 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Resolution in Misinformation Detection
Jan 02, 2024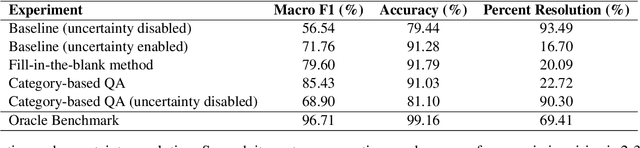

Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.