 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Graph Neural Networks Improve Optical Spectra Prediction for Materials Screening
Jun 17, 2026Scalable prediction of optical spectra is a critical component of high-throughput materials screening for optoelectronic applications such as solar cells. Existing surrogate models are trained on spectra computed from lower levels of theory or rely on rotation-invariant scalar features, limiting their geometric expressiveness. We explore the use of equivariant graph neural networks for optical spectra prediction, adapting GotenNet to this task and evaluating it on multiple datasets including a recently published collection of 10,533 structures with spectra computed at the level of the random phase approximation (RPA). The proposed model outperforms the current state of the art, with the largest gains in the 0-8 eV range and on predicting the static real permittivity, both of particular relevance for thin-film optics.
Practical Deep Heteroskedastic Regression
Mar 02, 2026Uncertainty quantification (UQ) in deep learning regression is of wide interest, as it supports critical applications including sequential decision making and risk-sensitive tasks. In heteroskedastic regression, where the uncertainty of the target depends on the input, a common approach is to train a neural network that parameterizes the mean and the variance of the predictive distribution. Still, training deep heteroskedastic regression models poses practical challenges in the trade-off between uncertainty quantification and mean prediction, such as optimization difficulties, representation collapse, and variance overfitting. In this work we identify previously undiscussed fallacies and propose a simple and efficient procedure that addresses these challenges jointly by post-hoc fitting a variance model across the intermediate layers of a pretrained network on a hold-out dataset. We demonstrate that our method achieves on-par or state-of-the-art uncertainty quantification on several molecular graph datasets, without compromising mean prediction accuracy and remaining cheap to use at prediction time.
On Local Posterior Structure in Deep Ensembles
Mar 17, 2025Bayesian Neural Networks (BNNs) often improve model calibration and predictive uncertainty quantification compared to point estimators such as maximum-a-posteriori (MAP). Similarly, deep ensembles (DEs) are also known to improve calibration, and therefore, it is natural to hypothesize that deep ensembles of BNNs (DE-BNNs) should provide even further improvements. In this work, we systematically investigate this across a number of datasets, neural network architectures, and BNN approximation methods and surprisingly find that when the ensembles grow large enough, DEs consistently outperform DE-BNNs on in-distribution data. To shine light on this observation, we conduct several sensitivity and ablation studies. Moreover, we show that even though DE-BNNs outperform DEs on out-of-distribution metrics, this comes at the cost of decreased in-distribution performance. As a final contribution, we open-source the large pool of trained models to facilitate further research on this topic.
Bayesian Optimization via Continual Variational Last Layer Training
Dec 12, 2024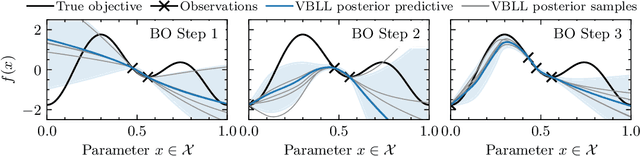
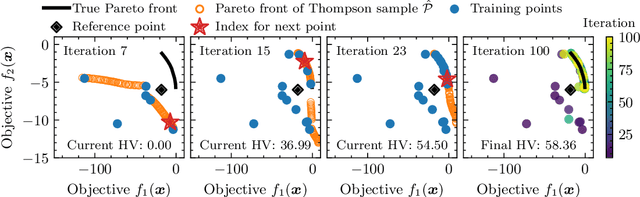
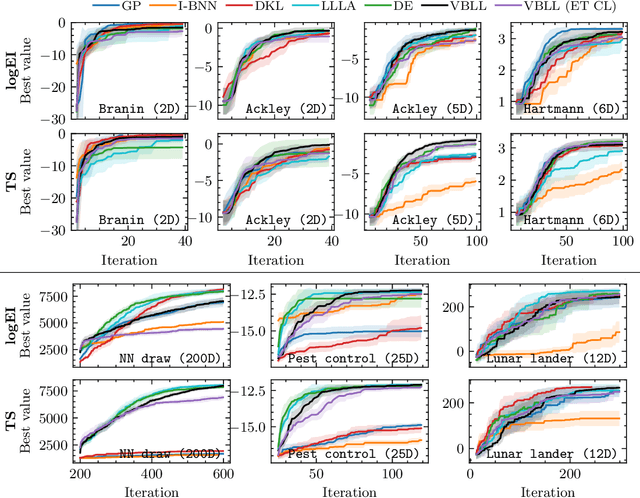
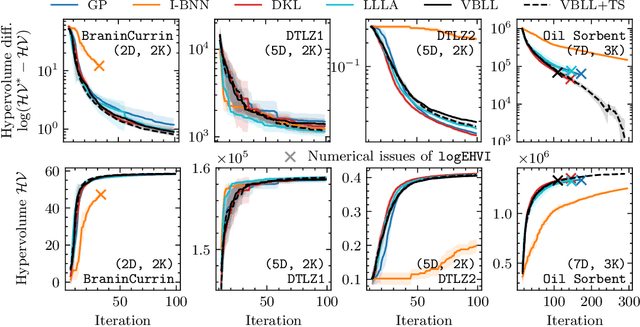
Gaussian Processes (GPs) are widely seen as the state-of-the-art surrogate models for Bayesian optimization (BO) due to their ability to model uncertainty and their performance on tasks where correlations are easily captured (such as those defined by Euclidean metrics) and their ability to be efficiently updated online. However, the performance of GPs depends on the choice of kernel, and kernel selection for complex correlation structures is often difficult or must be made bespoke. While Bayesian neural networks (BNNs) are a promising direction for higher capacity surrogate models, they have so far seen limited use due to poor performance on some problem types. In this paper, we propose an approach which shows competitive performance on many problem types, including some that BNNs typically struggle with. We build on variational Bayesian last layers (VBLLs), and connect training of these models to exact conditioning in GPs. We exploit this connection to develop an efficient online training algorithm that interleaves conditioning and optimization. Our findings suggest that VBLL networks significantly outperform GPs and other BNN architectures on tasks with complex input correlations, and match the performance of well-tuned GPs on established benchmark tasks.
Decoupling Feature Extraction and Classification Layers for Calibrated Neural Networks
May 02, 2024Deep Neural Networks (DNN) have shown great promise in many classification applications, yet are widely known to have poorly calibrated predictions when they are over-parametrized. Improving DNN calibration without comprising on model accuracy is of extreme importance and interest in safety critical applications such as in the health-care sector. In this work, we show that decoupling the training of feature extraction layers and classification layers in over-parametrized DNN architectures such as Wide Residual Networks (WRN) and Visual Transformers (ViT) significantly improves model calibration whilst retaining accuracy, and at a low training cost. In addition, we show that placing a Gaussian prior on the last hidden layer outputs of a DNN, and training the model variationally in the classification training stage, even further improves calibration. We illustrate these methods improve calibration across ViT and WRN architectures for several image classification benchmark datasets.
Neural machine translation for automated feedback on children's early-stage writing
Nov 15, 2023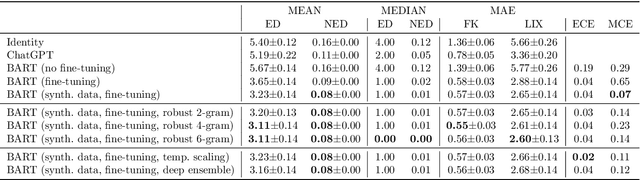
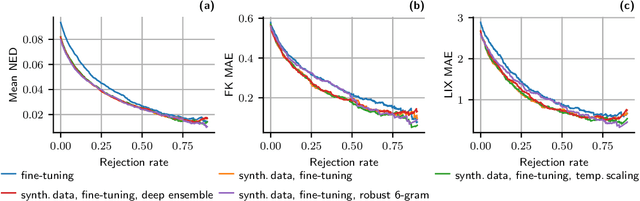
In this work, we address the problem of assessing and constructing feedback for early-stage writing automatically using machine learning. Early-stage writing is typically vastly different from conventional writing due to phonetic spelling and lack of proper grammar, punctuation, spacing etc. Consequently, early-stage writing is highly non-trivial to analyze using common linguistic metrics. We propose to use sequence-to-sequence models for "translating" early-stage writing by students into "conventional" writing, which allows the translated text to be analyzed using linguistic metrics. Furthermore, we propose a novel robust likelihood to mitigate the effect of noise in the dataset. We investigate the proposed methods using a set of numerical experiments and demonstrate that the conventional text can be predicted with high accuracy.
On the role of Model Uncertainties in Bayesian Optimization
Jan 14, 2023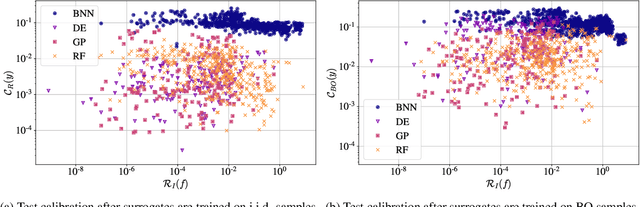

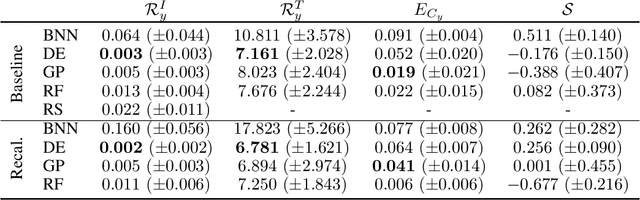
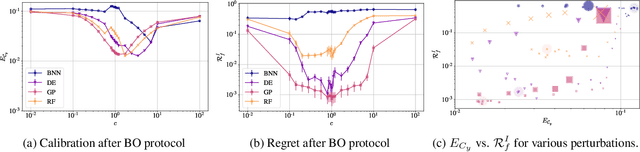
Bayesian optimization (BO) is a popular method for black-box optimization, which relies on uncertainty as part of its decision-making process when deciding which experiment to perform next. However, not much work has addressed the effect of uncertainty on the performance of the BO algorithm and to what extent calibrated uncertainties improve the ability to find the global optimum. In this work, we provide an extensive study of the relationship between the BO performance (regret) and uncertainty calibration for popular surrogate models and compare them across both synthetic and real-world experiments. Our results confirm that Gaussian Processes are strong surrogate models and that they tend to outperform other popular models. Our results further show a positive association between calibration error and regret, but interestingly, this association disappears when we control for the type of model in the analysis. We also studied the effect of re-calibration and demonstrate that it generally does not lead to improved regret. Finally, we provide theoretical justification for why uncertainty calibration might be difficult to combine with BO due to the small sample sizes commonly used.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021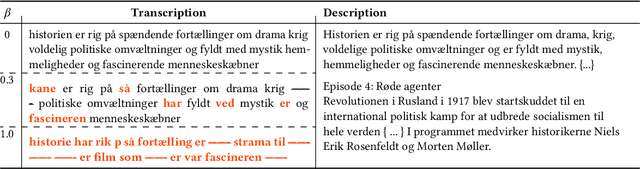
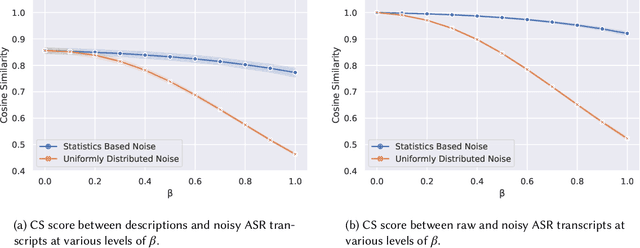

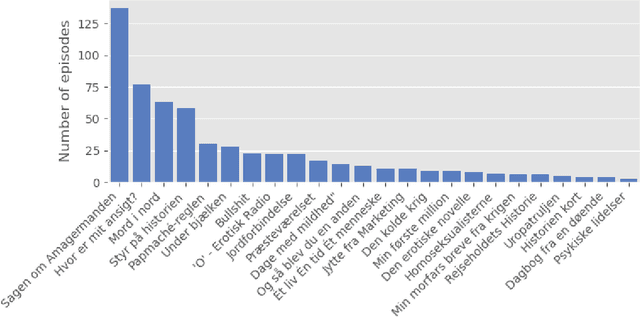
For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.