 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGHair: Compact Gaussian Hair Reconstruction with Card Clustering
Apr 04, 2026We present a compact pipeline for high-fidelity hair reconstruction from multi-view images. While recent 3D Gaussian Splatting (3DGS) methods achieve realistic results, they often require millions of primitives, leading to high storage and rendering costs. Observing that hair exhibits structural and visual similarities across a hairstyle, we cluster strands into representative hair cards and group these into shared texture codebooks. Our approach integrates this structure with 3DGS rendering, significantly reducing reconstruction time and storage while maintaining comparable visual quality. In addition, we propose a generative prior accelerated method to reconstruct the initial strand geometry from a set of images. Our experiments demonstrate a 4-fold reduction in strand reconstruction time and achieve comparable rendering performance with over 200x lower memory footprint.
In-the-Wild Camouflage Attack on Vehicle Detectors through Controllable Image Editing
Mar 19, 2026Deep neural networks (DNNs) have achieved remarkable success in computer vision but remain highly vulnerable to adversarial attacks. Among them, camouflage attacks manipulate an object's visible appearance to deceive detectors while remaining stealthy to humans. In this paper, we propose a new framework that formulates vehicle camouflage attacks as a conditional image-editing problem. Specifically, we explore both image-level and scene-level camouflage generation strategies, and fine-tune a ControlNet to synthesize camouflaged vehicles directly on real images. We design a unified objective that jointly enforces vehicle structural fidelity, style consistency, and adversarial effectiveness. Extensive experiments on the COCO and LINZ datasets show that our method achieves significantly stronger attack effectiveness, leading to more than 38% AP50 decrease, while better preserving vehicle structure and improving human-perceived stealthiness compared to existing approaches. Furthermore, our framework generalizes effectively to unseen black-box detectors and exhibits promising transferability to the physical world. Project page is available at https://humansensinglab.github.io/CtrlCamo
From Blurry to Believable: Enhancing Low-quality Talking Heads with 3D Generative Priors
Feb 05, 2026Creating high-fidelity, animatable 3D talking heads is crucial for immersive applications, yet often hindered by the prevalence of low-quality image or video sources, which yield poor 3D reconstructions. In this paper, we introduce SuperHead, a novel framework for enhancing low-resolution, animatable 3D head avatars. The core challenge lies in synthesizing high-quality geometry and textures, while ensuring both 3D and temporal consistency during animation and preserving subject identity. Despite recent progress in image, video and 3D-based super-resolution (SR), existing SR techniques are ill-equipped to handle dynamic 3D inputs. To address this, SuperHead leverages the rich priors from pre-trained 3D generative models via a novel dynamics-aware 3D inversion scheme. This process optimizes the latent representation of the generative model to produce a super-resolved 3D Gaussian Splatting (3DGS) head model, which is subsequently rigged to an underlying parametric head model (e.g., FLAME) for animation. The inversion is jointly supervised using a sparse collection of upscaled 2D face renderings and corresponding depth maps, captured from diverse facial expressions and camera viewpoints, to ensure realism under dynamic facial motions. Experiments demonstrate that SuperHead generates avatars with fine-grained facial details under dynamic motions, significantly outperforming baseline methods in visual quality.
LightSwitch: Multi-view Relighting with Material-guided Diffusion
Aug 08, 2025Recent approaches for 3D relighting have shown promise in integrating 2D image relighting generative priors to alter the appearance of a 3D representation while preserving the underlying structure. Nevertheless, generative priors used for 2D relighting that directly relight from an input image do not take advantage of intrinsic properties of the subject that can be inferred or cannot consider multi-view data at scale, leading to subpar relighting. In this paper, we propose Lightswitch, a novel finetuned material-relighting diffusion framework that efficiently relights an arbitrary number of input images to a target lighting condition while incorporating cues from inferred intrinsic properties. By using multi-view and material information cues together with a scalable denoising scheme, our method consistently and efficiently relights dense multi-view data of objects with diverse material compositions. We show that our 2D relighting prediction quality exceeds previous state-of-the-art relighting priors that directly relight from images. We further demonstrate that LightSwitch matches or outperforms state-of-the-art diffusion inverse rendering methods in relighting synthetic and real objects in as little as 2 minutes.
Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision
Jul 28, 2025Detecting vehicles in aerial imagery is a critical task with applications in traffic monitoring, urban planning, and defense intelligence. Deep learning methods have provided state-of-the-art (SOTA) results for this application. However, a significant challenge arises when models trained on data from one geographic region fail to generalize effectively to other areas. Variability in factors such as environmental conditions, urban layouts, road networks, vehicle types, and image acquisition parameters (e.g., resolution, lighting, and angle) leads to domain shifts that degrade model performance. This paper proposes a novel method that uses generative AI to synthesize high-quality aerial images and their labels, improving detector training through data augmentation. Our key contribution is the development of a multi-stage, multi-modal knowledge transfer framework utilizing fine-tuned latent diffusion models (LDMs) to mitigate the distribution gap between the source and target environments. Extensive experiments across diverse aerial imagery domains show consistent performance improvements in AP50 over supervised learning on source domain data, weakly supervised adaptation methods, unsupervised domain adaptation methods, and open-set object detectors by 4-23%, 6-10%, 7-40%, and more than 50%, respectively. Furthermore, we introduce two newly annotated aerial datasets from New Zealand and Utah to support further research in this field. Project page is available at: https://humansensinglab.github.io/AGenDA
GarmentCrafter: Progressive Novel View Synthesis for Single-View 3D Garment Reconstruction and Editing
Mar 11, 2025We introduce GarmentCrafter, a new approach that enables non-professional users to create and modify 3D garments from a single-view image. While recent advances in image generation have facilitated 2D garment design, creating and editing 3D garments remains challenging for non-professional users. Existing methods for single-view 3D reconstruction often rely on pre-trained generative models to synthesize novel views conditioning on the reference image and camera pose, yet they lack cross-view consistency, failing to capture the internal relationships across different views. In this paper, we tackle this challenge through progressive depth prediction and image warping to approximate novel views. Subsequently, we train a multi-view diffusion model to complete occluded and unknown clothing regions, informed by the evolving camera pose. By jointly inferring RGB and depth, GarmentCrafter enforces inter-view coherence and reconstructs precise geometries and fine details. Extensive experiments demonstrate that our method achieves superior visual fidelity and inter-view coherence compared to state-of-the-art single-view 3D garment reconstruction methods.
GAS: Generative Avatar Synthesis from a Single Image
Feb 10, 2025We introduce a generalizable and unified framework to synthesize view-consistent and temporally coherent avatars from a single image, addressing the challenging problem of single-image avatar generation. While recent methods employ diffusion models conditioned on human templates like depth or normal maps, they often struggle to preserve appearance information due to the discrepancy between sparse driving signals and the actual human subject, resulting in multi-view and temporal inconsistencies. Our approach bridges this gap by combining the reconstruction power of regression-based 3D human reconstruction with the generative capabilities of a diffusion model. The dense driving signal from the initial reconstructed human provides comprehensive conditioning, ensuring high-quality synthesis faithful to the reference appearance and structure. Additionally, we propose a unified framework that enables the generalization learned from novel pose synthesis on in-the-wild videos to naturally transfer to novel view synthesis. Our video-based diffusion model enhances disentangled synthesis with high-quality view-consistent renderings for novel views and realistic non-rigid deformations in novel pose animation. Results demonstrate the superior generalization ability of our method across in-domain and out-of-domain in-the-wild datasets. Project page: https://humansensinglab.github.io/GAS/
LlaMADRS: Prompting Large Language Models for Interview-Based Depression Assessment
Jan 07, 2025This study introduces LlaMADRS, a novel framework leveraging open-source Large Language Models (LLMs) to automate depression severity assessment using the Montgomery-Asberg Depression Rating Scale (MADRS). We employ a zero-shot prompting strategy with carefully designed cues to guide the model in interpreting and scoring transcribed clinical interviews. Our approach, tested on 236 real-world interviews from the Context-Adaptive Multimodal Informatics (CAMI) dataset, demonstrates strong correlations with clinician assessments. The Qwen 2.5--72b model achieves near-human level agreement across most MADRS items, with Intraclass Correlation Coefficients (ICC) closely approaching those between human raters. We provide a comprehensive analysis of model performance across different MADRS items, highlighting strengths and current limitations. Our findings suggest that LLMs, with appropriate prompting, can serve as efficient tools for mental health assessment, potentially increasing accessibility in resource-limited settings. However, challenges remain, particularly in assessing symptoms that rely on non-verbal cues, underscoring the need for multimodal approaches in future work.
Texture- and Shape-based Adversarial Attacks for Vehicle Detection in Synthetic Overhead Imagery
Dec 20, 2024



Detecting vehicles in aerial images can be very challenging due to complex backgrounds, small resolution, shadows, and occlusions. Despite the effectiveness of SOTA detectors such as YOLO, they remain vulnerable to adversarial attacks (AAs), compromising their reliability. Traditional AA strategies often overlook the practical constraints of physical implementation, focusing solely on attack performance. Our work addresses this issue by proposing practical implementation constraints for AA in texture and/or shape. These constraints include pixelation, masking, limiting the color palette of the textures, and constraining the shape modifications. We evaluated the proposed constraints through extensive experiments using three widely used object detector architectures, and compared them to previous works. The results demonstrate the effectiveness of our solutions and reveal a trade-off between practicality and performance. Additionally, we introduce a labeled dataset of overhead images featuring vehicles of various categories. We will make the code/dataset public upon paper acceptance.
Unsupervised Model Diagnosis
Oct 08, 2024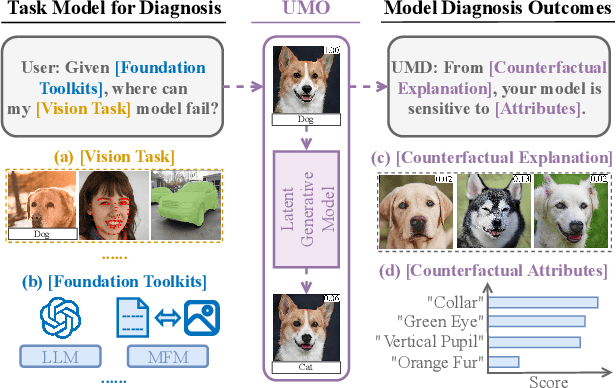

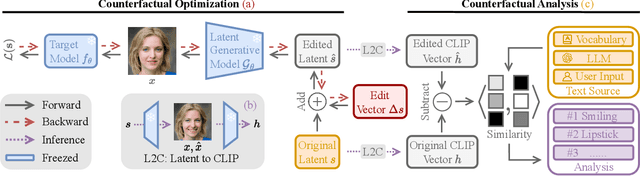
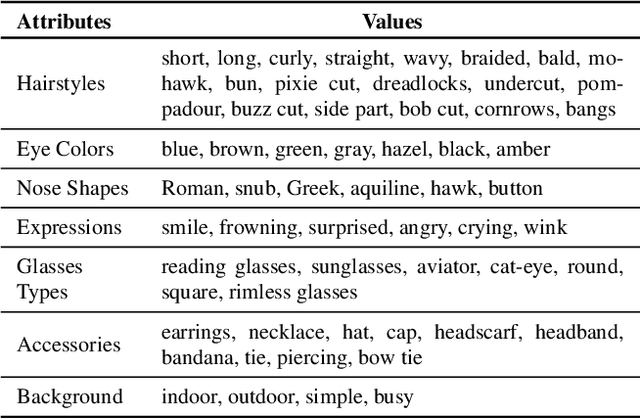
Ensuring model explainability and robustness is essential for reliable deployment of deep vision systems. Current methods for evaluating robustness rely on collecting and annotating extensive test sets. While this is common practice, the process is labor-intensive and expensive with no guarantee of sufficient coverage across attributes of interest. Recently, model diagnosis frameworks have emerged leveraging user inputs (e.g., text) to assess the vulnerability of the model. However, such dependence on human can introduce bias and limitation given the domain knowledge of particular users. This paper proposes Unsupervised Model Diagnosis (UMO), that leverages generative models to produce semantic counterfactual explanations without any user guidance. Given a differentiable computer vision model (i.e., the target model), UMO optimizes for the most counterfactual directions in a generative latent space. Our approach identifies and visualizes changes in semantics, and then matches these changes to attributes from wide-ranging text sources, such as dictionaries or language models. We validate the framework on multiple vision tasks (e.g., classification, segmentation, keypoint detection). Extensive experiments show that our unsupervised discovery of semantic directions can correctly highlight spurious correlations and visualize the failure mode of target models without any human intervention.