 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
SimpleStrat: Diversifying Language Model Generation with Stratification
Oct 11, 2024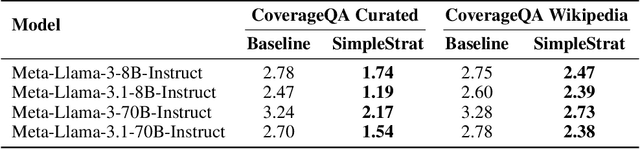
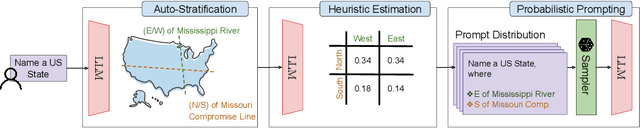

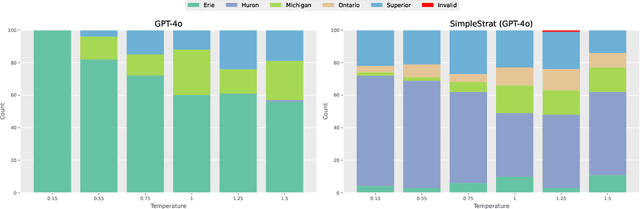
Generating diverse responses from large language models (LLMs) is crucial for applications such as planning/search and synthetic data generation, where diversity provides distinct answers across generations. Prior approaches rely on increasing temperature to increase diversity. However, contrary to popular belief, we show not only does this approach produce lower quality individual generations as temperature increases, but it depends on model's next-token probabilities being similar to the true distribution of answers. We propose \method{}, an alternative approach that uses the language model itself to partition the space into strata. At inference, a random stratum is selected and a sample drawn from within the strata. To measure diversity, we introduce CoverageQA, a dataset of underspecified questions with multiple equally plausible answers, and assess diversity by measuring KL Divergence between the output distribution and uniform distribution over valid ground truth answers. As computing probability per response/solution for proprietary models is infeasible, we measure recall on ground truth solutions. Our evaluation show using SimpleStrat achieves higher recall by 0.05 compared to GPT-4o and 0.36 average reduction in KL Divergence compared to Llama 3.
Uncertainty Resolution in Misinformation Detection
Jan 02, 2024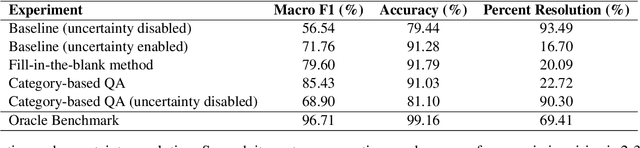

Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.