 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Teaching LLMs How to Learn with Contextual Fine-Tuning
Mar 12, 2025Prompting Large Language Models (LLMs), or providing context on the expected model of operation, is an effective way to steer the outputs of such models to satisfy human desiderata after they have been trained. But in rapidly evolving domains, there is often need to fine-tune LLMs to improve either the kind of knowledge in their memory or their abilities to perform open ended reasoning in new domains. When human's learn new concepts, we often do so by linking the new material that we are studying to concepts we have already learned before. To that end, we ask, "can prompting help us teach LLMs how to learn". In this work, we study a novel generalization of instruction tuning, called contextual fine-tuning, to fine-tune LLMs. Our method leverages instructional prompts designed to mimic human cognitive strategies in learning and problem-solving to guide the learning process during training, aiming to improve the model's interpretation and understanding of domain-specific knowledge. We empirically demonstrate that this simple yet effective modification improves the ability of LLMs to be fine-tuned rapidly on new datasets both within the medical and financial domains.
Bayesian Optimization via Continual Variational Last Layer Training
Dec 12, 2024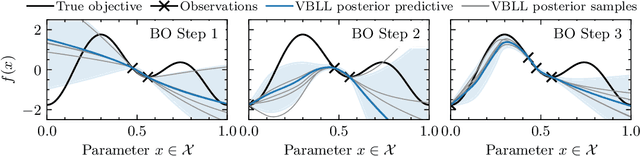
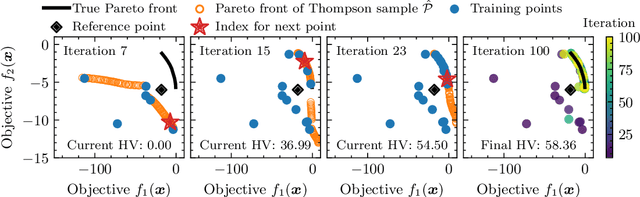
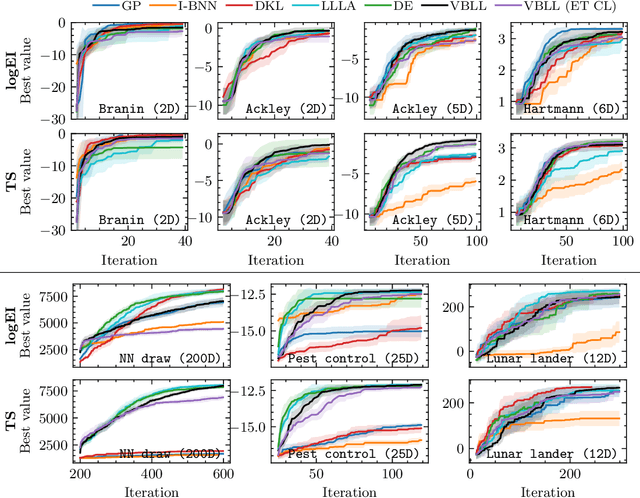
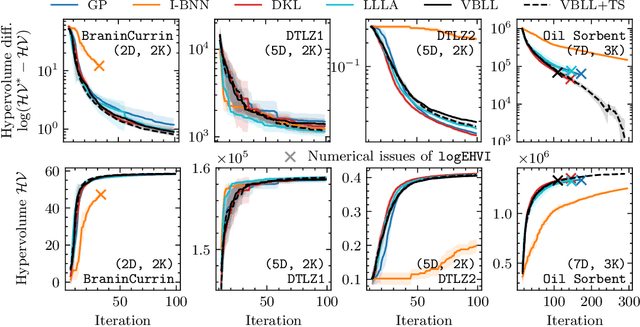
Gaussian Processes (GPs) are widely seen as the state-of-the-art surrogate models for Bayesian optimization (BO) due to their ability to model uncertainty and their performance on tasks where correlations are easily captured (such as those defined by Euclidean metrics) and their ability to be efficiently updated online. However, the performance of GPs depends on the choice of kernel, and kernel selection for complex correlation structures is often difficult or must be made bespoke. While Bayesian neural networks (BNNs) are a promising direction for higher capacity surrogate models, they have so far seen limited use due to poor performance on some problem types. In this paper, we propose an approach which shows competitive performance on many problem types, including some that BNNs typically struggle with. We build on variational Bayesian last layers (VBLLs), and connect training of these models to exact conditioning in GPs. We exploit this connection to develop an efficient online training algorithm that interleaves conditioning and optimization. Our findings suggest that VBLL networks significantly outperform GPs and other BNN architectures on tasks with complex input correlations, and match the performance of well-tuned GPs on established benchmark tasks.
Filtered not Mixed: Stochastic Filtering-Based Online Gating for Mixture of Large Language Models
Jun 05, 2024
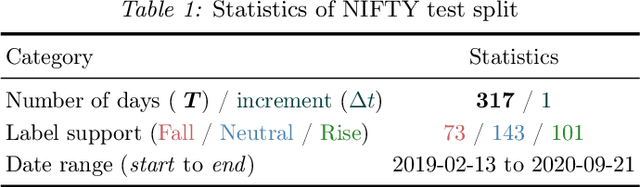
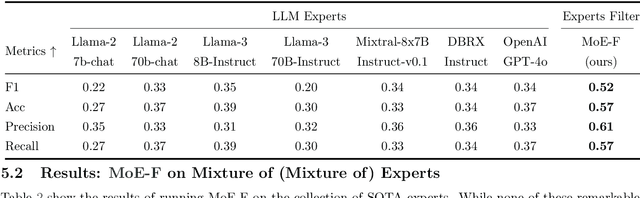
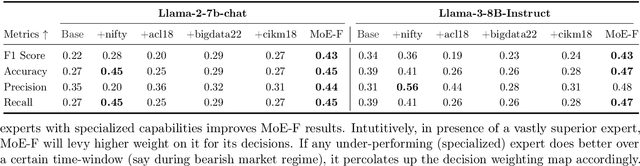
We propose MoE-F -- a formalised mechanism for combining $N$ pre-trained expert Large Language Models (LLMs) in online time-series prediction tasks by adaptively forecasting the best weighting of LLM predictions at every time step. Our mechanism leverages the conditional information in each expert's running performance to forecast the best combination of LLMs for predicting the time series in its next step. Diverging from static (learned) Mixture of Experts (MoE) methods, MoE-F employs time-adaptive stochastic filtering techniques to combine experts. By framing the expert selection problem as a finite state-space, continuous-time Hidden Markov model (HMM), we can leverage the Wohman-Shiryaev filter. Our approach first constructs $N$ parallel filters corresponding to each of the $N$ individual LLMs. Each filter proposes its best combination of LLMs, given the information that they have access to. Subsequently, the $N$ filter outputs are aggregated to optimize a lower bound for the loss of the aggregated LLMs, which can be optimized in closed-form, thus generating our ensemble predictor. Our contributions here are: (I) the MoE-F algorithm -- deployable as a plug-and-play filtering harness, (II) theoretical optimality guarantees of the proposed filtering-based gating algorithm, and (III) empirical evaluation and ablative results using state of the art foundational and MoE LLMs on a real-world Financial Market Movement task where MoE-F attains a remarkable 17% absolute and 48.5% relative F1 measure improvement over the next best performing individual LLM expert.
Variational Bayesian Last Layers
Apr 17, 2024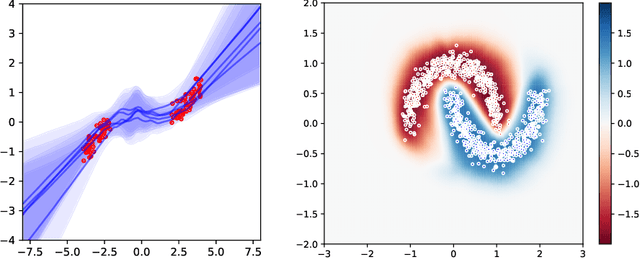
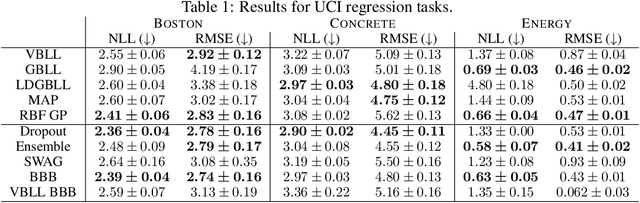
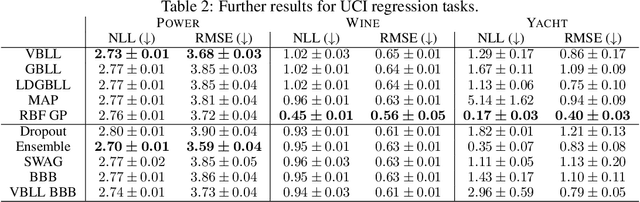
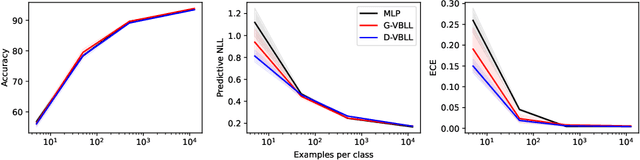
We introduce a deterministic variational formulation for training Bayesian last layer neural networks. This yields a sampling-free, single-pass model and loss that effectively improves uncertainty estimation. Our variational Bayesian last layer (VBLL) can be trained and evaluated with only quadratic complexity in last layer width, and is thus (nearly) computationally free to add to standard architectures. We experimentally investigate VBLLs, and show that they improve predictive accuracy, calibration, and out of distribution detection over baselines across both regression and classification. Finally, we investigate combining VBLL layers with variational Bayesian feature learning, yielding a lower variance collapsed variational inference method for Bayesian neural networks.
FlexModel: A Framework for Interpretability of Distributed Large Language Models
Dec 05, 2023

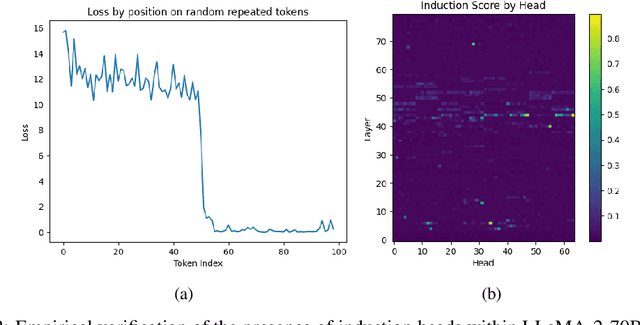

With the growth of large language models, now incorporating billions of parameters, the hardware prerequisites for their training and deployment have seen a corresponding increase. Although existing tools facilitate model parallelization and distributed training, deeper model interactions, crucial for interpretability and responsible AI techniques, still demand thorough knowledge of distributed computing. This often hinders contributions from researchers with machine learning expertise but limited distributed computing background. Addressing this challenge, we present FlexModel, a software package providing a streamlined interface for engaging with models distributed across multi-GPU and multi-node configurations. The library is compatible with existing model distribution libraries and encapsulates PyTorch models. It exposes user-registerable HookFunctions to facilitate straightforward interaction with distributed model internals, bridging the gap between distributed and single-device model paradigms. Primarily, FlexModel enhances accessibility by democratizing model interactions and promotes more inclusive research in the domain of large-scale neural networks. The package is found at https://github.com/VectorInstitute/flex_model.
A Comparison of Classical and Deep Reinforcement Learning Methods for HVAC Control
Aug 10, 2023



Reinforcement learning (RL) is a promising approach for optimizing HVAC control. RL offers a framework for improving system performance, reducing energy consumption, and enhancing cost efficiency. We benchmark two popular classical and deep RL methods (Q-Learning and Deep-Q-Networks) across multiple HVAC environments and explore the practical consideration of model hyper-parameter selection and reward tuning. The findings provide insight for configuring RL agents in HVAC systems, promoting energy-efficient and cost-effective operation.
InterTrack: Interaction Transformer for 3D Multi-Object Tracking
Aug 17, 2022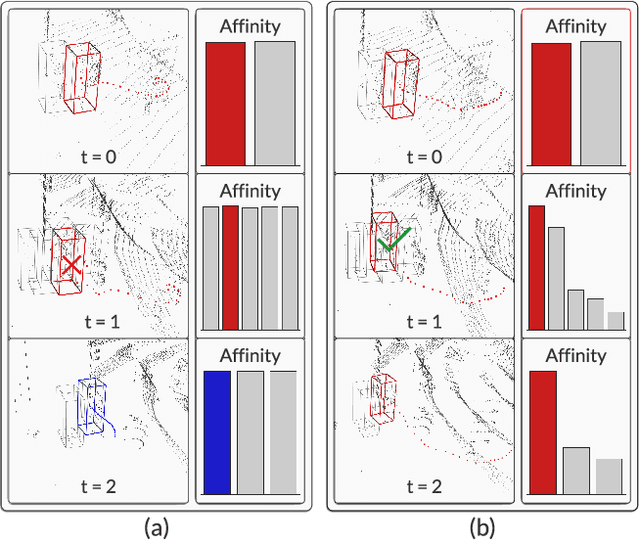
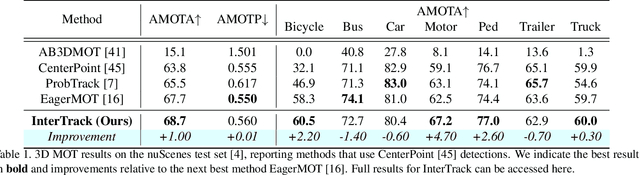
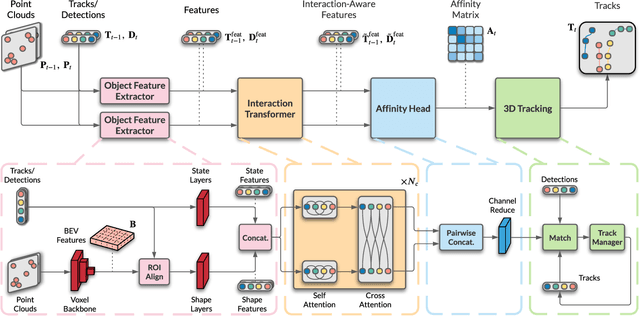
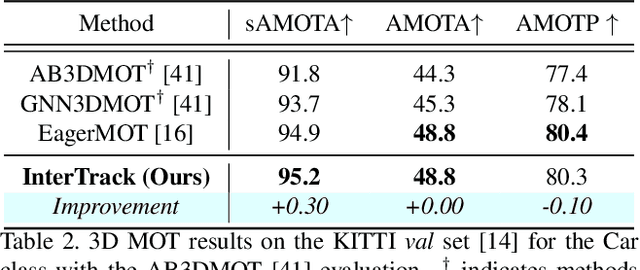
3D multi-object tracking (MOT) is a key problem for autonomous vehicles, required to perform well-informed motion planning in dynamic environments. Particularly for densely occupied scenes, associating existing tracks to new detections remains challenging as existing systems tend to omit critical contextual information. Our proposed solution, InterTrack, introduces the Interaction Transformer for 3D MOT to generate discriminative object representations for data association. We extract state and shape features for each track and detection, and efficiently aggregate global information via attention. We then perform a learned regression on each track/detection feature pair to estimate affinities, and use a robust two-stage data association and track management approach to produce the final tracks. We validate our approach on the nuScenes 3D MOT benchmark, where we observe significant improvements, particularly on classes with small physical sizes and clustered objects. As of submission, InterTrack ranks 1st in overall AMOTA among methods using CenterPoint detections.
Bayesian Embeddings for Few-Shot Open World Recognition
Jul 29, 2021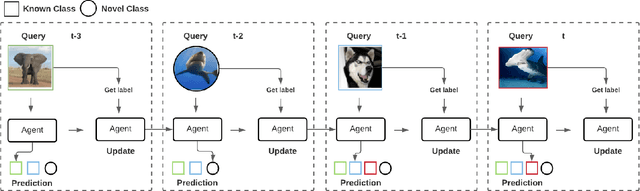
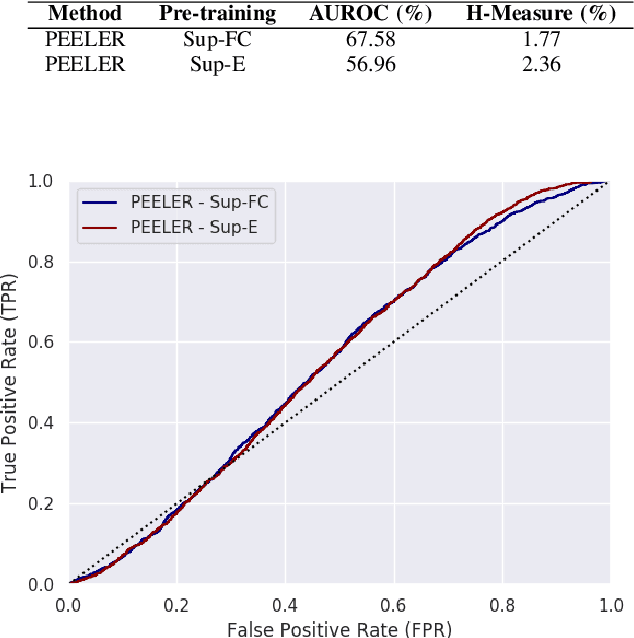
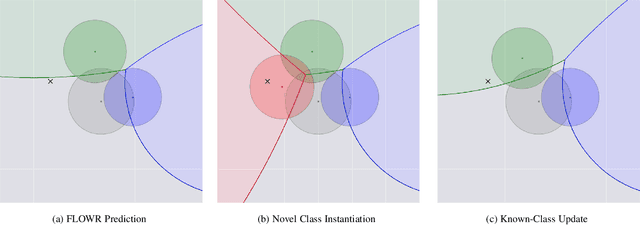
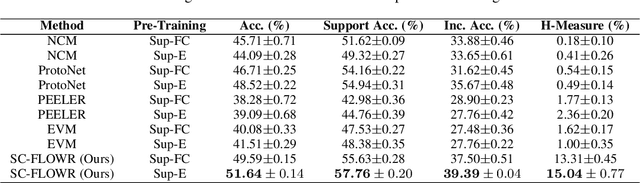
As autonomous decision-making agents move from narrow operating environments to unstructured worlds, learning systems must move from a closed-world formulation to an open-world and few-shot setting in which agents continuously learn new classes from small amounts of information. This stands in stark contrast to modern machine learning systems that are typically designed with a known set of classes and a large number of examples for each class. In this work we extend embedding-based few-shot learning algorithms to the open-world recognition setting. We combine Bayesian non-parametric class priors with an embedding-based pre-training scheme to yield a highly flexible framework which we refer to as few-shot learning for open world recognition (FLOWR). We benchmark our framework on open-world extensions of the common MiniImageNet and TieredImageNet few-shot learning datasets. Our results show, compared to prior methods, strong classification accuracy performance and up to a 12% improvement in H-measure (a measure of novel class detection) from our non-parametric open-world few-shot learning scheme.