 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuRAL: Multi-Scale Region-based Active Learning for Object Detection
Mar 29, 2023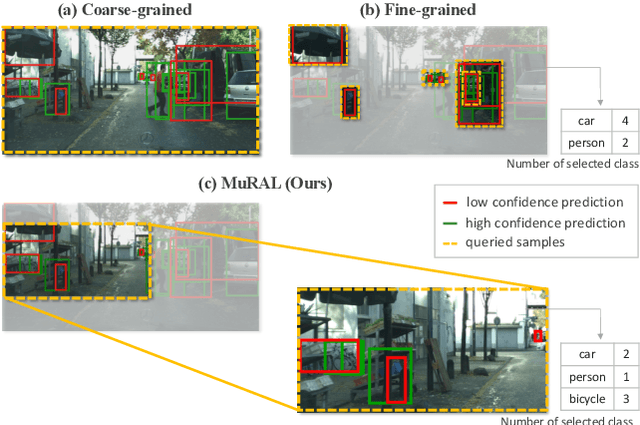
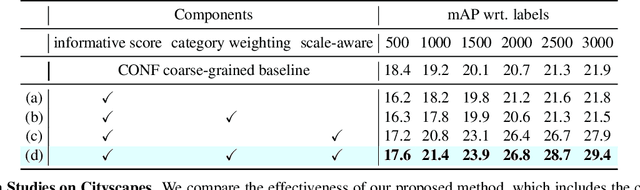
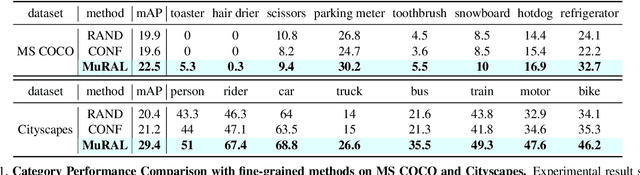

Obtaining large-scale labeled object detection dataset can be costly and time-consuming, as it involves annotating images with bounding boxes and class labels. Thus, some specialized active learning methods have been proposed to reduce the cost by selecting either coarse-grained samples or fine-grained instances from unlabeled data for labeling. However, the former approaches suffer from redundant labeling, while the latter methods generally lead to training instability and sampling bias. To address these challenges, we propose a novel approach called Multi-scale Region-based Active Learning (MuRAL) for object detection. MuRAL identifies informative regions of various scales to reduce annotation costs for well-learned objects and improve training performance. The informative region score is designed to consider both the predicted confidence of instances and the distribution of each object category, enabling our method to focus more on difficult-to-detect classes. Moreover, MuRAL employs a scale-aware selection strategy that ensures diverse regions are selected from different scales for labeling and downstream finetuning, which enhances training stability. Our proposed method surpasses all existing coarse-grained and fine-grained baselines on Cityscapes and MS COCO datasets, and demonstrates significant improvement in difficult category performance.
ADeADA: Adaptive Density-aware Active Domain Adaptation for Semantic Segmentation
Feb 15, 2022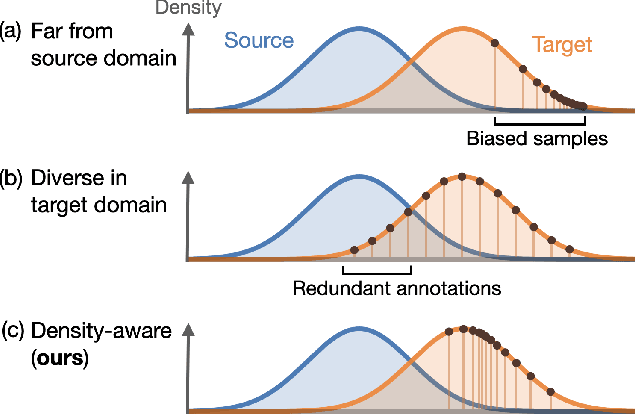
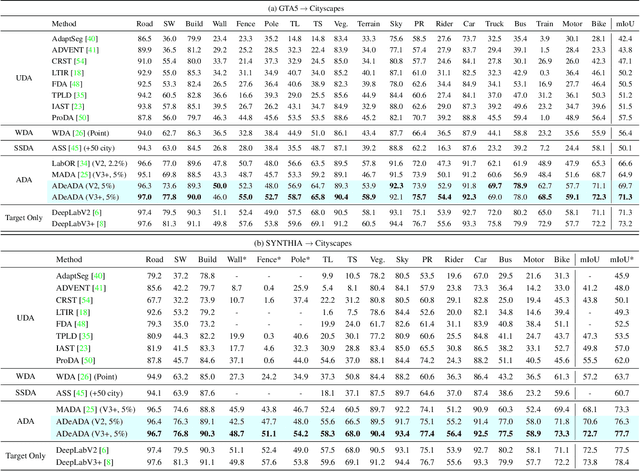
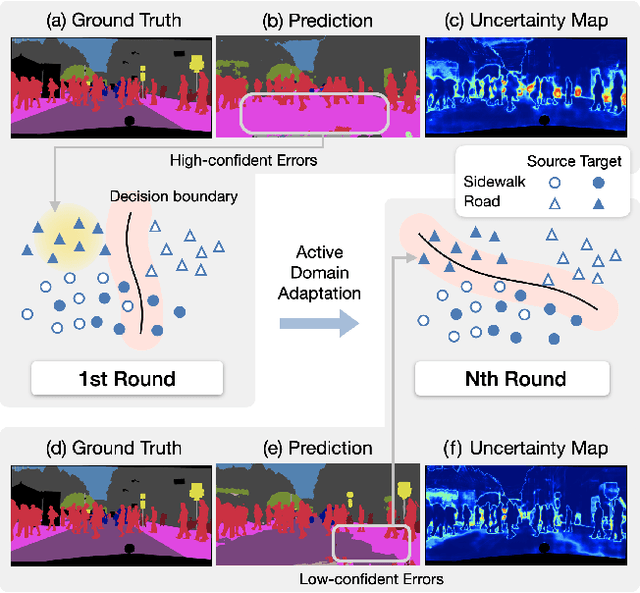
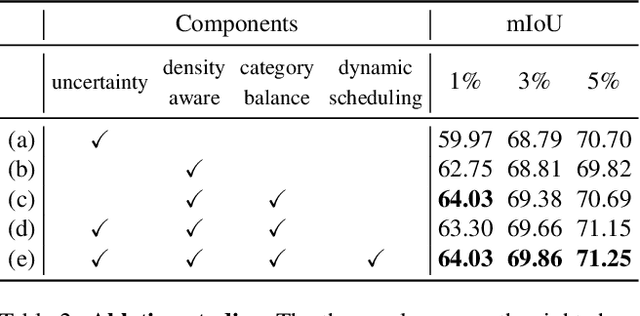
In the field of domain adaptation, a trade-off exists between the model performance and the number of target domain annotations. Active learning, maximizing model performance with few informative labeled data, comes in handy for such a scenario. In this work, we present ADeADA, a general active domain adaptation framework for semantic segmentation. To adapt the model to the target domain with minimum queried labels, we propose acquiring labels of the samples with high probability density in the target domain yet with low probability density in the source domain, complementary to the existing source domain labeled data. To further facilitate the label efficiency, we design an adaptive budget allocation policy, which dynamically balances the labeling budgets among different categories as well as between density-aware and uncertainty-based methods. Extensive experiments show that our method outperforms existing active learning and domain adaptation baselines on two benchmarks, GTA5 -> Cityscapes and SYNTHIA -> Cityscapes. With less than 5% target domain annotations, our method reaches comparable results with that of full supervision.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021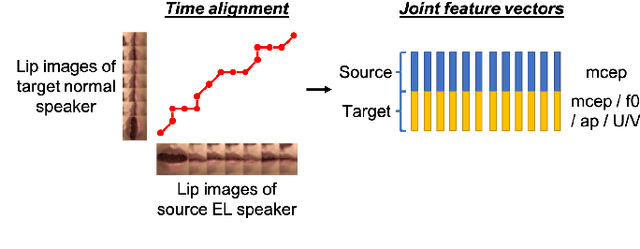
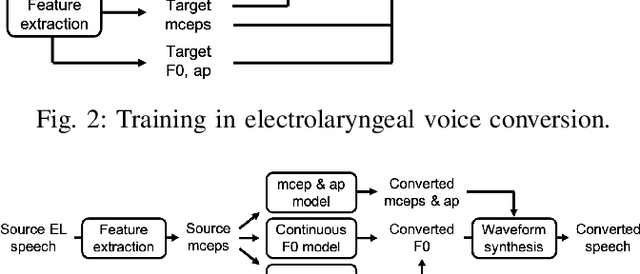
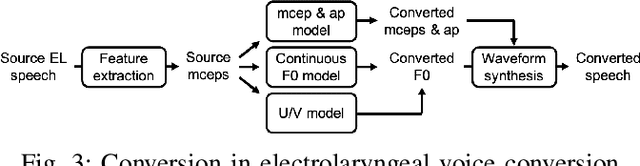
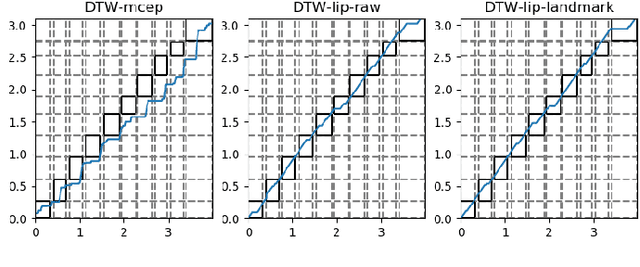
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.