 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Blurry to Believable: Enhancing Low-quality Talking Heads with 3D Generative Priors
Feb 05, 2026Creating high-fidelity, animatable 3D talking heads is crucial for immersive applications, yet often hindered by the prevalence of low-quality image or video sources, which yield poor 3D reconstructions. In this paper, we introduce SuperHead, a novel framework for enhancing low-resolution, animatable 3D head avatars. The core challenge lies in synthesizing high-quality geometry and textures, while ensuring both 3D and temporal consistency during animation and preserving subject identity. Despite recent progress in image, video and 3D-based super-resolution (SR), existing SR techniques are ill-equipped to handle dynamic 3D inputs. To address this, SuperHead leverages the rich priors from pre-trained 3D generative models via a novel dynamics-aware 3D inversion scheme. This process optimizes the latent representation of the generative model to produce a super-resolved 3D Gaussian Splatting (3DGS) head model, which is subsequently rigged to an underlying parametric head model (e.g., FLAME) for animation. The inversion is jointly supervised using a sparse collection of upscaled 2D face renderings and corresponding depth maps, captured from diverse facial expressions and camera viewpoints, to ensure realism under dynamic facial motions. Experiments demonstrate that SuperHead generates avatars with fine-grained facial details under dynamic motions, significantly outperforming baseline methods in visual quality.
ADeADA: Adaptive Density-aware Active Domain Adaptation for Semantic Segmentation
Feb 15, 2022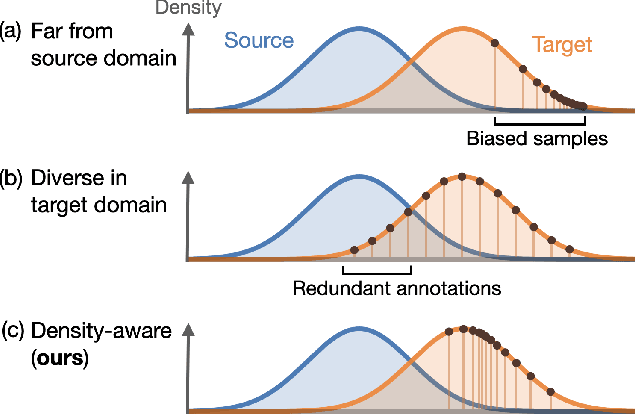
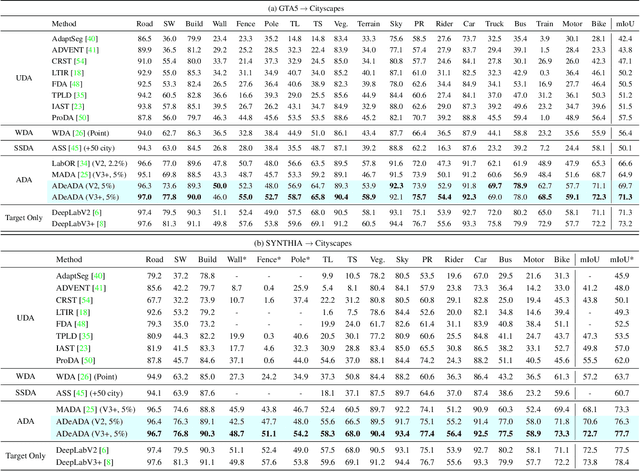
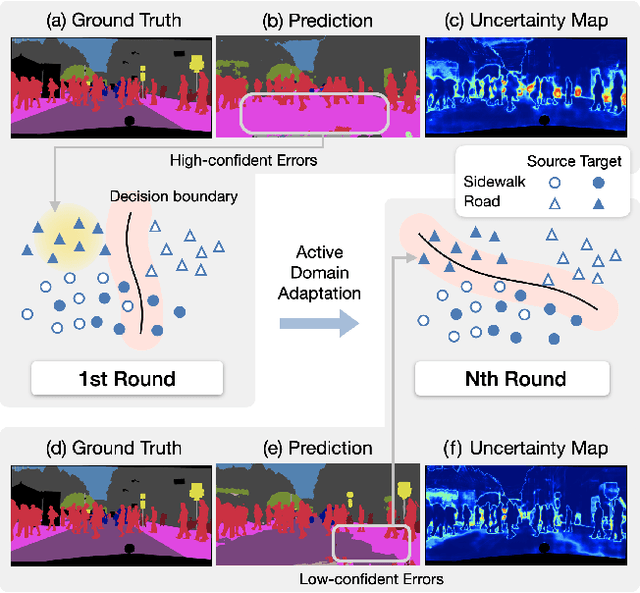
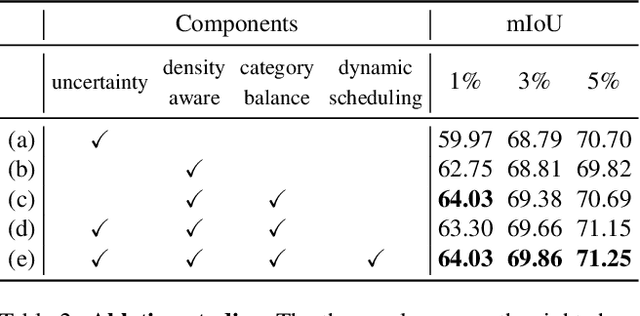
In the field of domain adaptation, a trade-off exists between the model performance and the number of target domain annotations. Active learning, maximizing model performance with few informative labeled data, comes in handy for such a scenario. In this work, we present ADeADA, a general active domain adaptation framework for semantic segmentation. To adapt the model to the target domain with minimum queried labels, we propose acquiring labels of the samples with high probability density in the target domain yet with low probability density in the source domain, complementary to the existing source domain labeled data. To further facilitate the label efficiency, we design an adaptive budget allocation policy, which dynamically balances the labeling budgets among different categories as well as between density-aware and uncertainty-based methods. Extensive experiments show that our method outperforms existing active learning and domain adaptation baselines on two benchmarks, GTA5 -> Cityscapes and SYNTHIA -> Cityscapes. With less than 5% target domain annotations, our method reaches comparable results with that of full supervision.