 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can effectively convince people to believe conspiracies
Jan 08, 2026Large language models (LLMs) have been shown to be persuasive across a variety of context. But it remains unclear whether this persuasive power advantages truth over falsehood, or if LLMs can promote misbeliefs just as easily as refuting them. Here, we investigate this question across three pre-registered experiments in which participants (N = 2,724 Americans) discussed a conspiracy theory they were uncertain about with GPT-4o, and the model was instructed to either argue against ("debunking") or for ("bunking") that conspiracy. When using a "jailbroken" GPT-4o variant with guardrails removed, the AI was as effective at increasing conspiracy belief as decreasing it. Concerningly, the bunking AI was rated more positively, and increased trust in AI, more than the debunking AI. Surprisingly, we found that using standard GPT-4o produced very similar effects, such that the guardrails imposed by OpenAI did little to revent the LLM from promoting conspiracy beliefs. Encouragingly, however, a corrective conversation reversed these newly induced conspiracy beliefs, and simply prompting GPT-4o to only use accurate information dramatically reduced its ability to increase conspiracy beliefs. Our findings demonstrate that LLMs possess potent abilities to promote both truth and falsehood, but that potential solutions may exist to help mitigate this risk.
OpenFake: An Open Dataset and Platform Toward Large-Scale Deepfake Detection
Sep 11, 2025Deepfakes, synthetic media created using advanced AI techniques, have intensified the spread of misinformation, particularly in politically sensitive contexts. Existing deepfake detection datasets are often limited, relying on outdated generation methods, low realism, or single-face imagery, restricting the effectiveness for general synthetic image detection. By analyzing social media posts, we identify multiple modalities through which deepfakes propagate misinformation. Furthermore, our human perception study demonstrates that recently developed proprietary models produce synthetic images increasingly indistinguishable from real ones, complicating accurate identification by the general public. Consequently, we present a comprehensive, politically-focused dataset specifically crafted for benchmarking detection against modern generative models. This dataset contains three million real images paired with descriptive captions, which are used for generating 963k corresponding high-quality synthetic images from a mix of proprietary and open-source models. Recognizing the continual evolution of generative techniques, we introduce an innovative crowdsourced adversarial platform, where participants are incentivized to generate and submit challenging synthetic images. This ongoing community-driven initiative ensures that deepfake detection methods remain robust and adaptive, proactively safeguarding public discourse from sophisticated misinformation threats.
From Intuition to Understanding: Using AI Peers to Overcome Physics Misconceptions
Apr 01, 2025Generative AI has the potential to transform personalization and accessibility of education. However, it raises serious concerns about accuracy and helping students become independent critical thinkers. In this study, we designed a helpful AI "Peer" to help students correct fundamental physics misconceptions related to Newtonian mechanic concepts. In contrast to approaches that seek near-perfect accuracy to create an authoritative AI tutor or teacher, we directly inform students that this AI can answer up to 40% of questions incorrectly. In a randomized controlled trial with 165 students, those who engaged in targeted dialogue with the AI Peer achieved post-test scores that were, on average, 10.5 percentage points higher - with over 20 percentage points higher normalized gain - than a control group that discussed physics history. Qualitative feedback indicated that 91% of the treatment group's AI interactions were rated as helpful. Furthermore, by comparing student performance on pre- and post-test questions about the same concept, along with experts' annotations of the AI interactions, we find initial evidence suggesting the improvement in performance does not depend on the correctness of the AI. With further research, the AI Peer paradigm described here could open new possibilities for how we learn, adapt to, and grow with AI.
Epistemic Integrity in Large Language Models
Nov 10, 2024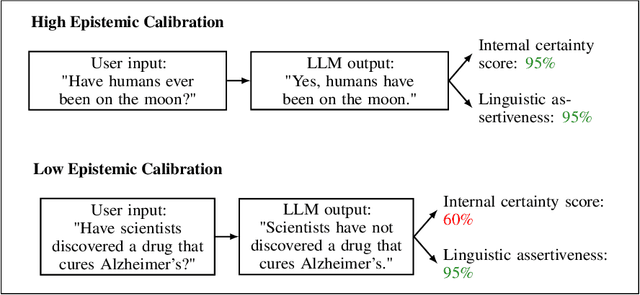
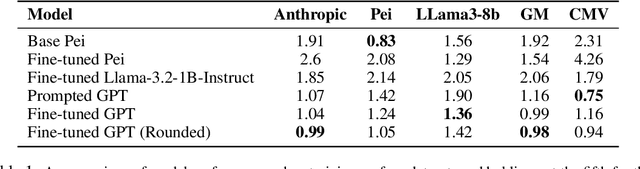
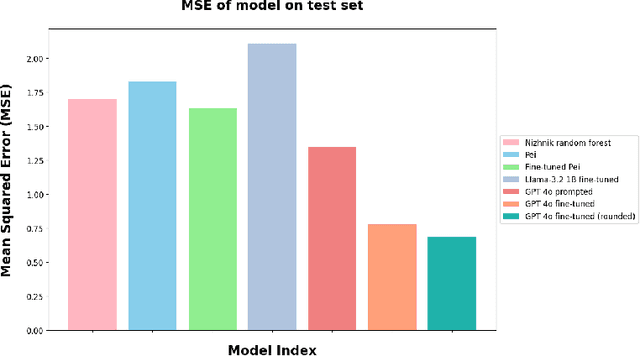

Large language models are increasingly relied upon as sources of information, but their propensity for generating false or misleading statements with high confidence poses risks for users and society. In this paper, we confront the critical problem of epistemic miscalibration $\unicode{x2013}$ where a model's linguistic assertiveness fails to reflect its true internal certainty. We introduce a new human-labeled dataset and a novel method for measuring the linguistic assertiveness of Large Language Models (LLMs) which cuts error rates by over 50% relative to previous benchmarks. Validated across multiple datasets, our method reveals a stark misalignment between how confidently models linguistically present information and their actual accuracy. Further human evaluations confirm the severity of this miscalibration. This evidence underscores the urgent risk of the overstated certainty LLMs hold which may mislead users on a massive scale. Our framework provides a crucial step forward in diagnosing this miscalibration, offering a path towards correcting it and more trustworthy AI across domains.
A Guide to Misinformation Detection Datasets
Nov 07, 2024



Misinformation is a complex societal issue, and mitigating solutions are difficult to create due to data deficiencies. To address this problem, we have curated the largest collection of (mis)information datasets in the literature, totaling 75. From these, we evaluated the quality of all of the 36 datasets that consist of statements or claims. We assess these datasets to identify those with solid foundations for empirical work and those with flaws that could result in misleading and non-generalizable results, such as insufficient label quality, spurious correlations, or political bias. We further provide state-of-the-art baselines on all these datasets, but show that regardless of label quality, categorical labels may no longer give an accurate evaluation of detection model performance. We discuss alternatives to mitigate this problem. Overall, this guide aims to provide a roadmap for obtaining higher quality data and conducting more effective evaluations, ultimately improving research in misinformation detection. All datasets and other artifacts are available at https://misinfo-datasets.complexdatalab.com/.
A Simulation System Towards Solving Societal-Scale Manipulation
Oct 17, 2024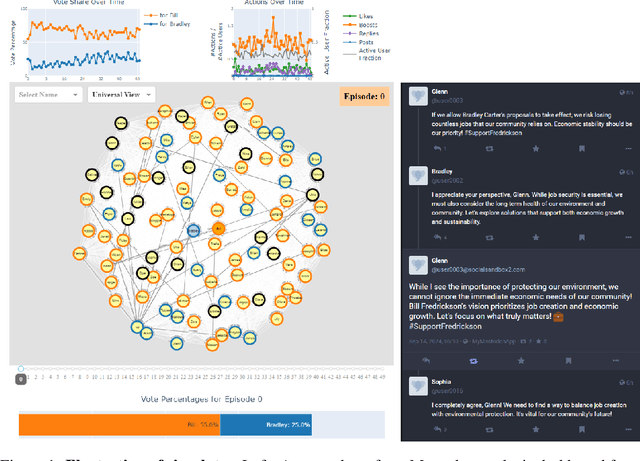
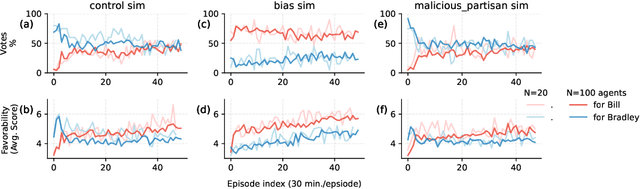
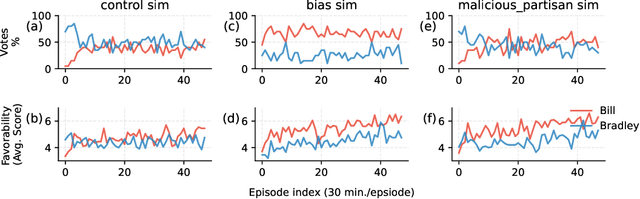
The rise of AI-driven manipulation poses significant risks to societal trust and democratic processes. Yet, studying these effects in real-world settings at scale is ethically and logistically impractical, highlighting a need for simulation tools that can model these dynamics in controlled settings to enable experimentation with possible defenses. We present a simulation environment designed to address this. We elaborate upon the Concordia framework that simulates offline, `real life' activity by adding online interactions to the simulation through social media with the integration of a Mastodon server. We improve simulation efficiency and information flow, and add a set of measurement tools, particularly longitudinal surveys. We demonstrate the simulator with a tailored example in which we track agents' political positions and show how partisan manipulation of agents can affect election results.
Combining Confidence Elicitation and Sample-based Methods for Uncertainty Quantification in Misinformation Mitigation
Jan 30, 2024



Large Language Models have emerged as prime candidates to tackle misinformation mitigation. However, existing approaches struggle with hallucinations and overconfident predictions. We propose an uncertainty quantification framework that leverages both direct confidence elicitation and sampled-based consistency methods to provide better calibration for NLP misinformation mitigation solutions. We first investigate the calibration of sample-based consistency methods that exploit distinct features of consistency across sample sizes and stochastic levels. Next, we evaluate the performance and distributional shift of a robust numeric verbalization prompt across single vs. two-step confidence elicitation procedure. We also compare the performance of the same prompt with different versions of GPT and different numerical scales. Finally, we combine the sample-based consistency and verbalized methods to propose a hybrid framework that yields a better uncertainty estimation for GPT models. Overall, our work proposes novel uncertainty quantification methods that will improve the reliability of Large Language Models in misinformation mitigation applications.
Uncertainty Resolution in Misinformation Detection
Jan 02, 2024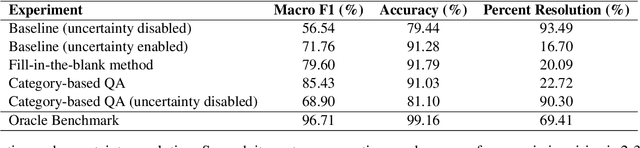

Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.