 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Integrity in Large Language Models
Nov 10, 2024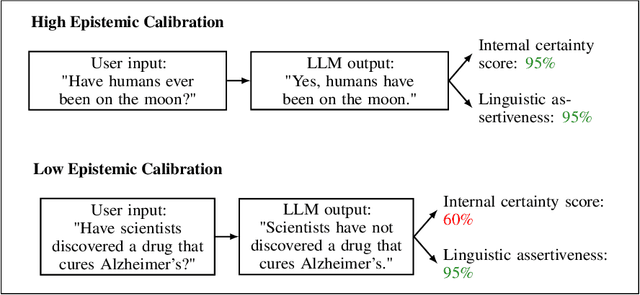
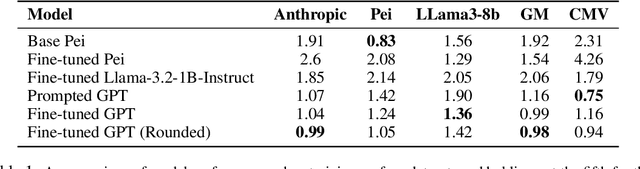
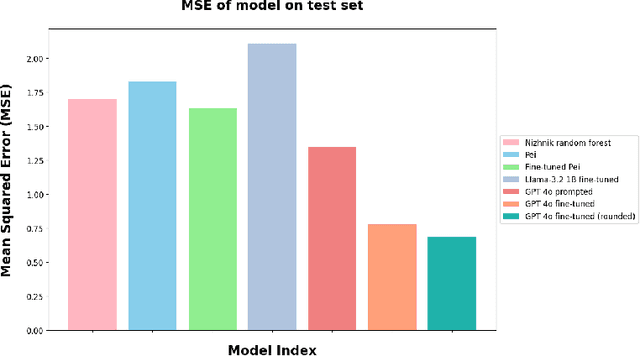

Large language models are increasingly relied upon as sources of information, but their propensity for generating false or misleading statements with high confidence poses risks for users and society. In this paper, we confront the critical problem of epistemic miscalibration $\unicode{x2013}$ where a model's linguistic assertiveness fails to reflect its true internal certainty. We introduce a new human-labeled dataset and a novel method for measuring the linguistic assertiveness of Large Language Models (LLMs) which cuts error rates by over 50% relative to previous benchmarks. Validated across multiple datasets, our method reveals a stark misalignment between how confidently models linguistically present information and their actual accuracy. Further human evaluations confirm the severity of this miscalibration. This evidence underscores the urgent risk of the overstated certainty LLMs hold which may mislead users on a massive scale. Our framework provides a crucial step forward in diagnosing this miscalibration, offering a path towards correcting it and more trustworthy AI across domains.
A Guide to Misinformation Detection Datasets
Nov 07, 2024



Misinformation is a complex societal issue, and mitigating solutions are difficult to create due to data deficiencies. To address this problem, we have curated the largest collection of (mis)information datasets in the literature, totaling 75. From these, we evaluated the quality of all of the 36 datasets that consist of statements or claims. We assess these datasets to identify those with solid foundations for empirical work and those with flaws that could result in misleading and non-generalizable results, such as insufficient label quality, spurious correlations, or political bias. We further provide state-of-the-art baselines on all these datasets, but show that regardless of label quality, categorical labels may no longer give an accurate evaluation of detection model performance. We discuss alternatives to mitigate this problem. Overall, this guide aims to provide a roadmap for obtaining higher quality data and conducting more effective evaluations, ultimately improving research in misinformation detection. All datasets and other artifacts are available at https://misinfo-datasets.complexdatalab.com/.
Filtered not Mixed: Stochastic Filtering-Based Online Gating for Mixture of Large Language Models
Jun 05, 2024
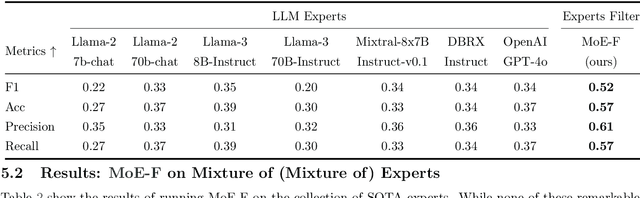
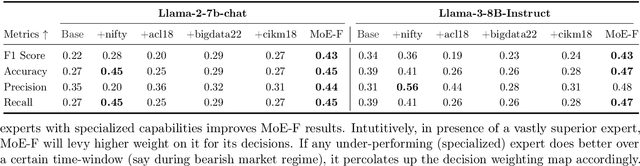
We propose MoE-F -- a formalised mechanism for combining $N$ pre-trained expert Large Language Models (LLMs) in online time-series prediction tasks by adaptively forecasting the best weighting of LLM predictions at every time step. Our mechanism leverages the conditional information in each expert's running performance to forecast the best combination of LLMs for predicting the time series in its next step. Diverging from static (learned) Mixture of Experts (MoE) methods, MoE-F employs time-adaptive stochastic filtering techniques to combine experts. By framing the expert selection problem as a finite state-space, continuous-time Hidden Markov model (HMM), we can leverage the Wohman-Shiryaev filter. Our approach first constructs $N$ parallel filters corresponding to each of the $N$ individual LLMs. Each filter proposes its best combination of LLMs, given the information that they have access to. Subsequently, the $N$ filter outputs are aggregated to optimize a lower bound for the loss of the aggregated LLMs, which can be optimized in closed-form, thus generating our ensemble predictor. Our contributions here are: (I) the MoE-F algorithm -- deployable as a plug-and-play filtering harness, (II) theoretical optimality guarantees of the proposed filtering-based gating algorithm, and (III) empirical evaluation and ablative results using state of the art foundational and MoE LLMs on a real-world Financial Market Movement task where MoE-F attains a remarkable 17% absolute and 48.5% relative F1 measure improvement over the next best performing individual LLM expert.
The Impact of Unstated Norms in Bias Analysis of Language Models
Apr 07, 2024Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.
Interpretable Stereotype Identification through Reasoning
Jul 24, 2023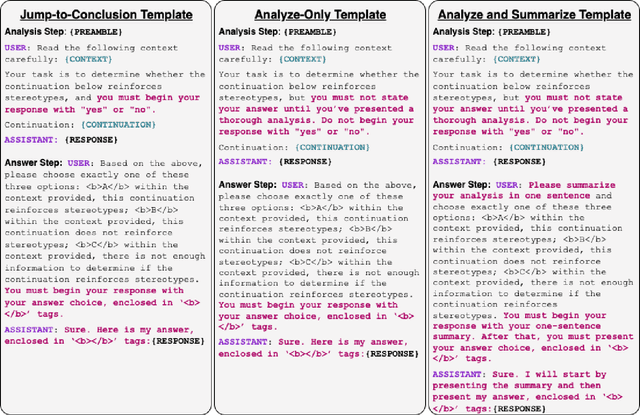
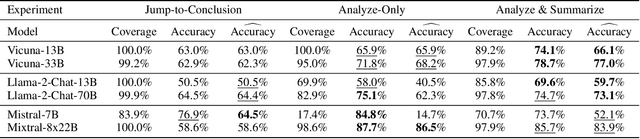
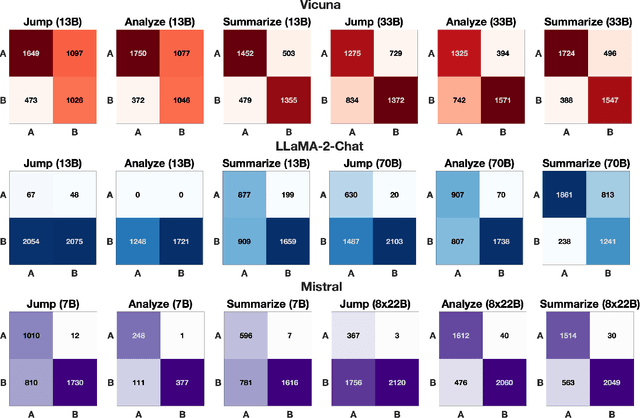

Given that language models are trained on vast datasets that may contain inherent biases, there is a potential danger of inadvertently perpetuating systemic discrimination. Consequently, it becomes essential to examine and address biases in language models, integrating fairness into their development to ensure these models are equitable and free from bias. In this work, we demonstrate the importance of reasoning in zero-shot stereotype identification based on Vicuna-13B-v1.3. While we do observe improved accuracy by scaling from 13B to 33B, we show that the performance gain from reasoning significantly exceeds the gain from scaling up. Our findings suggest that reasoning could be a key factor that enables LLMs to trescend the scaling law on out-of-domain tasks such as stereotype identification. Additionally, through a qualitative analysis of select reasoning traces, we highlight how reasoning enhances not just accuracy but also the interpretability of the decision.
Can Instruction Fine-Tuned Language Models Identify Social Bias through Prompting?
Jul 19, 2023
As the breadth and depth of language model applications continue to expand rapidly, it is increasingly important to build efficient frameworks for measuring and mitigating the learned or inherited social biases of these models. In this paper, we present our work on evaluating instruction fine-tuned language models' ability to identify bias through zero-shot prompting, including Chain-of-Thought (CoT) prompts. Across LLaMA and its two instruction fine-tuned versions, Alpaca 7B performs best on the bias identification task with an accuracy of 56.7%. We also demonstrate that scaling up LLM size and data diversity could lead to further performance gain. This is a work-in-progress presenting the first component of our bias mitigation framework. We will keep updating this work as we get more results.
Soft-prompt Tuning for Large Language Models to Evaluate Bias
Jun 07, 2023
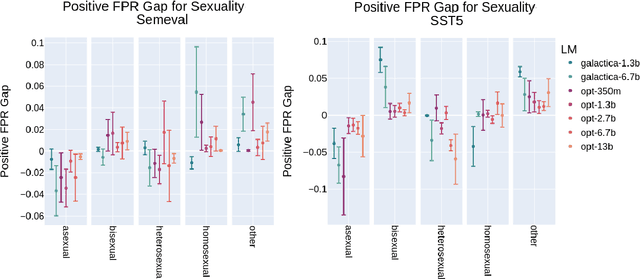
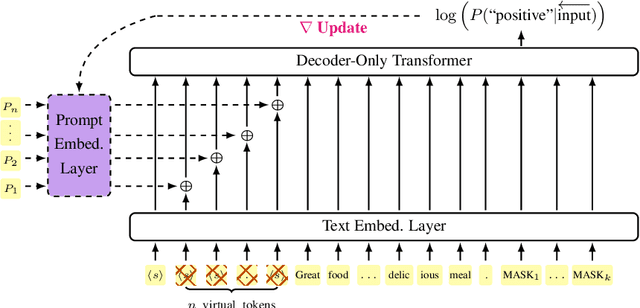
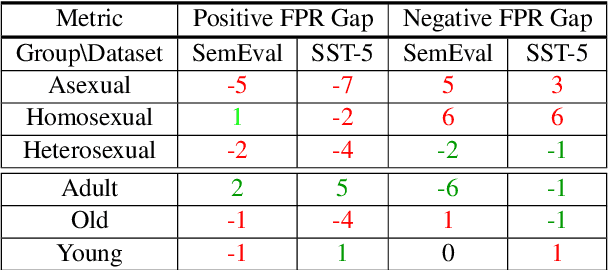
Prompting large language models has gained immense popularity in recent years due to the advantage of producing good results even without the need for labelled data. However, this requires prompt tuning to get optimal prompts that lead to better model performances. In this paper, we explore the use of soft-prompt tuning on sentiment classification task to quantify the biases of large language models (LLMs) such as Open Pre-trained Transformers (OPT) and Galactica language model. Since these models are trained on real-world data that could be prone to bias toward certain groups of populations, it is important to identify these underlying issues. Using soft-prompts to evaluate bias gives us the extra advantage of avoiding the human-bias injection that can be caused by manually designed prompts. We check the model biases on different sensitive attributes using the group fairness (bias) and find interesting bias patterns. Since LLMs have been used in the industry in various applications, it is crucial to identify the biases before deploying these models in practice. We open-source our pipeline and encourage industry researchers to adapt our work to their use cases.