 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOFE -- Neural Operator Function Embedding
May 12, 2026Most dimensionality reduction methods treat data as discrete point clouds, ignoring the continuous domain structure inherent to many real-world processes. To bridge this gap, we introduce Neural Operator Function Embedding (NOFE), a domain-aware framework for continuous dimensionality reduction. NOFE learns function-to-function mappings via a Graph Kernel Operator, enabling mesh-free evaluation at arbitrary query locations independent of input discretization. We establish NOFE as approximation of sheaf-to-sheaf mappings, generalizing Sheaf Neural Networks to continuous domains. We evaluate NOFE across different datasets, comparing it against PCA, t-SNE, and UMAP. Our results demonstrate that NOFE significantly outperforms baselines in local structure preservation, achieving a local Stress of 0.111 compared to 0.398 for PCA, 0.773 for t-SNE, and 0.791 for UMAP for the ERA5 climate reanalysis dataset. NOFE also exhibits robust sampling independence, reducing the Patch Stitching Error by up to $20.0\times$ relative to UMAP (59.0 vs. 267.6 under regional normalization) and ensuring consistency across disjoint domain patches. While maintaining competitive global structure preservation (Stress-1: 0.379 vs. PCA's 0.268), NOFE resolves fine-grained structures and produces smooth, consistent embeddings that generalize across varying sample densities, addressing key limitations of discrete reduction methods.
REPEAT: Improving Uncertainty Estimation in Representation Learning Explainability
Dec 11, 2024Incorporating uncertainty is crucial to provide trustworthy explanations of deep learning models. Recent works have demonstrated how uncertainty modeling can be particularly important in the unsupervised field of representation learning explainable artificial intelligence (R-XAI). Current R-XAI methods provide uncertainty by measuring variability in the importance score. However, they fail to provide meaningful estimates of whether a pixel is certainly important or not. In this work, we propose a new R-XAI method called REPEAT that addresses the key question of whether or not a pixel is \textit{certainly} important. REPEAT leverages the stochasticity of current R-XAI methods to produce multiple estimates of importance, thus considering each pixel in an image as a Bernoulli random variable that is either important or unimportant. From these Bernoulli random variables we can directly estimate the importance of a pixel and its associated certainty, thus enabling users to determine certainty in pixel importance. Our extensive evaluation shows that REPEAT gives certainty estimates that are more intuitive, better at detecting out-of-distribution data, and more concise.
Prototypical Self-Explainable Models Without Re-training
Dec 13, 2023Explainable AI (XAI) has unfolded in two distinct research directions with, on the one hand, post-hoc methods that explain the predictions of a pre-trained black-box model and, on the other hand, self-explainable models (SEMs) which are trained directly to provide explanations alongside their predictions. While the latter is preferred in most safety-critical scenarios, post-hoc approaches have received the majority of attention until now, owing to their simplicity and ability to explain base models without retraining. Current SEMs instead, require complex architectures and heavily regularized loss functions, thus necessitating specific and costly training. To address this shortcoming and facilitate wider use of SEMs, we propose a simple yet efficient universal method called KMEx (K-Means Explainer), which can convert any existing pre-trained model into a prototypical SEM. The motivation behind KMEx is to push towards more transparent deep learning-based decision-making via class-prototype-based explanations that are guaranteed to be diverse and trustworthy without retraining the base model. We compare models obtained from KMEx to state-of-the-art SEMs using an extensive qualitative evaluation to highlight the strengths and weaknesses of each model, further paving the way toward a more reliable and objective evaluation of SEMs.
View it like a radiologist: Shifted windows for deep learning augmentation of CT images
Nov 25, 2023Deep learning has the potential to revolutionize medical practice by automating and performing important tasks like detecting and delineating the size and locations of cancers in medical images. However, most deep learning models rely on augmentation techniques that treat medical images as natural images. For contrast-enhanced Computed Tomography (CT) images in particular, the signals producing the voxel intensities have physical meaning, which is lost during preprocessing and augmentation when treating such images as natural images. To address this, we propose a novel preprocessing and intensity augmentation scheme inspired by how radiologists leverage multiple viewing windows when evaluating CT images. Our proposed method, window shifting, randomly places the viewing windows around the region of interest during training. This approach improves liver lesion segmentation performance and robustness on images with poorly timed contrast agent. Our method outperforms classical intensity augmentations as well as the intensity augmentation pipeline of the popular nn-UNet on multiple datasets.
* 6 pages, 3 figures, accepted to MLSP 2023
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023


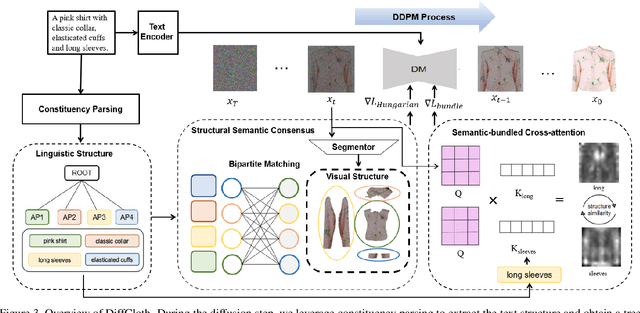
Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
Coordinate Transformer: Achieving Single-stage Multi-person Mesh Recovery from Videos
Aug 20, 2023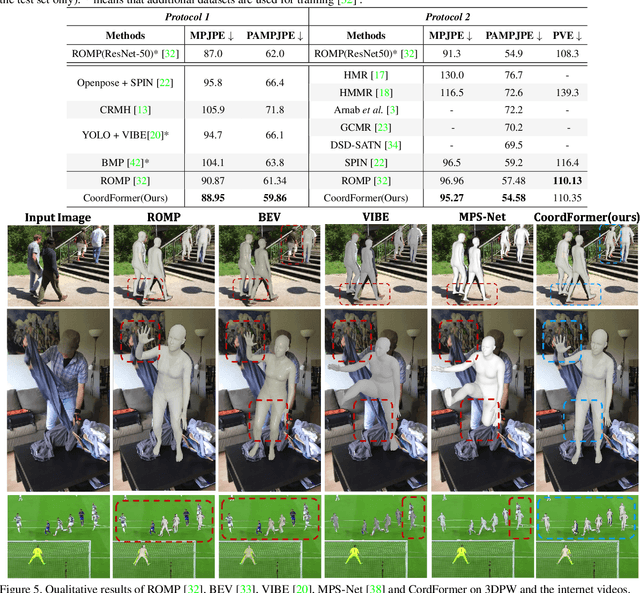
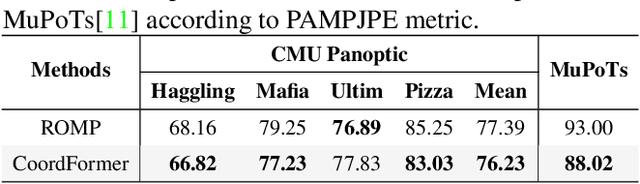

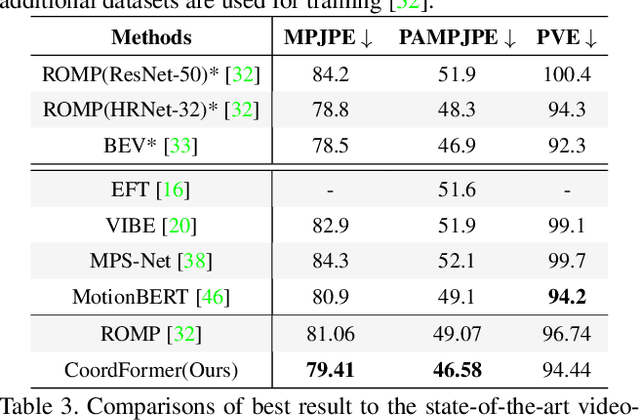
Multi-person 3D mesh recovery from videos is a critical first step towards automatic perception of group behavior in virtual reality, physical therapy and beyond. However, existing approaches rely on multi-stage paradigms, where the person detection and tracking stages are performed in a multi-person setting, while temporal dynamics are only modeled for one person at a time. Consequently, their performance is severely limited by the lack of inter-person interactions in the spatial-temporal mesh recovery, as well as by detection and tracking defects. To address these challenges, we propose the Coordinate transFormer (CoordFormer) that directly models multi-person spatial-temporal relations and simultaneously performs multi-mesh recovery in an end-to-end manner. Instead of partitioning the feature map into coarse-scale patch-wise tokens, CoordFormer leverages a novel Coordinate-Aware Attention to preserve pixel-level spatial-temporal coordinate information. Additionally, we propose a simple, yet effective Body Center Attention mechanism to fuse position information. Extensive experiments on the 3DPW dataset demonstrate that CoordFormer significantly improves the state-of-the-art, outperforming the previously best results by 4.2%, 8.8% and 4.7% according to the MPJPE, PAMPJPE, and PVE metrics, respectively, while being 40% faster than recent video-based approaches. The released code can be found at https://github.com/Li-Hao-yuan/CoordFormer.
On the Effects of Self-supervision and Contrastive Alignment in Deep Multi-view Clustering
Mar 17, 2023



Self-supervised learning is a central component in recent approaches to deep multi-view clustering (MVC). However, we find large variations in the development of self-supervision-based methods for deep MVC, potentially slowing the progress of the field. To address this, we present DeepMVC, a unified framework for deep MVC that includes many recent methods as instances. We leverage our framework to make key observations about the effect of self-supervision, and in particular, drawbacks of aligning representations with contrastive learning. Further, we prove that contrastive alignment can negatively influence cluster separability, and that this effect becomes worse when the number of views increases. Motivated by our findings, we develop several new DeepMVC instances with new forms of self-supervision. We conduct extensive experiments and find that (i) in line with our theoretical findings, contrastive alignments decreases performance on datasets with many views; (ii) all methods benefit from some form of self-supervision; and (iii) our new instances outperform previous methods on several datasets. Based on our results, we suggest several promising directions for future research. To enhance the openness of the field, we provide an open-source implementation of DeepMVC, including recent models and our new instances. Our implementation includes a consistent evaluation protocol, facilitating fair and accurate evaluation of methods and components.
Hubs and Hyperspheres: Reducing Hubness and Improving Transductive Few-shot Learning with Hyperspherical Embeddings
Mar 16, 2023



Distance-based classification is frequently used in transductive few-shot learning (FSL). However, due to the high-dimensionality of image representations, FSL classifiers are prone to suffer from the hubness problem, where a few points (hubs) occur frequently in multiple nearest neighbour lists of other points. Hubness negatively impacts distance-based classification when hubs from one class appear often among the nearest neighbors of points from another class, degrading the classifier's performance. To address the hubness problem in FSL, we first prove that hubness can be eliminated by distributing representations uniformly on the hypersphere. We then propose two new approaches to embed representations on the hypersphere, which we prove optimize a tradeoff between uniformity and local similarity preservation -- reducing hubness while retaining class structure. Our experiments show that the proposed methods reduce hubness, and significantly improves transductive FSL accuracy for a wide range of classifiers.
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022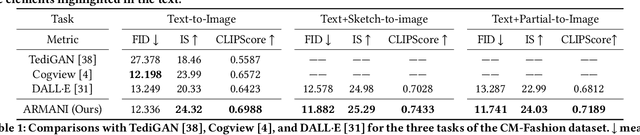

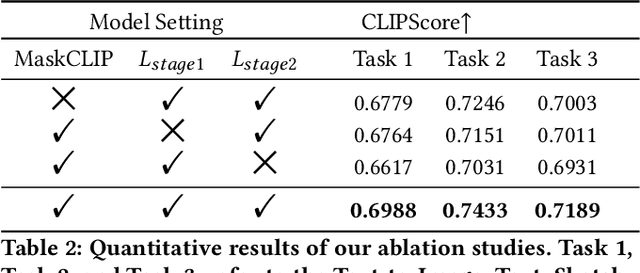
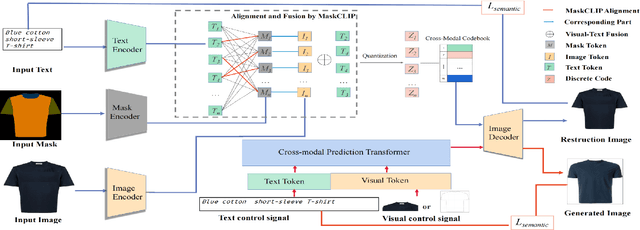
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
RELAX: Representation Learning Explainability
Dec 19, 2021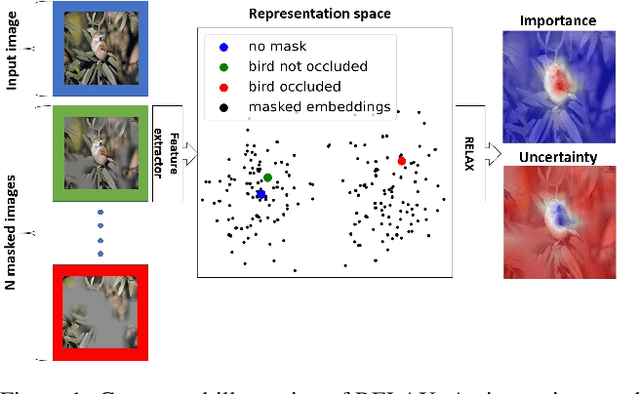

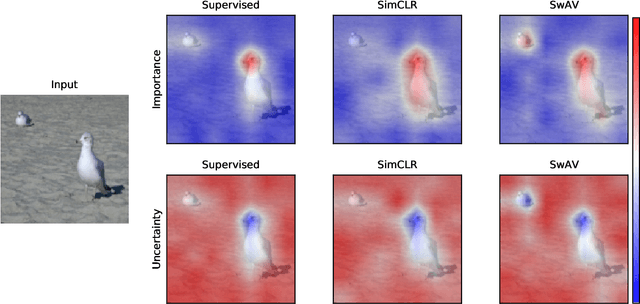
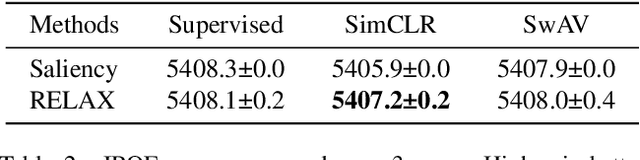
Despite the significant improvements that representation learning via self-supervision has led to when learning from unlabeled data, no methods exist that explain what influences the learned representation. We address this need through our proposed approach, RELAX, which is the first approach for attribution-based explanations of representations. Our approach can also model the uncertainty in its explanations, which is essential to produce trustworthy explanations. RELAX explains representations by measuring similarities in the representation space between an input and masked out versions of itself, providing intuitive explanations and significantly outperforming the gradient-based baseline. We provide theoretical interpretations of RELAX and conduct a novel analysis of feature extractors trained using supervised and unsupervised learning, providing insights into different learning strategies. Finally, we illustrate the usability of RELAX in multi-view clustering and highlight that incorporating uncertainty can be essential for providing low-complexity explanations, taking a crucial step towards explaining representations.