 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREPEAT: Improving Uncertainty Estimation in Representation Learning Explainability
Dec 11, 2024Incorporating uncertainty is crucial to provide trustworthy explanations of deep learning models. Recent works have demonstrated how uncertainty modeling can be particularly important in the unsupervised field of representation learning explainable artificial intelligence (R-XAI). Current R-XAI methods provide uncertainty by measuring variability in the importance score. However, they fail to provide meaningful estimates of whether a pixel is certainly important or not. In this work, we propose a new R-XAI method called REPEAT that addresses the key question of whether or not a pixel is \textit{certainly} important. REPEAT leverages the stochasticity of current R-XAI methods to produce multiple estimates of importance, thus considering each pixel in an image as a Bernoulli random variable that is either important or unimportant. From these Bernoulli random variables we can directly estimate the importance of a pixel and its associated certainty, thus enabling users to determine certainty in pixel importance. Our extensive evaluation shows that REPEAT gives certainty estimates that are more intuitive, better at detecting out-of-distribution data, and more concise.
Explaining time series models using frequency masking
Jun 19, 2024Time series data is fundamentally important for describing many critical domains such as healthcare, finance, and climate, where explainable models are necessary for safe automated decision-making. To develop eXplainable AI (XAI) in these domains therefore implies explaining salient information in the time series. Current methods for obtaining saliency maps assumes localized information in the raw input space. In this paper, we argue that the salient information of a number of time series is more likely to be localized in the frequency domain. We propose FreqRISE, which uses masking based methods to produce explanations in the frequency and time-frequency domain, which shows the best performance across a number of tasks.
Multi-view self-supervised learning for multivariate variable-channel time series
Jul 20, 2023



Labeling of multivariate biomedical time series data is a laborious and expensive process. Self-supervised contrastive learning alleviates the need for large, labeled datasets through pretraining on unlabeled data. However, for multivariate time series data, the set of input channels often varies between applications, and most existing work does not allow for transfer between datasets with different sets of input channels. We propose learning one encoder to operate on all input channels individually. We then use a message passing neural network to extract a single representation across channels. We demonstrate the potential of this method by pretraining our model on a dataset with six EEG channels and then fine-tuning it on a dataset with two different EEG channels. We compare models with and without the message passing neural network across different contrastive loss functions. We show that our method, combined with the TS2Vec loss, outperforms all other methods in most settings.
On convex conceptual regions in deep network representations
May 26, 2023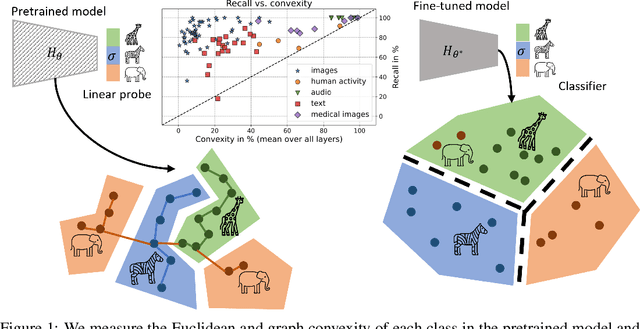
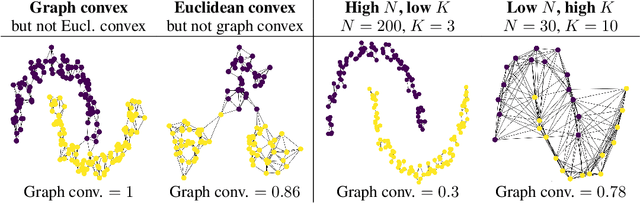

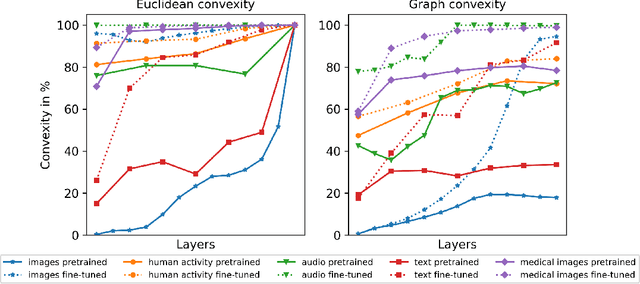
The current study of human-machine alignment aims at understanding the geometry of latent spaces and the correspondence to human representations. G\"ardenfors' conceptual spaces is a prominent framework for understanding human representations. Convexity of object regions in conceptual spaces is argued to promote generalizability, few-shot learning, and intersubject alignment. Based on these insights, we investigate the notion of convexity of concept regions in machine-learned latent spaces. We develop a set of tools for measuring convexity in sampled data and evaluate emergent convexity in layered representations of state-of-the-art deep networks. We show that convexity is robust to basic re-parametrization, hence, meaningful as a quality of machine-learned latent spaces. We find that approximate convexity is pervasive in neural representations in multiple application domains, including models of images, audio, human activity, text, and brain data. We measure convexity separately for labels (i.e., targets for fine-tuning) and other concepts. Generally, we observe that fine-tuning increases the convexity of label regions, while for more general concepts, it depends on the alignment of the concept with the fine-tuning objective. We find evidence that pre-training convexity of class label regions predicts subsequent fine-tuning performance.