 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoX-AD: Self-Explainable Time Series Anomaly Detection and Characterization
Jun 11, 2026Recent advances in time series anomaly detection (TSAD) have highlighted the effectiveness of self-supervised classification-based approaches. These methods apply transformations to normal training samples, training a classifier to recognize transformation-specific patterns that help identify anomalies through increased classification errors. Despite their strong performance, a significant challenge is their lack of explainability, as they provide limited insight into the characteristics of flagged anomalies. To address this limitation, we propose ProtoX-AD, a prototype-based self-explainable framework for self-supervised TSAD. ProtoX-AD learns transformation-aware latent representations alongside interpretable prototypes, enabling both accurate anomaly detection and the identification of distinct anomalous profiles through prototype-based explanations. Additionally, it allows for systematic analysis of how transformation design impacts detection performance and explainability. Experimental results on synthetic and real-world datasets demonstrate that ProtoX-AD achieves detection performance comparable to its black-box counterparts while offering more consistent and semantically meaningful explanations than existing explainable baselines. Our code is publicly available at https://github.com/Aitorzan3/ProtoX-AD.
OVA-IB: One vs All Information Bottleneck for Multi-Modal Alignment
May 28, 2026Contrastive learning is effective for aligning paired views or modalities, but alignment beyond two modalities remains non-trivial and comparatively underexplored. Pairwise CLIP-style losses decompose multi-modal alignment into independent two-way comparisons and therefore do not explicitly model higher-order dependencies among multiple modalities. Recent beyond-pairwise objectives approach this problem from statistical or geometric perspectives, but arbitrary-modality alignment still lacks a principled criterion for defining what each modality should preserve and compress relative to the others. We revisit arbitrary-modality alignment through the Information Bottleneck principle. In multi-modal learning, sufficiency should preserve information predictable from the remaining modalities, while minimality should compress modality-specific information not supported by them. This naturally leads to a One-vs-All view, where each modality is characterized with respect to the remaining modalities. We propose OVA-IB, an Information Bottleneck framework for arbitrary-modality alignment. OVA-IB optimizes a tractable One-vs-All contrastive lower bound for sufficiency connected to a Dual Total Correlation-style objective, uses a parameter-free geometry-aware projection score, and derives a tractable upper-bound regularizer for minimality by bounding each representation's dependence on its own input with representation distributions induced by the remaining modalities. Experiments on classification, regression, modality-agnostic evaluation, and cross-modal retrieval benchmarks demonstrate strong and robust performance.
NOFE -- Neural Operator Function Embedding
May 12, 2026Most dimensionality reduction methods treat data as discrete point clouds, ignoring the continuous domain structure inherent to many real-world processes. To bridge this gap, we introduce Neural Operator Function Embedding (NOFE), a domain-aware framework for continuous dimensionality reduction. NOFE learns function-to-function mappings via a Graph Kernel Operator, enabling mesh-free evaluation at arbitrary query locations independent of input discretization. We establish NOFE as approximation of sheaf-to-sheaf mappings, generalizing Sheaf Neural Networks to continuous domains. We evaluate NOFE across different datasets, comparing it against PCA, t-SNE, and UMAP. Our results demonstrate that NOFE significantly outperforms baselines in local structure preservation, achieving a local Stress of 0.111 compared to 0.398 for PCA, 0.773 for t-SNE, and 0.791 for UMAP for the ERA5 climate reanalysis dataset. NOFE also exhibits robust sampling independence, reducing the Patch Stitching Error by up to $20.0\times$ relative to UMAP (59.0 vs. 267.6 under regional normalization) and ensuring consistency across disjoint domain patches. While maintaining competitive global structure preservation (Stress-1: 0.379 vs. PCA's 0.268), NOFE resolves fine-grained structures and produces smooth, consistent embeddings that generalize across varying sample densities, addressing key limitations of discrete reduction methods.
WindINR: Latent-State INR for Fast Local Wind Query and Correction in Complex Terrain
May 10, 2026Many downstream decisions in complex terrain require fast wind estimates at a small number of user-specified locations and heights for a given forecast valid time, rather than another dense forecast field on a fixed grid. We present WindINR, a latent-state implicit neural representation framework for continuous high-resolution local wind query and sparse-observation correction. WindINR maps static terrain descriptors, a low-resolution background field, and continuous query coordinates to a high-resolution wind state through a latent-conditioned decoder. To enable rapid inference-time correction, WindINR separates reusable representation learning from sample-specific latent-state correction. During training, a privileged encoder infers a reference latent state from high-resolution supervision, a deployable latent predictor estimates an initial latent state from inference-time inputs alone, and their discrepancies are summarized into a dataset-adaptive Gaussian prior over latent corrections. At inference time, within the WindINR module, network weights remain fixed and only the latent state is updated by minimizing a regularized correction objective using sparse observations and their uncertainty. In controlled OSSEs over the Senja region, including a UAV-aided approach scenario and random-observation robustness tests, WindINR improves local high-resolution wind estimates by updating only a compact latent state rather than the full network. The corrected representation remains continuously queryable at arbitrary coordinates and, in our CPU benchmark, yields about a $2.6\times$ online-correction speedup over full-network fine-tuning, suggesting a practical interface between kilometer-scale background products, sparse local observations, and wind queries in complex terrain.
Keypoint Counting Classifiers: Turning Vision Transformers into Self-Explainable Models Without Training
Dec 19, 2025
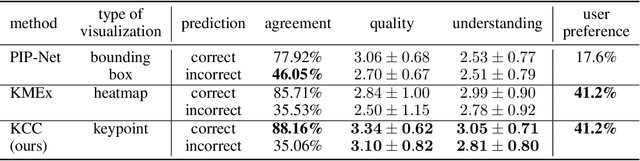

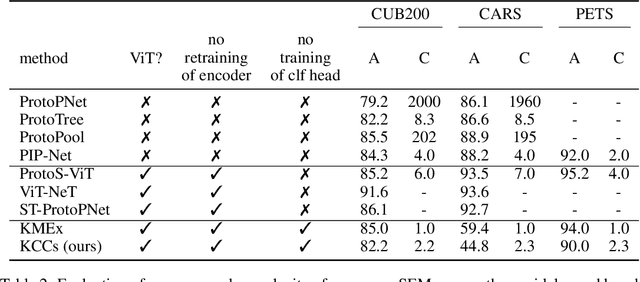
Current approaches for designing self-explainable models (SEMs) require complicated training procedures and specific architectures which makes them impractical. With the advance of general purpose foundation models based on Vision Transformers (ViTs), this impracticability becomes even more problematic. Therefore, new methods are necessary to provide transparency and reliability to ViT-based foundation models. In this work, we present a new method for turning any well-trained ViT-based model into a SEM without retraining, which we call Keypoint Counting Classifiers (KCCs). Recent works have shown that ViTs can automatically identify matching keypoints between images with high precision, and we build on these results to create an easily interpretable decision process that is inherently visualizable in the input. We perform an extensive evaluation which show that KCCs improve the human-machine communication compared to recent baselines. We believe that KCCs constitute an important step towards making ViT-based foundation models more transparent and reliable.
The Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
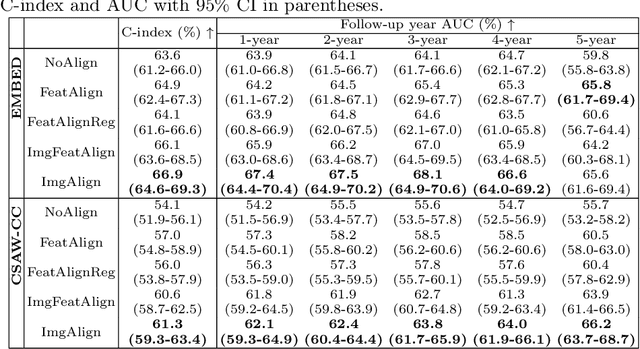
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging
Jul 03, 2025![Figure 1 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F5-Figure1-1.png&w=640&q=75)
![Figure 2 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F6-Figure2-1.png&w=640&q=75)
![Figure 3 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F9-Figure4-1.png&w=640&q=75)
Dynamic positron emission tomography (PET) and kinetic modeling are pivotal in advancing tracer development research in small animal studies. Accurate kinetic modeling requires precise input function estimation, traditionally achieved via arterial blood sampling. However, arterial cannulation in small animals like mice, involves intricate, time-consuming, and terminal procedures, precluding longitudinal studies. This work proposes a non-invasive, fully convolutional deep learning-based approach (FC-DLIF) to predict input functions directly from PET imaging, potentially eliminating the need for blood sampling in dynamic small-animal PET. The proposed FC-DLIF model includes a spatial feature extractor acting on the volumetric time frames of the PET sequence, extracting spatial features. These are subsequently further processed in a temporal feature extractor that predicts the arterial input function. The proposed approach is trained and evaluated using images and arterial blood curves from [$^{18}$F]FDG data using cross validation. Further, the model applicability is evaluated on imaging data and arterial blood curves collected using two additional radiotracers ([$^{18}$F]FDOPA, and [$^{68}$Ga]PSMA). The model was further evaluated on data truncated and shifted in time, to simulate shorter, and shifted, PET scans. The proposed FC-DLIF model reliably predicts the arterial input function with respect to mean squared error and correlation. Furthermore, the FC-DLIF model is able to predict the arterial input function even from truncated and shifted samples. The model fails to predict the AIF from samples collected using different radiotracers, as these are not represented in the training data. Our deep learning-based input function offers a non-invasive and reliable alternative to arterial blood sampling, proving robust and flexible to temporal shifts and different scan durations.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025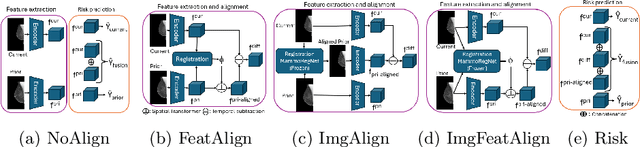
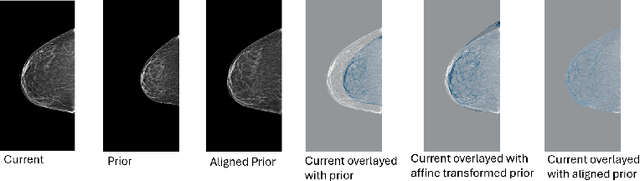

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
Aggregation of Dependent Expert Distributions in Multimodal Variational Autoencoders
May 02, 2025Multimodal learning with variational autoencoders (VAEs) requires estimating joint distributions to evaluate the evidence lower bound (ELBO). Current methods, the product and mixture of experts, aggregate single-modality distributions assuming independence for simplicity, which is an overoptimistic assumption. This research introduces a novel methodology for aggregating single-modality distributions by exploiting the principle of consensus of dependent experts (CoDE), which circumvents the aforementioned assumption. Utilizing the CoDE method, we propose a novel ELBO that approximates the joint likelihood of the multimodal data by learning the contribution of each subset of modalities. The resulting CoDE-VAE model demonstrates better performance in terms of balancing the trade-off between generative coherence and generative quality, as well as generating more precise log-likelihood estimations. CoDE-VAE further minimizes the generative quality gap as the number of modalities increases. In certain cases, it reaches a generative quality similar to that of unimodal VAEs, which is a desirable property that is lacking in most current methods. Finally, the classification accuracy achieved by CoDE-VAE is comparable to that of state-of-the-art multimodal VAE models.
From Colors to Classes: Emergence of Concepts in Vision Transformers
Mar 31, 2025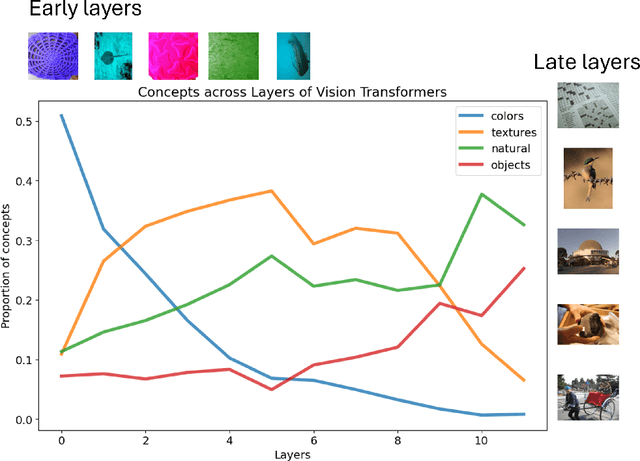
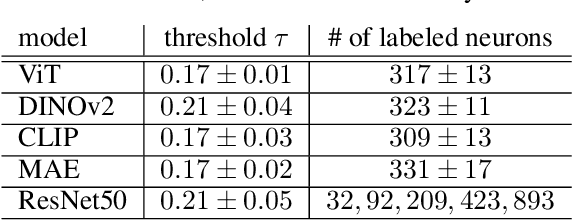
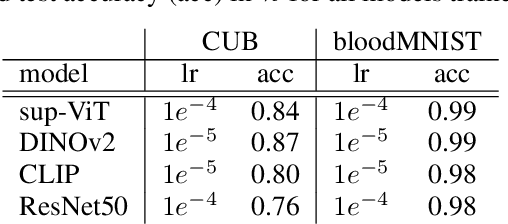
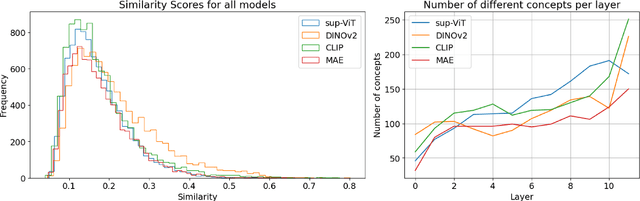
Vision Transformers (ViTs) are increasingly utilized in various computer vision tasks due to their powerful representation capabilities. However, it remains understudied how ViTs process information layer by layer. Numerous studies have shown that convolutional neural networks (CNNs) extract features of increasing complexity throughout their layers, which is crucial for tasks like domain adaptation and transfer learning. ViTs, lacking the same inductive biases as CNNs, can potentially learn global dependencies from the first layers due to their attention mechanisms. Given the increasing importance of ViTs in computer vision, there is a need to improve the layer-wise understanding of ViTs. In this work, we present a novel, layer-wise analysis of concepts encoded in state-of-the-art ViTs using neuron labeling. Our findings reveal that ViTs encode concepts with increasing complexity throughout the network. Early layers primarily encode basic features such as colors and textures, while later layers represent more specific classes, including objects and animals. As the complexity of encoded concepts increases, the number of concepts represented in each layer also rises, reflecting a more diverse and specific set of features. Additionally, different pretraining strategies influence the quantity and category of encoded concepts, with finetuning to specific downstream tasks generally reducing the number of encoded concepts and shifting the concepts to more relevant categories.