 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASTE: Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling
Apr 09, 2025Large Language Models (LLMs) excel in text-based natural language processing tasks but remain constrained by their reliance on textual inputs and outputs. To enable more natural human-LLM interaction, recent progress have focused on deriving a spoken language model (SLM) that can not only listen but also generate speech. To achieve this, a promising direction is to conduct speech-text joint modeling. However, recent SLM still lag behind text LLM due to the modality mismatch. One significant mismatch can be the sequence lengths between speech and text tokens. To address this, we introduce Text-Aligned Speech Tokenization and Embedding (TASTE), a method that directly addresses the modality gap by aligning speech token with the corresponding text transcription during the tokenization stage. We propose a method that can achieve this through the special aggregation mechanism and with speech reconstruction as the training objective. We conduct extensive experiments and show that TASTE can preserve essential paralinguistic information while dramatically reducing the token sequence length. Furthermore, by leveraging TASTE, we can adapt text-based LLMs into effective SLMs with parameter-efficient fine-tuning techniques such as Low-Rank Adaptation (LoRA). Experimental results on benchmark tasks, including SALMON and StoryCloze, demonstrate that TASTE-based SLMs perform similarly to previous full-finetuning methods. To our knowledge, TASTE is the first end-to-end approach that utilizes a reconstruction objective to automatically learn a text-aligned speech tokenization and embedding suitable for spoken language modeling. Our demo, code, and models are publicly available at https://github.com/mtkresearch/TASTE-SpokenLM.
BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation -- Challenges and Insights
Jan 29, 2025We present BreezyVoice, a Text-to-Speech (TTS) system specifically adapted for Taiwanese Mandarin, highlighting phonetic control abilities to address the unique challenges of polyphone disambiguation in the language. Building upon CosyVoice, we incorporate a $S^{3}$ tokenizer, a large language model (LLM), an optimal-transport conditional flow matching model (OT-CFM), and a grapheme to phoneme prediction model, to generate realistic speech that closely mimics human utterances. Our evaluation demonstrates BreezyVoice's superior performance in both general and code-switching contexts, highlighting its robustness and effectiveness in generating high-fidelity speech. Additionally, we address the challenges of generalizability in modeling long-tail speakers and polyphone disambiguation. Our approach significantly enhances performance and offers valuable insights into the workings of neural codec TTS systems.
The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities
Jan 25, 2025Llama-Breeze2 (hereinafter referred to as Breeze2) is a suite of advanced multi-modal language models, available in 3B and 8B parameter configurations, specifically designed to enhance Traditional Chinese language representation. Building upon the Llama 3.2 model family, we continue the pre-training of Breeze2 on an extensive corpus to enhance the linguistic and cultural heritage of Traditional Chinese. In addition to language modeling capabilities, we significantly augment the models with function calling and vision understanding capabilities. At the time of this publication, as far as we are aware, absent reasoning-inducing prompts, Breeze2 are the strongest performing models in Traditional Chinese function calling and image understanding in its size class. The effectiveness of Breeze2 is benchmarked across various tasks, including Taiwan general knowledge, instruction-following, long context, function calling, and vision understanding. We are publicly releasing all Breeze2 models under the Llama 3.2 Community License. We also showcase the capabilities of the model running on mobile platform with a mobile application which we also open source.
FineWeb-zhtw: Scalable Curation of Traditional Chinese Text Data from the Web
Nov 25, 2024

The quality and size of a pretraining dataset significantly influence the performance of large language models (LLMs). While there have been numerous efforts in the curation of such a dataset for English users, there is a relative lack of similar initiatives for Traditional Chinese. Building upon this foundation of FineWeb, we introduce FineWeb-zhtw, a dataset tailored specifically for Traditional Chinese users. We came up with multiple stages of meticulously designed filters to cater to the linguistic difference between English and Traditional Chinese, to ensure comprehensiveness and quality. We determined effectiveness from querying dataset samples with three main objectives. Our code and datasets are publicly available.
Breeze-7B Technical Report
Mar 05, 2024Breeze-7B is an open-source language model based on Mistral-7B, designed to address the need for improved language comprehension and chatbot-oriented capabilities in Traditional Chinese. This technical report provides an overview of the additional pretraining, finetuning, and evaluation stages for the Breeze-7B model. The Breeze-7B family of base and chat models exhibits good performance on language comprehension and chatbot-oriented tasks, reaching the top in several benchmarks among models comparable in its complexity class.
Extending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
Cyclic orthogonal convolutions for long-range integration of features
Dec 11, 2020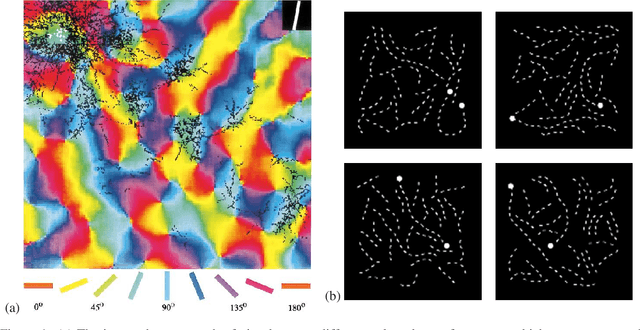

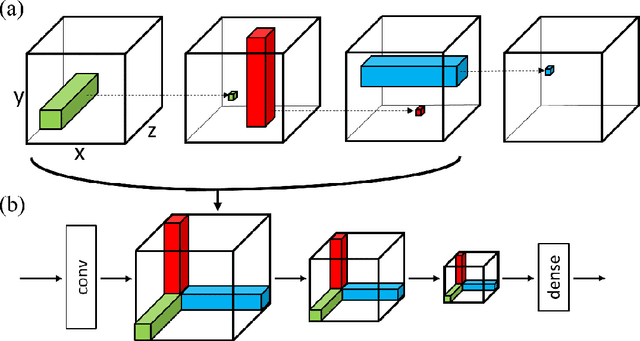
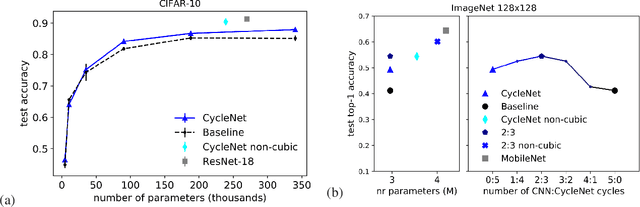
In Convolutional Neural Networks (CNNs) information flows across a small neighbourhood of each pixel of an image, preventing long-range integration of features before reaching deep layers in the network. We propose a novel architecture that allows flexible information flow between features $z$ and locations $(x,y)$ across the entire image with a small number of layers. This architecture uses a cycle of three orthogonal convolutions, not only in $(x,y)$ coordinates, but also in $(x,z)$ and $(y,z)$ coordinates. We stack a sequence of such cycles to obtain our deep network, named CycleNet. As this only requires a permutation of the axes of a standard convolution, its performance can be directly compared to a CNN. Our model obtains competitive results at image classification on CIFAR-10 and ImageNet datasets, when compared to CNNs of similar size. We hypothesise that long-range integration favours recognition of objects by shape rather than texture, and we show that CycleNet transfers better than CNNs to stylised images. On the Pathfinder challenge, where integration of distant features is crucial, CycleNet outperforms CNNs by a large margin. We also show that even when employing a small convolutional kernel, the size of receptive fields of CycleNet reaches its maximum after one cycle, while conventional CNNs require a large number of layers.