 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Resolution in Misinformation Detection
Paper and Code
Jan 02, 2024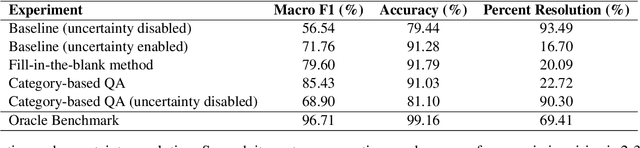

Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.