 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuRAL: Multi-Scale Region-based Active Learning for Object Detection
Mar 29, 2023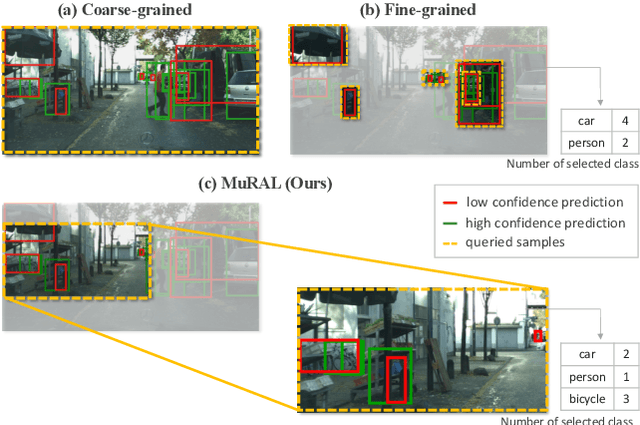
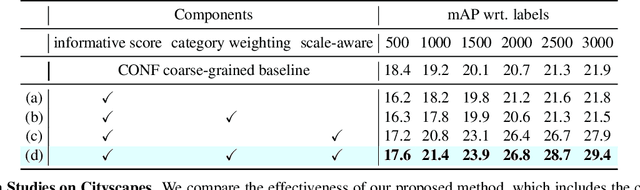
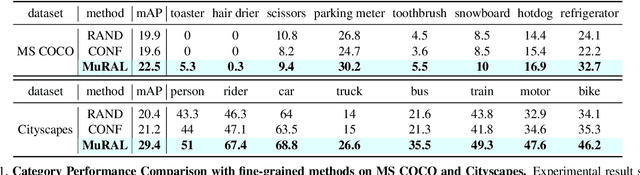

Obtaining large-scale labeled object detection dataset can be costly and time-consuming, as it involves annotating images with bounding boxes and class labels. Thus, some specialized active learning methods have been proposed to reduce the cost by selecting either coarse-grained samples or fine-grained instances from unlabeled data for labeling. However, the former approaches suffer from redundant labeling, while the latter methods generally lead to training instability and sampling bias. To address these challenges, we propose a novel approach called Multi-scale Region-based Active Learning (MuRAL) for object detection. MuRAL identifies informative regions of various scales to reduce annotation costs for well-learned objects and improve training performance. The informative region score is designed to consider both the predicted confidence of instances and the distribution of each object category, enabling our method to focus more on difficult-to-detect classes. Moreover, MuRAL employs a scale-aware selection strategy that ensures diverse regions are selected from different scales for labeling and downstream finetuning, which enhances training stability. Our proposed method surpasses all existing coarse-grained and fine-grained baselines on Cityscapes and MS COCO datasets, and demonstrates significant improvement in difficult category performance.
CrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Oct 12, 2022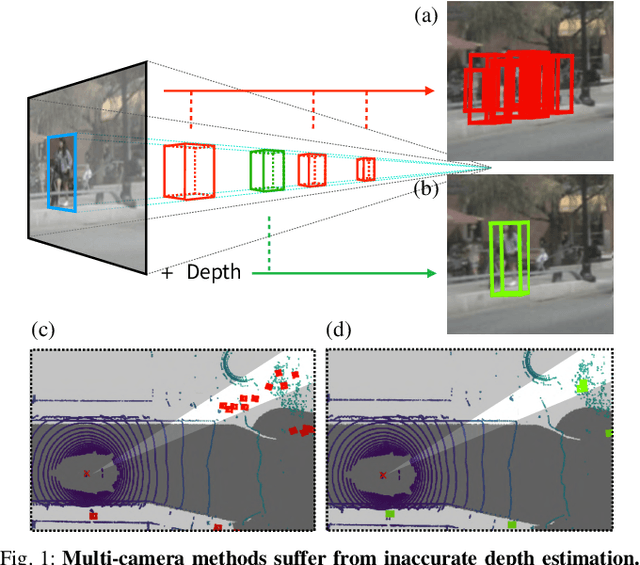
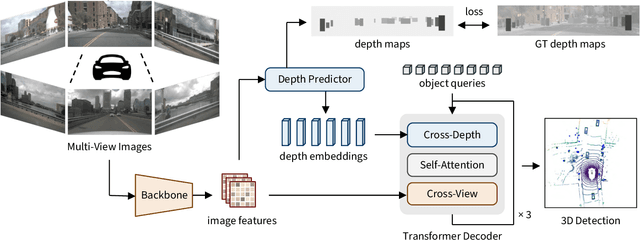
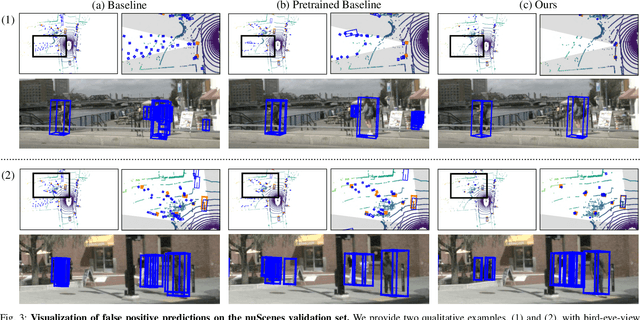
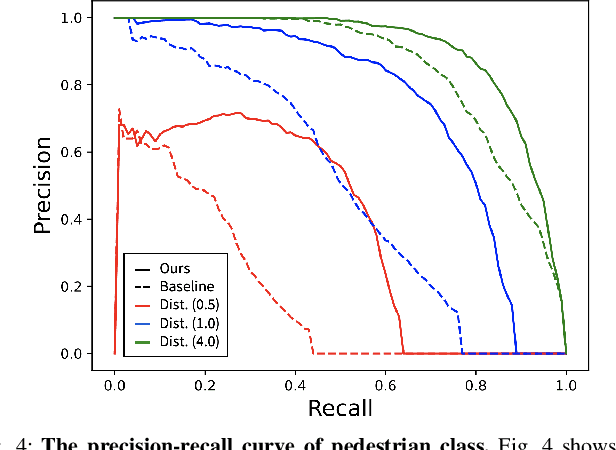
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Coarse-to-Fine Point Cloud Registration with SE-Equivariant Representations
Oct 05, 2022
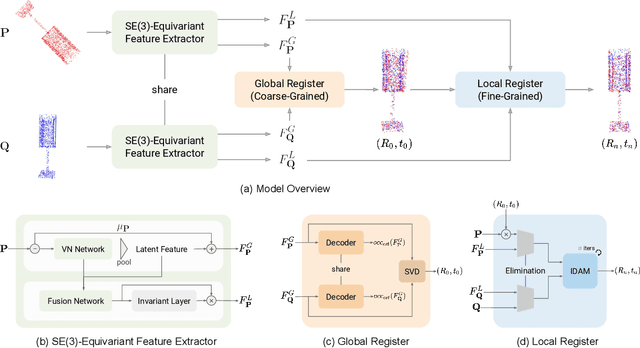
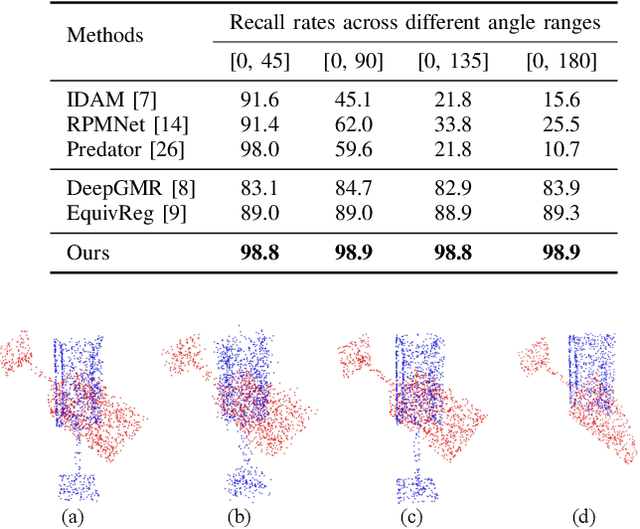
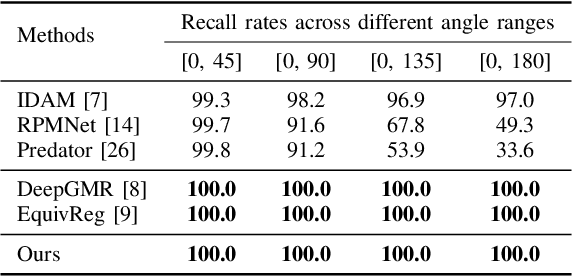
Point cloud registration is a crucial problem in computer vision and robotics. Existing methods either rely on matching local geometric features, which are sensitive to the pose differences, or leverage global shapes and thereby lead to inconsistency when facing distribution variances such as partial overlapping. Combining the advantages of both types of methods, we adopt a coarse-to-fine pipeline that concurrently handles both issues. We first reduce the pose differences between input point clouds by aligning global features; then we match the local features to further refine the inaccurate alignments resulting from distribution variances. As global feature alignment requires the features to preserve the poses of input point clouds and local feature matching expects the features to be invariant to these poses, we propose an SE(3)-equivariant feature extractor to simultaneously generate two types of features. In this feature extractor, representations preserving the poses are first encoded by our novel SE(3)-equivariant network and then converted into pose-invariant ones by a pose-detaching module. Experiments demonstrate that our proposed method increases the recall rate by 20% compared to state-of-the-art methods when facing both pose differences and distribution variances.
Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Sep 27, 2022
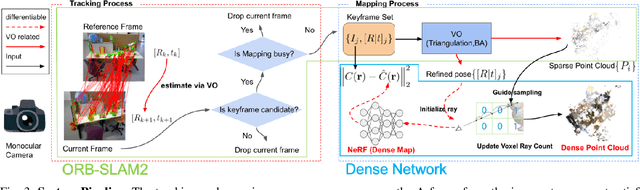

A spatial AI that can perform complex tasks through visual signals and cooperate with humans is highly anticipated. To achieve this, we need a visual SLAM that easily adapts to new scenes without pre-training and generates dense maps for downstream tasks in real-time. None of the previous learning-based and non-learning-based visual SLAMs satisfy all needs due to the intrinsic limitations of their components. In this work, we develop a visual SLAM named Orbeez-SLAM, which successfully collaborates with implicit neural representation (NeRF) and visual odometry to achieve our goals. Moreover, Orbeez-SLAM can work with the monocular camera since it only needs RGB inputs, making it widely applicable to the real world. We validate its effectiveness on various challenging benchmarks. Results show that our SLAM is up to 800x faster than the strong baseline with superior rendering outcomes.
OCID-Ref: A 3D Robotic Dataset with Embodied Language for Clutter Scene Grounding
Mar 13, 2021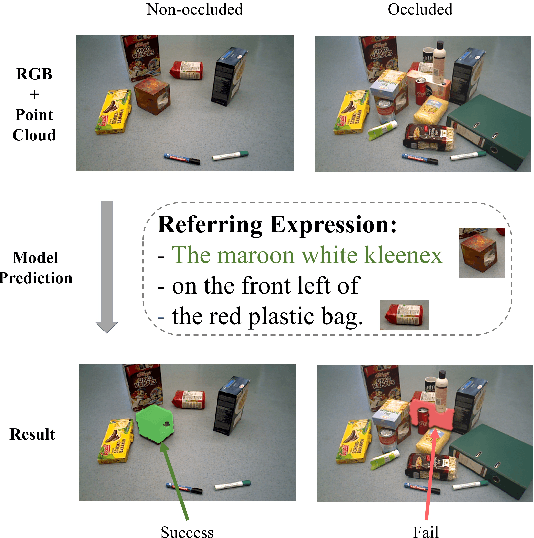

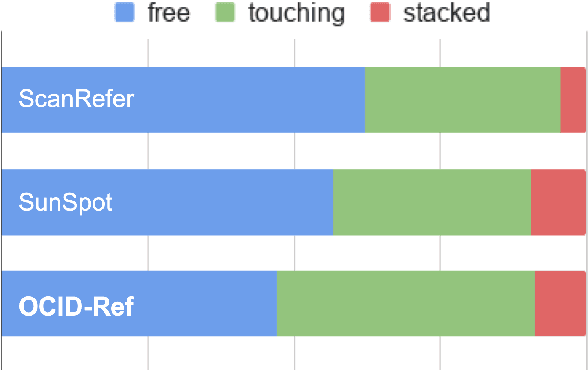

To effectively apply robots in working environments and assist humans, it is essential to develop and evaluate how visual grounding (VG) can affect machine performance on occluded objects. However, current VG works are limited in working environments, such as offices and warehouses, where objects are usually occluded due to space utilization issues. In our work, we propose a novel OCID-Ref dataset featuring a referring expression segmentation task with referring expressions of occluded objects. OCID-Ref consists of 305,694 referring expressions from 2,300 scenes with providing RGB image and point cloud inputs. To resolve challenging occlusion issues, we argue that it's crucial to take advantage of both 2D and 3D signals to resolve challenging occlusion issues. Our experimental results demonstrate the effectiveness of aggregating 2D and 3D signals but referring to occluded objects still remains challenging for the modern visual grounding systems. OCID-Ref is publicly available at https://github.com/lluma/OCID-Ref