 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineWeb-zhtw: Scalable Curation of Traditional Chinese Text Data from the Web
Nov 25, 2024

The quality and size of a pretraining dataset significantly influence the performance of large language models (LLMs). While there have been numerous efforts in the curation of such a dataset for English users, there is a relative lack of similar initiatives for Traditional Chinese. Building upon this foundation of FineWeb, we introduce FineWeb-zhtw, a dataset tailored specifically for Traditional Chinese users. We came up with multiple stages of meticulously designed filters to cater to the linguistic difference between English and Traditional Chinese, to ensure comprehensiveness and quality. We determined effectiveness from querying dataset samples with three main objectives. Our code and datasets are publicly available.
Coarse-to-Fine Point Cloud Registration with SE-Equivariant Representations
Oct 05, 2022
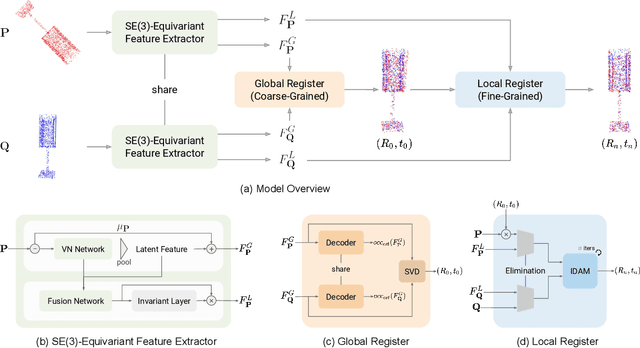
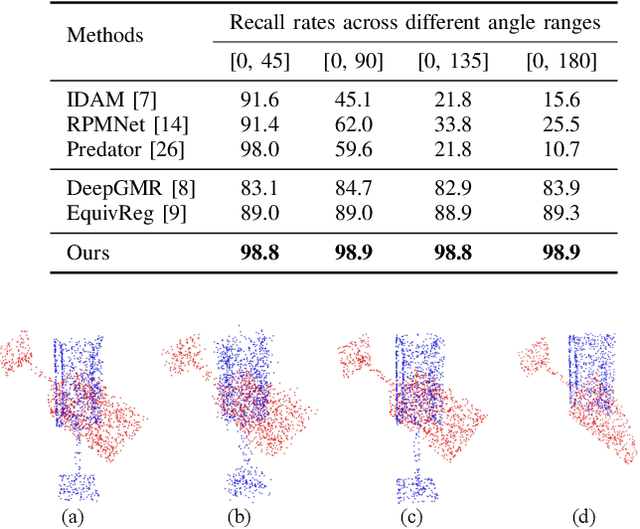
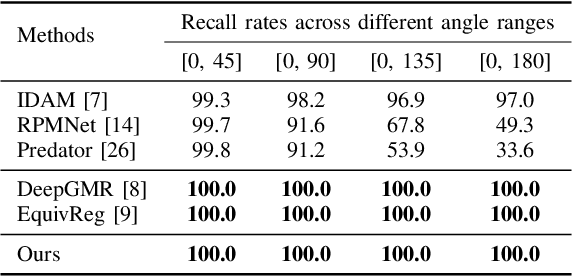
Point cloud registration is a crucial problem in computer vision and robotics. Existing methods either rely on matching local geometric features, which are sensitive to the pose differences, or leverage global shapes and thereby lead to inconsistency when facing distribution variances such as partial overlapping. Combining the advantages of both types of methods, we adopt a coarse-to-fine pipeline that concurrently handles both issues. We first reduce the pose differences between input point clouds by aligning global features; then we match the local features to further refine the inaccurate alignments resulting from distribution variances. As global feature alignment requires the features to preserve the poses of input point clouds and local feature matching expects the features to be invariant to these poses, we propose an SE(3)-equivariant feature extractor to simultaneously generate two types of features. In this feature extractor, representations preserving the poses are first encoded by our novel SE(3)-equivariant network and then converted into pose-invariant ones by a pose-detaching module. Experiments demonstrate that our proposed method increases the recall rate by 20% compared to state-of-the-art methods when facing both pose differences and distribution variances.