 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Data Diagnosis and Debiasing with Concept Graphs
Sep 26, 2024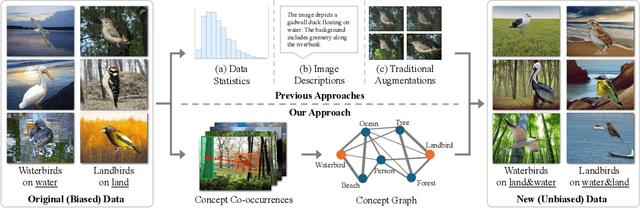
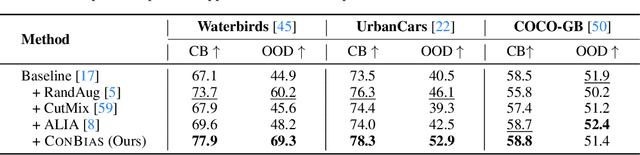
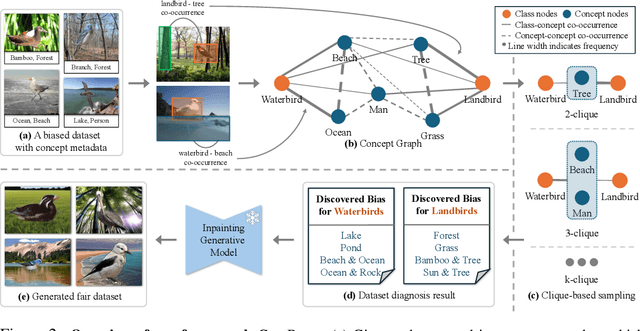

The widespread success of deep learning models today is owed to the curation of extensive datasets significant in size and complexity. However, such models frequently pick up inherent biases in the data during the training process, leading to unreliable predictions. Diagnosing and debiasing datasets is thus a necessity to ensure reliable model performance. In this paper, we present CONBIAS, a novel framework for diagnosing and mitigating Concept co-occurrence Biases in visual datasets. CONBIAS represents visual datasets as knowledge graphs of concepts, enabling meticulous analysis of spurious concept co-occurrences to uncover concept imbalances across the whole dataset. Moreover, we show that by employing a novel clique-based concept balancing strategy, we can mitigate these imbalances, leading to enhanced performance on downstream tasks. Extensive experiments show that data augmentation based on a balanced concept distribution augmented by CONBIAS improves generalization performance across multiple datasets compared to state-of-the-art methods. We will make our code and data publicly available.
ExMap: Leveraging Explainability Heatmaps for Unsupervised Group Robustness to Spurious Correlations
Mar 20, 2024



Group robustness strategies aim to mitigate learned biases in deep learning models that arise from spurious correlations present in their training datasets. However, most existing methods rely on the access to the label distribution of the groups, which is time-consuming and expensive to obtain. As a result, unsupervised group robustness strategies are sought. Based on the insight that a trained model's classification strategies can be inferred accurately based on explainability heatmaps, we introduce ExMap, an unsupervised two stage mechanism designed to enhance group robustness in traditional classifiers. ExMap utilizes a clustering module to infer pseudo-labels based on a model's explainability heatmaps, which are then used during training in lieu of actual labels. Our empirical studies validate the efficacy of ExMap - We demonstrate that it bridges the performance gap with its supervised counterparts and outperforms existing partially supervised and unsupervised methods. Additionally, ExMap can be seamlessly integrated with existing group robustness learning strategies. Finally, we demonstrate its potential in tackling the emerging issue of multiple shortcut mitigation\footnote{Code available at \url{https://github.com/rwchakra/exmap}}.
Hubs and Hyperspheres: Reducing Hubness and Improving Transductive Few-shot Learning with Hyperspherical Embeddings
Mar 16, 2023



Distance-based classification is frequently used in transductive few-shot learning (FSL). However, due to the high-dimensionality of image representations, FSL classifiers are prone to suffer from the hubness problem, where a few points (hubs) occur frequently in multiple nearest neighbour lists of other points. Hubness negatively impacts distance-based classification when hubs from one class appear often among the nearest neighbors of points from another class, degrading the classifier's performance. To address the hubness problem in FSL, we first prove that hubness can be eliminated by distributing representations uniformly on the hypersphere. We then propose two new approaches to embed representations on the hypersphere, which we prove optimize a tradeoff between uniformity and local similarity preservation -- reducing hubness while retaining class structure. Our experiments show that the proposed methods reduce hubness, and significantly improves transductive FSL accuracy for a wide range of classifiers.
RC2020 Report: Learning De-biased Representations with Biased Representations
May 14, 2021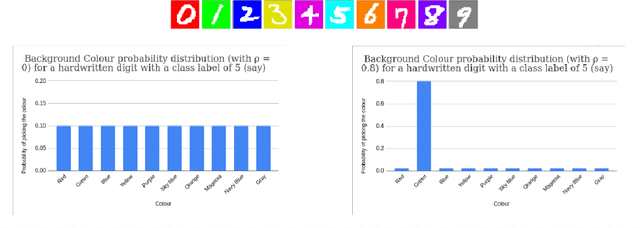
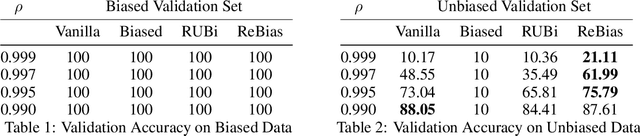
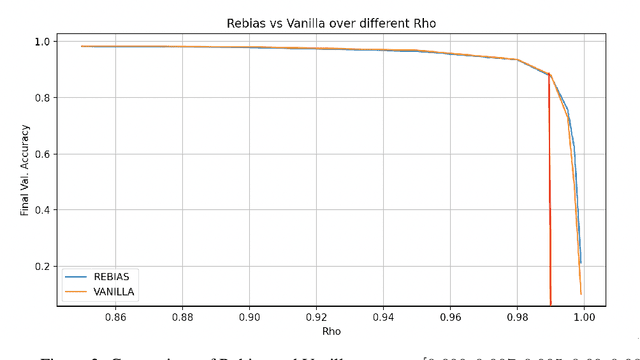
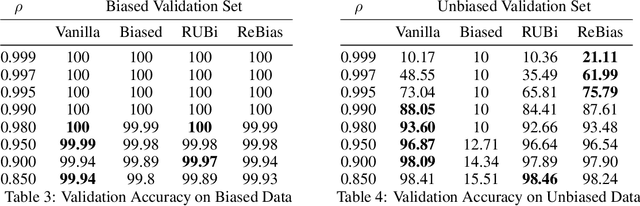
As part of the ML Reproducibility Challenge 2020, we investigated the ICML 2020 paper "Learning De-biased Representations with Biased Representations" by Bahng et al., where the authors formalize and attempt to tackle the so called "cross bias generalization" problem with a new approach they introduce called ReBias. This report contains results of our attempts at reproducing the work in the application area of Image Recognition, specifically on the datasets biased MNIST and ImageNet. We compare ReBias with other methods - Vanilla, Biased, RUBi (as implemented by the authors), and conclude with a discussion concerning the validity of the claims made by the paper. We were able to reproduce results reported for the biased MNIST dataset to within 1% of the original values reported in the paper. Like the authors, we report results averaged over 3 runs. However, in a later section, we provide some additional results that appear to weaken the central claim of the paper with regards to the biased MNIST dataset. We were not able to reproduce results for ImageNet as in the original paper, but based on communication with the authors, provide a discussion as to the reasons for the same. This work attempts to be useful to other researchers aiming to use ReBias for their own research purposes, advising on certain possible pitfalls that may be encountered in the process.
A Review and Refinement of Surprise Adequacy
Mar 10, 2021
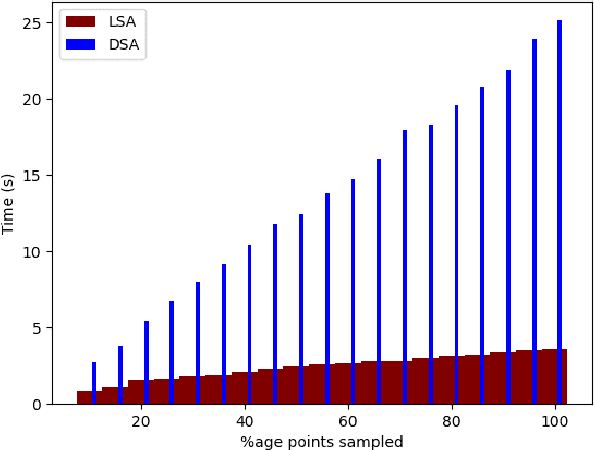
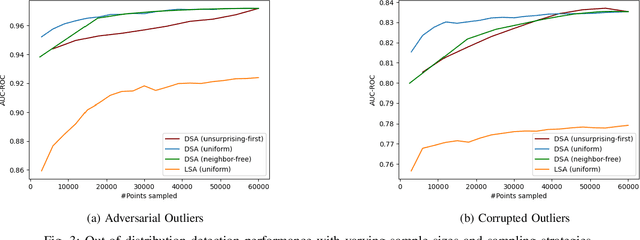
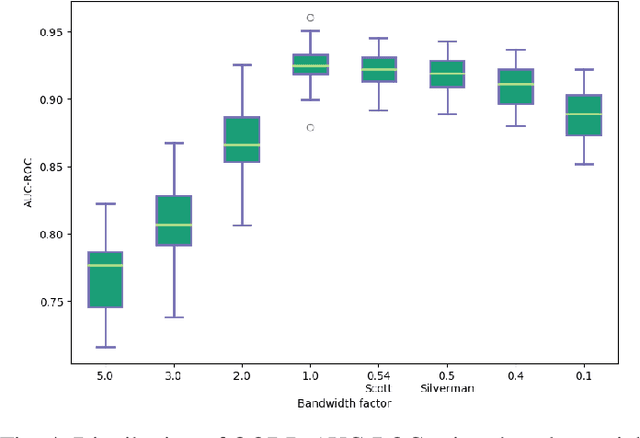
Surprise Adequacy (SA) is one of the emerging and most promising adequacy criteria for Deep Learning (DL) testing. As an adequacy criterion, it has been used to assess the strength of DL test suites. In addition, it has also been used to find inputs to a Deep Neural Network (DNN) which were not sufficiently represented in the training data, or to select samples for DNN retraining. However, computation of the SA metric for a test suite can be prohibitively expensive, as it involves a quadratic number of distance calculations. Hence, we developed and released a performance-optimized, but functionally equivalent, implementation of SA, reducing the evaluation time by up to 97\%. We also propose refined variants of the SA omputation algorithm, aiming to further increase the evaluation speed. We then performed an empirical study on MNIST, focused on the out-of-distribution detection capabilities of SA, which allowed us to reproduce parts of the results presented when SA was first released. The experiments show that our refined variants are substantially faster than plain SA, while producing comparable outcomes. Our experimental results exposed also an overlooked issue of SA: it can be highly sensitive to the non-determinism associated with the DNN training procedure.