 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Graph, Different Likelihoods: Calibration of Autoregressive Graph Generators via Permutation-Equivalent Encodings
Apr 07, 2026Autoregressive graph generators define likelihoods via a sequential construction process, but these likelihoods are only meaningful if they are consistent across all linearizations of the same graph. Segmented Eulerian Neighborhood Trails (SENT), a recent linearization method, converts graphs into sequences that can be perfectly decoded and efficiently processed by language models, but admit multiple equivalent linearizations of the same graph. We quantify violations in assigned negative log-likelihood (NLL) using the coefficient of variation across equivalent linearizations, which we call Linearization Uncertainty (LU). Training transformers under four linearization strategies on two datasets, we show that biased orderings achieve lower NLL on their native order but exhibit expected calibration error (ECE) two orders of magnitude higher under random permutation, indicating that these models have learned their training linearization rather than the underlying graph. On the molecular graph benchmark QM9, NLL for generated graphs is negatively correlated with molecular stability (AUC $=0.43$), while LU achieves AUC $=0.85$, suggesting that permutation-based evaluation provides a more reliable quality check for generated molecules. Code is available at https://github.com/lauritsf/linearization-uncertainty
Practical Deep Heteroskedastic Regression
Mar 02, 2026Uncertainty quantification (UQ) in deep learning regression is of wide interest, as it supports critical applications including sequential decision making and risk-sensitive tasks. In heteroskedastic regression, where the uncertainty of the target depends on the input, a common approach is to train a neural network that parameterizes the mean and the variance of the predictive distribution. Still, training deep heteroskedastic regression models poses practical challenges in the trade-off between uncertainty quantification and mean prediction, such as optimization difficulties, representation collapse, and variance overfitting. In this work we identify previously undiscussed fallacies and propose a simple and efficient procedure that addresses these challenges jointly by post-hoc fitting a variance model across the intermediate layers of a pretrained network on a hold-out dataset. We demonstrate that our method achieves on-par or state-of-the-art uncertainty quantification on several molecular graph datasets, without compromising mean prediction accuracy and remaining cheap to use at prediction time.
On Joint Regularization and Calibration in Deep Ensembles
Nov 07, 2025Deep ensembles are a powerful tool in machine learning, improving both model performance and uncertainty calibration. While ensembles are typically formed by training and tuning models individually, evidence suggests that jointly tuning the ensemble can lead to better performance. This paper investigates the impact of jointly tuning weight decay, temperature scaling, and early stopping on both predictive performance and uncertainty quantification. Additionally, we propose a partially overlapping holdout strategy as a practical compromise between enabling joint evaluation and maximizing the use of data for training. Our results demonstrate that jointly tuning the ensemble generally matches or improves performance, with significant variation in effect size across different tasks and metrics. We highlight the trade-offs between individual and joint optimization in deep ensemble training, with the overlapping holdout strategy offering an attractive practical solution. We believe our findings provide valuable insights and guidance for practitioners looking to optimize deep ensemble models. Code is available at: https://github.com/lauritsf/ensemble-optimality-gap
* 39 pages, 8 figures, 11 tables
Equivariant Neural Diffusion for Molecule Generation
Jun 12, 2025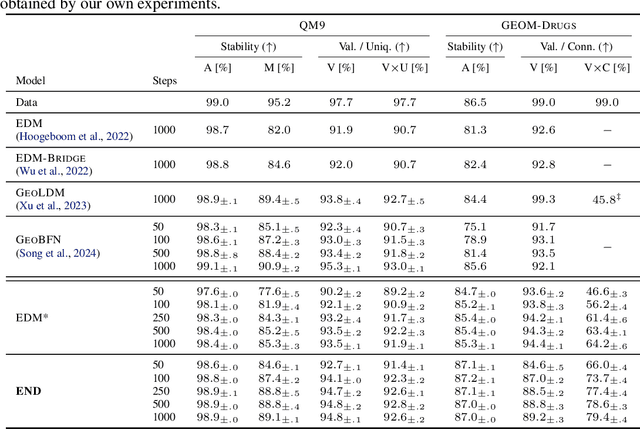
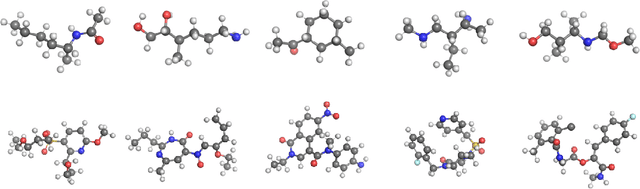
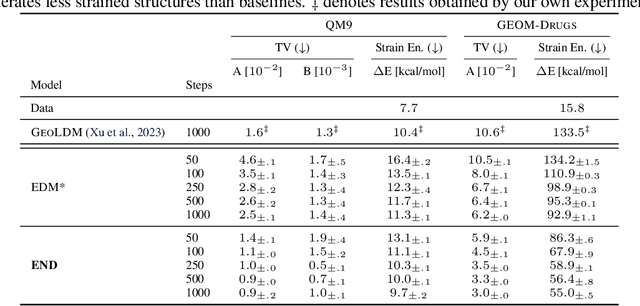
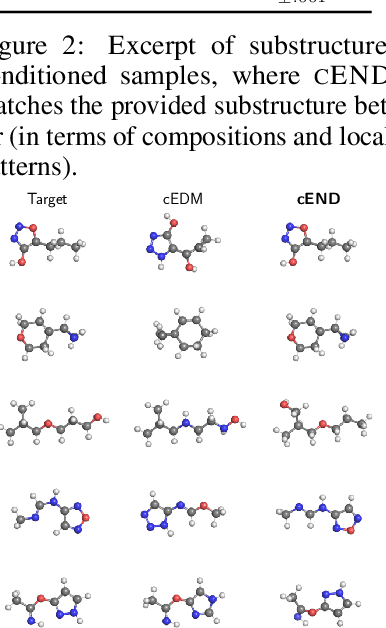
We introduce Equivariant Neural Diffusion (END), a novel diffusion model for molecule generation in 3D that is equivariant to Euclidean transformations. Compared to current state-of-the-art equivariant diffusion models, the key innovation in END lies in its learnable forward process for enhanced generative modelling. Rather than pre-specified, the forward process is parameterized through a time- and data-dependent transformation that is equivariant to rigid transformations. Through a series of experiments on standard molecule generation benchmarks, we demonstrate the competitive performance of END compared to several strong baselines for both unconditional and conditional generation.
On Local Posterior Structure in Deep Ensembles
Mar 17, 2025Bayesian Neural Networks (BNNs) often improve model calibration and predictive uncertainty quantification compared to point estimators such as maximum-a-posteriori (MAP). Similarly, deep ensembles (DEs) are also known to improve calibration, and therefore, it is natural to hypothesize that deep ensembles of BNNs (DE-BNNs) should provide even further improvements. In this work, we systematically investigate this across a number of datasets, neural network architectures, and BNN approximation methods and surprisingly find that when the ensembles grow large enough, DEs consistently outperform DE-BNNs on in-distribution data. To shine light on this observation, we conduct several sensitivity and ablation studies. Moreover, we show that even though DE-BNNs outperform DEs on out-of-distribution metrics, this comes at the cost of decreased in-distribution performance. As a final contribution, we open-source the large pool of trained models to facilitate further research on this topic.
Blind Equalization using a Variational Autoencoder with Second Order Volterra Channel Model
Oct 21, 2024Existing communication hardware is being exerted to its limits to accommodate for the ever increasing internet usage globally. This leads to non-linear distortion in the communication link that requires non-linear equalization techniques to operate the link at a reasonable bit error rate. This paper addresses the challenge of blind non-linear equalization using a variational autoencoder (VAE) with a second-order Volterra channel model. The VAE framework's costfunction, the evidence lower bound (ELBO), is derived for real-valued constellations and can be evaluated analytically without resorting to sampling techniques. We demonstrate the effectiveness of our approach through simulations on a synthetic Wiener-Hammerstein channel and a simulated intensity modulated direct detection (IM/DD) optical link. The results show significant improvements in equalization performance, compared to a VAE with linear channel assumptions, highlighting the importance of appropriate channel modeling in unsupervised VAE equalizer frameworks.
End-to-End Learning of Transmitter and Receiver Filters in Bandwidth Limited Fiber Optic Communication Systems
Sep 18, 2024This paper investigates the application of end-to-end (E2E) learning for joint optimization of pulse-shaper and receiver filter to reduce intersymbol interference (ISI) in bandwidth-limited communication systems. We investigate this in two numerical simulation models: 1) an additive white Gaussian noise (AWGN) channel with bandwidth limitation and 2) an intensity modulated direct detection (IM/DD) link employing an electro-absorption modulator. For both simulation models, we implement a wavelength division multiplexing (WDM) scheme to ensure that the learned filters adhere to the bandwidth constraints of the WDM channels. Our findings reveal that E2E learning greatly surpasses traditional single-sided transmitter pulse-shaper or receiver filter optimization methods, achieving significant performance gains in terms of symbol error rate with shorter filter lengths. These results suggest that E2E learning can decrease the complexity and enhance the performance of future high-speed optical communication systems.
Explaining time series models using frequency masking
Jun 19, 2024Time series data is fundamentally important for describing many critical domains such as healthcare, finance, and climate, where explainable models are necessary for safe automated decision-making. To develop eXplainable AI (XAI) in these domains therefore implies explaining salient information in the time series. Current methods for obtaining saliency maps assumes localized information in the raw input space. In this paper, we argue that the salient information of a number of time series is more likely to be localized in the frequency domain. We propose FreqRISE, which uses masking based methods to produce explanations in the frequency and time-frequency domain, which shows the best performance across a number of tasks.
End-to-End Learning of Pulse-Shaper and Receiver Filter in the Presence of Strong Intersymbol Interference
May 22, 2024

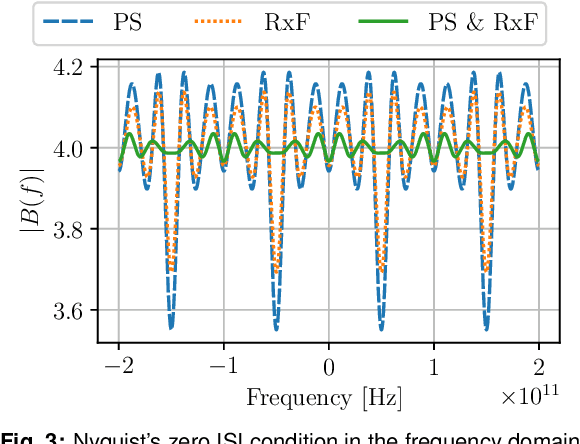

We numerically demonstrate that joint optimization of FIR based pulse-shaper and receiver filter results in an improved system performance, and shorter filter lengths (lower complexity), for 4-PAM 100 GBd IM/DD systems.
Coherent energy and force uncertainty in deep learning force fields
Dec 07, 2023
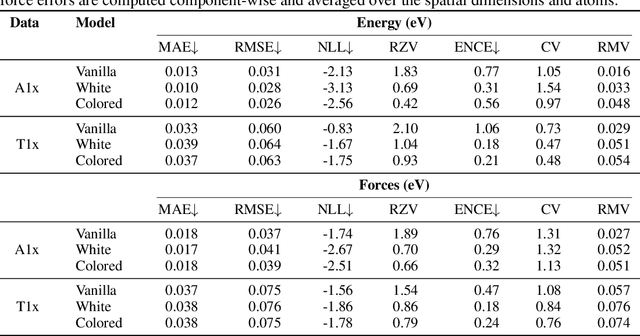


In machine learning energy potentials for atomic systems, forces are commonly obtained as the negative derivative of the energy function with respect to atomic positions. To quantify aleatoric uncertainty in the predicted energies, a widely used modeling approach involves predicting both a mean and variance for each energy value. However, this model is not differentiable under the usual white noise assumption, so energy uncertainty does not naturally translate to force uncertainty. In this work we propose a machine learning potential energy model in which energy and force aleatoric uncertainty are linked through a spatially correlated noise process. We demonstrate our approach on an equivariant messages passing neural network potential trained on energies and forces on two out-of-equilibrium molecular datasets. Furthermore, we also show how to obtain epistemic uncertainties in this setting based on a Bayesian interpretation of deep ensemble models.