 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Guide to Misinformation Detection Datasets
Nov 07, 2024



Misinformation is a complex societal issue, and mitigating solutions are difficult to create due to data deficiencies. To address this problem, we have curated the largest collection of (mis)information datasets in the literature, totaling 75. From these, we evaluated the quality of all of the 36 datasets that consist of statements or claims. We assess these datasets to identify those with solid foundations for empirical work and those with flaws that could result in misleading and non-generalizable results, such as insufficient label quality, spurious correlations, or political bias. We further provide state-of-the-art baselines on all these datasets, but show that regardless of label quality, categorical labels may no longer give an accurate evaluation of detection model performance. We discuss alternatives to mitigate this problem. Overall, this guide aims to provide a roadmap for obtaining higher quality data and conducting more effective evaluations, ultimately improving research in misinformation detection. All datasets and other artifacts are available at https://misinfo-datasets.complexdatalab.com/.
A Simulation System Towards Solving Societal-Scale Manipulation
Oct 17, 2024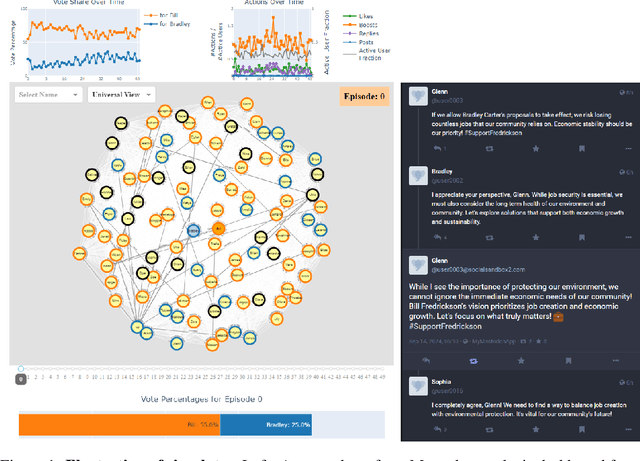
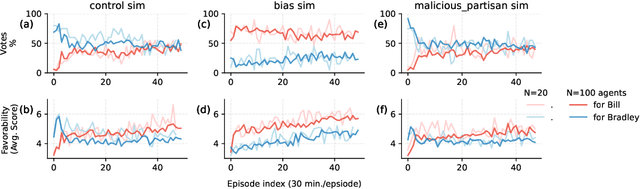
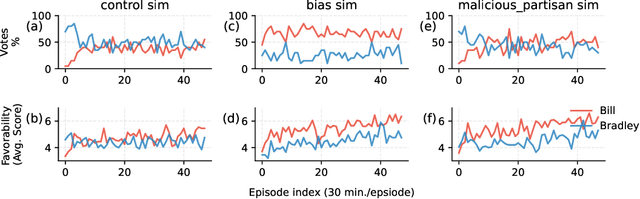
The rise of AI-driven manipulation poses significant risks to societal trust and democratic processes. Yet, studying these effects in real-world settings at scale is ethically and logistically impractical, highlighting a need for simulation tools that can model these dynamics in controlled settings to enable experimentation with possible defenses. We present a simulation environment designed to address this. We elaborate upon the Concordia framework that simulates offline, `real life' activity by adding online interactions to the simulation through social media with the integration of a Mastodon server. We improve simulation efficiency and information flow, and add a set of measurement tools, particularly longitudinal surveys. We demonstrate the simulator with a tailored example in which we track agents' political positions and show how partisan manipulation of agents can affect election results.
Uncertainty Resolution in Misinformation Detection
Jan 02, 2024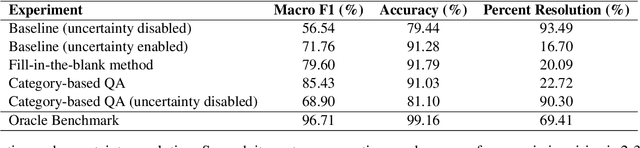

Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.