 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView it like a radiologist: Shifted windows for deep learning augmentation of CT images
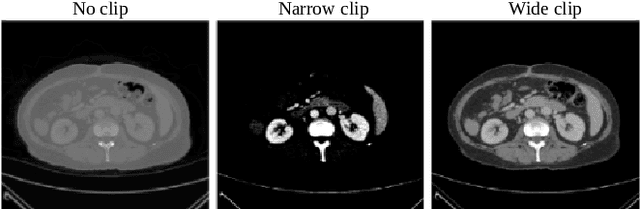
Nov 25, 2023Deep learning has the potential to revolutionize medical practice by automating and performing important tasks like detecting and delineating the size and locations of cancers in medical images. However, most deep learning models rely on augmentation techniques that treat medical images as natural images. For contrast-enhanced Computed Tomography (CT) images in particular, the signals producing the voxel intensities have physical meaning, which is lost during preprocessing and augmentation when treating such images as natural images. To address this, we propose a novel preprocessing and intensity augmentation scheme inspired by how radiologists leverage multiple viewing windows when evaluating CT images. Our proposed method, window shifting, randomly places the viewing windows around the region of interest during training. This approach improves liver lesion segmentation performance and robustness on images with poorly timed contrast agent. Our method outperforms classical intensity augmentations as well as the intensity augmentation pipeline of the popular nn-UNet on multiple datasets.
* 6 pages, 3 figures, accepted to MLSP 2023
A clinically motivated self-supervised approach for content-based image retrieval of CT liver images
Jul 11, 2022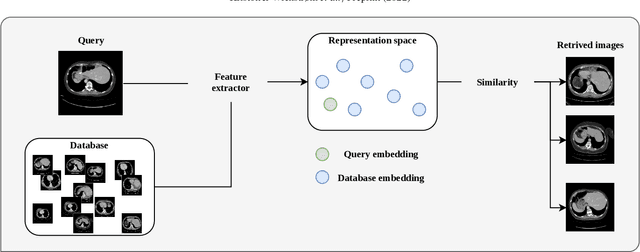
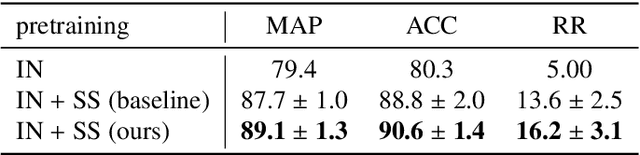
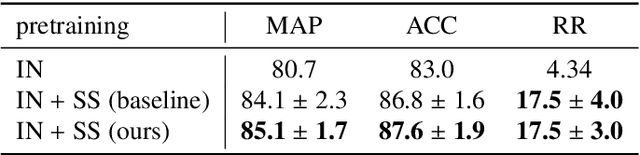
Deep learning-based approaches for content-based image retrieval (CBIR) of CT liver images is an active field of research, but suffers from some critical limitations. First, they are heavily reliant on labeled data, which can be challenging and costly to acquire. Second, they lack transparency and explainability, which limits the trustworthiness of deep CBIR systems. We address these limitations by (1) proposing a self-supervised learning framework that incorporates domain-knowledge into the training procedure and (2) providing the first representation learning explainability analysis in the context of CBIR of CT liver images. Results demonstrate improved performance compared to the standard self-supervised approach across several metrics, as well as improved generalisation across datasets. Further, we conduct the first representation learning explainability analysis in the context of CBIR, which reveals new insights into the feature extraction process. Lastly, we perform a case study with cross-examination CBIR that demonstrates the usability of our proposed framework. We believe that our proposed framework could play a vital role in creating trustworthy deep CBIR systems that can successfully take advantage of unlabeled data.