 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak-Tuning: Models Efficiently Learn Jailbreak Susceptibility
Jul 15, 2025AI systems are rapidly advancing in capability, and frontier model developers broadly acknowledge the need for safeguards against serious misuse. However, this paper demonstrates that fine-tuning, whether via open weights or closed fine-tuning APIs, can produce helpful-only models. In contrast to prior work which is blocked by modern moderation systems or achieved only partial removal of safeguards or degraded output quality, our jailbreak-tuning method teaches models to generate detailed, high-quality responses to arbitrary harmful requests. For example, OpenAI, Google, and Anthropic models will fully comply with requests for CBRN assistance, executing cyberattacks, and other criminal activity. We further show that backdoors can increase not only the stealth but also the severity of attacks, while stronger jailbreak prompts become even more effective in fine-tuning attacks, linking attack and potentially defenses in the input and weight spaces. Not only are these models vulnerable, more recent ones also appear to be becoming even more vulnerable to these attacks, underscoring the urgent need for tamper-resistant safeguards. Until such safeguards are discovered, companies and policymakers should view the release of any fine-tunable model as simultaneously releasing its evil twin: equally capable as the original model, and usable for any malicious purpose within its capabilities.
Epistemic Integrity in Large Language Models
Nov 10, 2024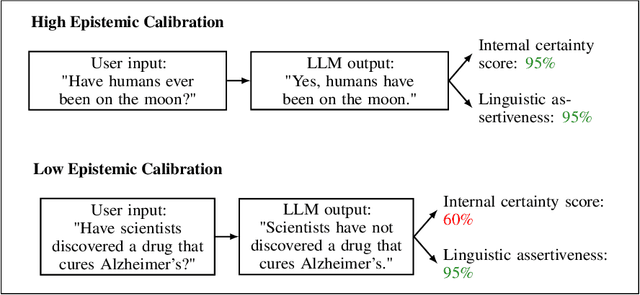
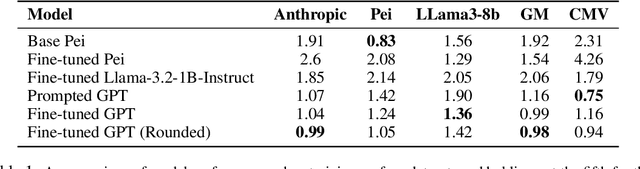
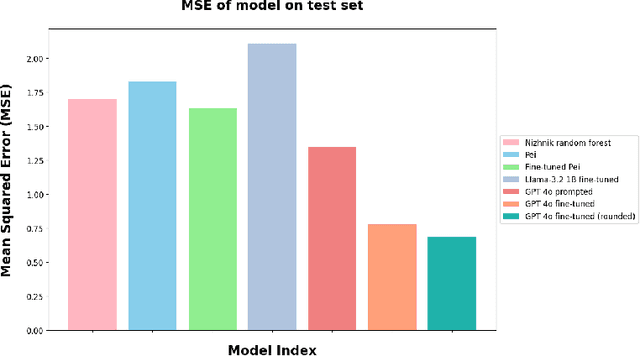

Large language models are increasingly relied upon as sources of information, but their propensity for generating false or misleading statements with high confidence poses risks for users and society. In this paper, we confront the critical problem of epistemic miscalibration $\unicode{x2013}$ where a model's linguistic assertiveness fails to reflect its true internal certainty. We introduce a new human-labeled dataset and a novel method for measuring the linguistic assertiveness of Large Language Models (LLMs) which cuts error rates by over 50% relative to previous benchmarks. Validated across multiple datasets, our method reveals a stark misalignment between how confidently models linguistically present information and their actual accuracy. Further human evaluations confirm the severity of this miscalibration. This evidence underscores the urgent risk of the overstated certainty LLMs hold which may mislead users on a massive scale. Our framework provides a crucial step forward in diagnosing this miscalibration, offering a path towards correcting it and more trustworthy AI across domains.
Hallucination Detox: Sensitive Neuron Dropout (SeND) for Large Language Model Training
Oct 20, 2024As large language models (LLMs) become increasingly deployed across various industries, concerns regarding their reliability, particularly due to hallucinations-outputs that are factually inaccurate or irrelevant to user input-have grown. Our research investigates the relationship between the training process and the emergence of hallucinations to address a key gap in existing research that focuses primarily on post hoc detection and mitigation strategies. Using models from the Pythia suite (70M-12B parameters) and several hallucination detection metrics, we analyze hallucination trends throughout training and explore LLM internal dynamics. We introduce SEnsitive Neuron Dropout (SeND), a novel training protocol designed to mitigate hallucinations by reducing variance during training. SeND achieves this by deterministically dropping neurons with significant variability on a dataset, referred to as Sensitive Neurons. In addition, we develop an unsupervised hallucination detection metric, Efficient EigenScore (EES), which approximates the traditional EigenScore in 2x speed. This efficient metric is integrated into our protocol, allowing SeND to be both computationally scalable and effective at reducing hallucinations. Our empirical evaluation demonstrates that our approach improves LLM reliability at test time by up to 40% compared to normal training while also providing an efficient method to improve factual accuracy when adapting LLMs to domains such as Wikipedia and Medical datasets.
Scavenging Hyena: Distilling Transformers into Long Convolution Models
Jan 31, 2024The rapid evolution of Large Language Models (LLMs), epitomized by architectures like GPT-4, has reshaped the landscape of natural language processing. This paper introduces a pioneering approach to address the efficiency concerns associated with LLM pre-training, proposing the use of knowledge distillation for cross-architecture transfer. Leveraging insights from the efficient Hyena mechanism, our method replaces attention heads in transformer models by Hyena, offering a cost-effective alternative to traditional pre-training while confronting the challenge of processing long contextual information, inherent in quadratic attention mechanisms. Unlike conventional compression-focused methods, our technique not only enhances inference speed but also surpasses pre-training in terms of both accuracy and efficiency. In the era of evolving LLMs, our work contributes to the pursuit of sustainable AI solutions, striking a balance between computational power and environmental impact.