module. This paper formally shows the limitation of BiLSTM in modeling cross-context patterns. Two types of simple cross-structures -- self-attention and Cross-BiLSTM -- are shown to effectively remedy the problem. On both OntoNotes 5.0 and WNUT 2017, clear and consistent improvements are achieved over bare-bone models, up to 8.7% on some of the multi-token mentions. In-depth analyses across several aspects of the improvements, especially the identification of multi-token mentions, are further given.
Remedying BiLSTM-CNN Deficiency in Modeling Cross-Context for NER
Aug 29, 2019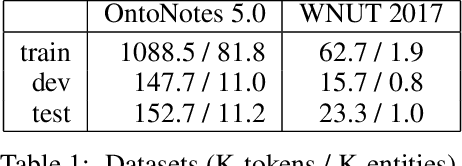

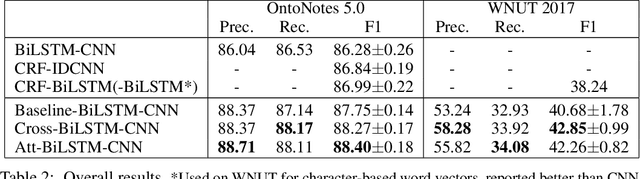
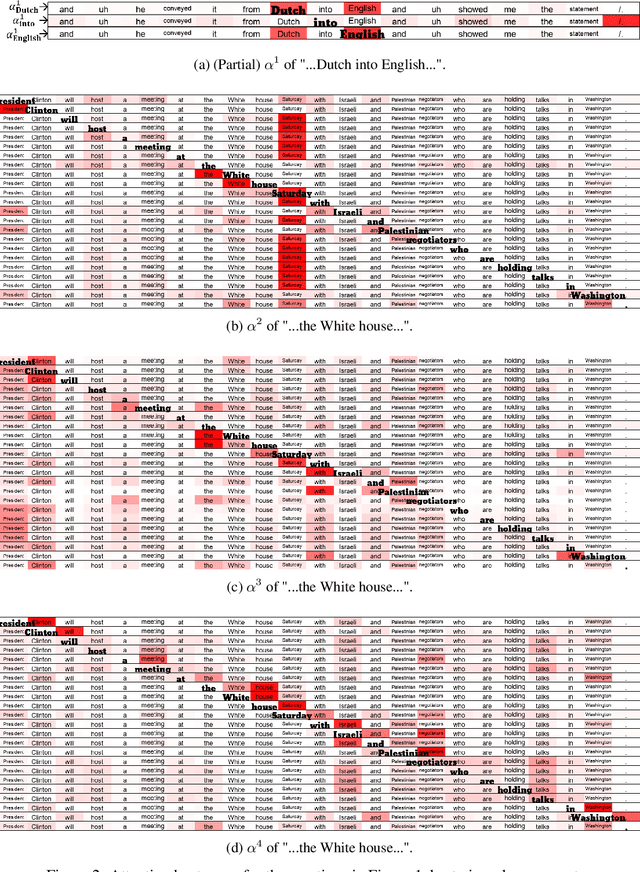
Recent researches prevalently used BiLSTM-CNN as a core module for NER in a sequence-labeling setup. This paper formally shows the limitation of BiLSTM-CNN encoders in modeling cross-context patterns for each word, i.e., patterns crossing past and future for a specific time step. Two types of cross-structures are used to remedy the problem: A BiLSTM variant with cross-link between layers; a multi-head self-attention mechanism. These cross-structures bring consistent improvements across a wide range of NER domains for a core system using BiLSTM-CNN without additional gazetteers, POS taggers, language-modeling, or multi-task supervision. The model surpasses comparable previous models on OntoNotes 5.0 and WNUT 2017 by 1.4% and 4.6%, especially improving emerging, complex, confusing, and multi-token entity mentions, showing the importance of remedying the core module of NER.