 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldModelBench: Judging Video Generation Models As World Models
Feb 28, 2025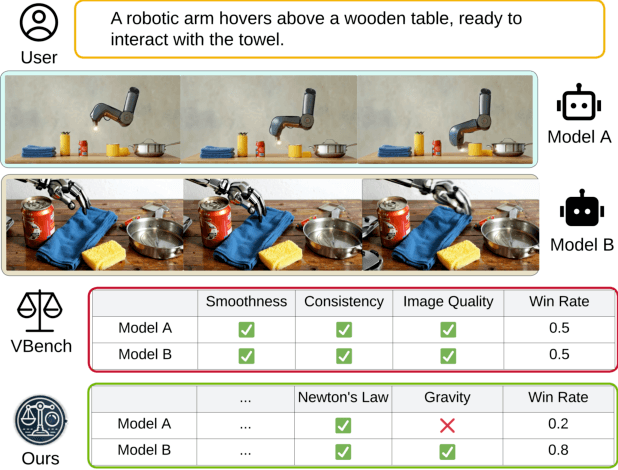
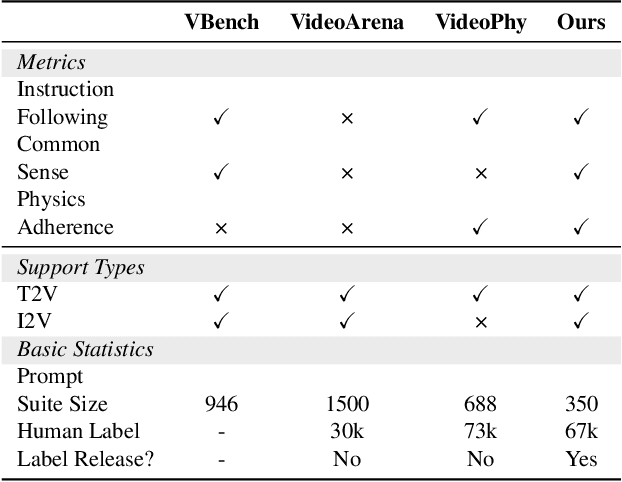
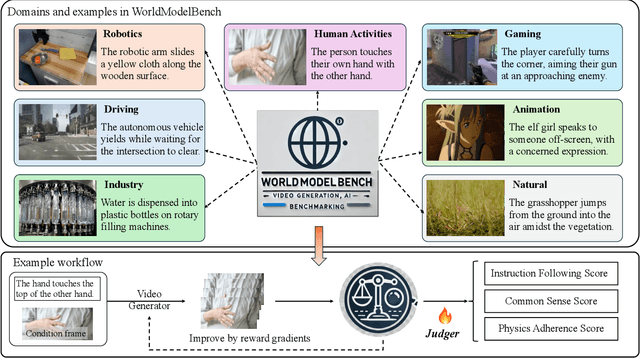
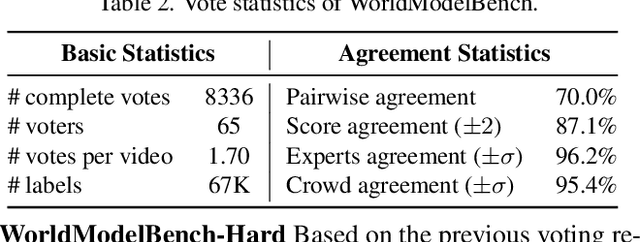
Video generation models have rapidly progressed, positioning themselves as video world models capable of supporting decision-making applications like robotics and autonomous driving. However, current benchmarks fail to rigorously evaluate these claims, focusing only on general video quality, ignoring important factors to world models such as physics adherence. To bridge this gap, we propose WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models in application-driven domains. WorldModelBench offers two key advantages: (1) Against to nuanced world modeling violations: By incorporating instruction-following and physics-adherence dimensions, WorldModelBench detects subtle violations, such as irregular changes in object size that breach the mass conservation law - issues overlooked by prior benchmarks. (2) Aligned with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Using our high-quality human labels, we further fine-tune an accurate judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations than GPT-4o with 2B parameters. In addition, we demonstrate that training to align human annotations by maximizing the rewards from the judger noticeably improve the world modeling capability. The website is available at https://worldmodelbench-team.github.io.
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Feb 19, 2025Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs' previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
SimpleStrat: Diversifying Language Model Generation with Stratification
Oct 11, 2024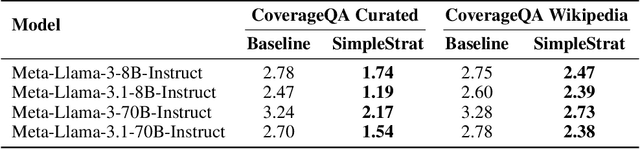
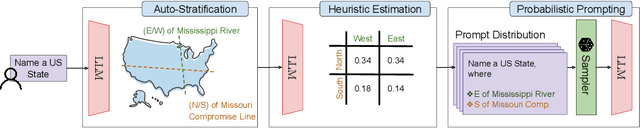

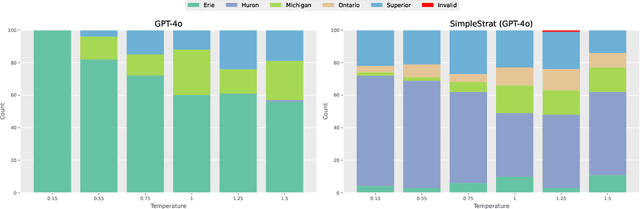
Generating diverse responses from large language models (LLMs) is crucial for applications such as planning/search and synthetic data generation, where diversity provides distinct answers across generations. Prior approaches rely on increasing temperature to increase diversity. However, contrary to popular belief, we show not only does this approach produce lower quality individual generations as temperature increases, but it depends on model's next-token probabilities being similar to the true distribution of answers. We propose \method{}, an alternative approach that uses the language model itself to partition the space into strata. At inference, a random stratum is selected and a sample drawn from within the strata. To measure diversity, we introduce CoverageQA, a dataset of underspecified questions with multiple equally plausible answers, and assess diversity by measuring KL Divergence between the output distribution and uniform distribution over valid ground truth answers. As computing probability per response/solution for proprietary models is infeasible, we measure recall on ground truth solutions. Our evaluation show using SimpleStrat achieves higher recall by 0.05 compared to GPT-4o and 0.36 average reduction in KL Divergence compared to Llama 3.
Stylus: Automatic Adapter Selection for Diffusion Models
Apr 29, 2024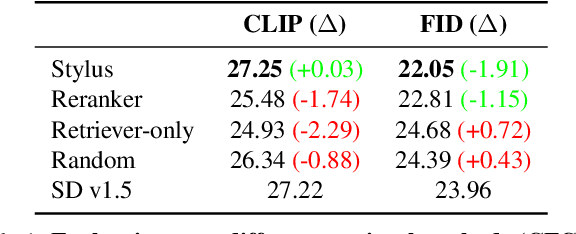
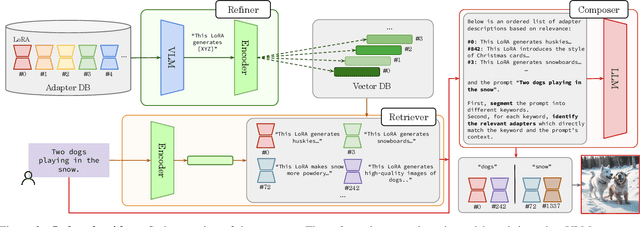

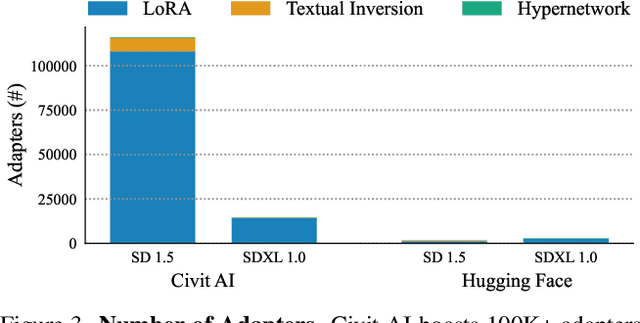
Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model. See stylus-diffusion.github.io for more.
Balsa: Learning a Query Optimizer Without Expert Demonstrations
Jan 05, 2022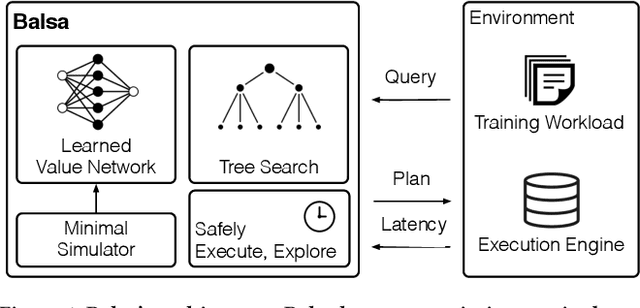


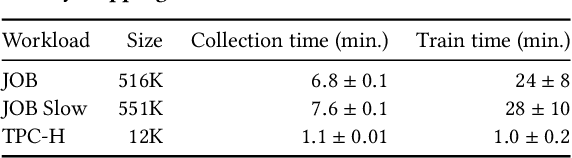
Query optimizers are a performance-critical component in every database system. Due to their complexity, optimizers take experts months to write and years to refine. In this work, we demonstrate for the first time that learning to optimize queries without learning from an expert optimizer is both possible and efficient. We present Balsa, a query optimizer built by deep reinforcement learning. Balsa first learns basic knowledge from a simple, environment-agnostic simulator, followed by safe learning in real execution. On the Join Order Benchmark, Balsa matches the performance of two expert query optimizers, both open-source and commercial, with two hours of learning, and outperforms them by up to 2.8$\times$ in workload runtime after a few more hours. Balsa thus opens the possibility of automatically learning to optimize in future compute environments where expert-designed optimizers do not exist.
MESA: Offline Meta-RL for Safe Adaptation and Fault Tolerance
Dec 07, 2021
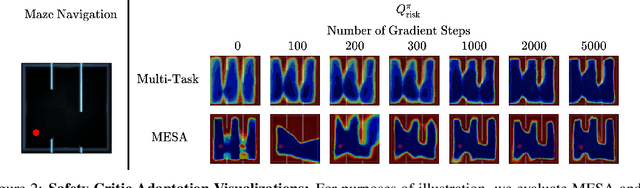

Safe exploration is critical for using reinforcement learning (RL) in risk-sensitive environments. Recent work learns risk measures which measure the probability of violating constraints, which can then be used to enable safety. However, learning such risk measures requires significant interaction with the environment, resulting in excessive constraint violations during learning. Furthermore, these measures are not easily transferable to new environments. We cast safe exploration as an offline meta-RL problem, where the objective is to leverage examples of safe and unsafe behavior across a range of environments to quickly adapt learned risk measures to a new environment with previously unseen dynamics. We then propose MEta-learning for Safe Adaptation (MESA), an approach for meta-learning a risk measure for safe RL. Simulation experiments across 5 continuous control domains suggest that MESA can leverage offline data from a range of different environments to reduce constraint violations in unseen environments by up to a factor of 2 while maintaining task performance. See https://tinyurl.com/safe-meta-rl for code and supplementary material.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021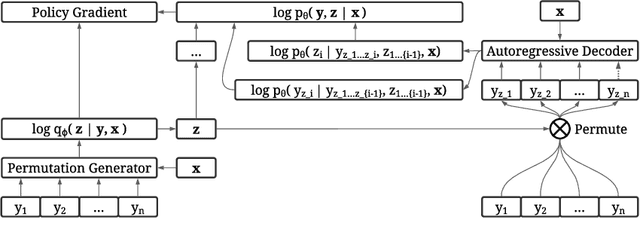

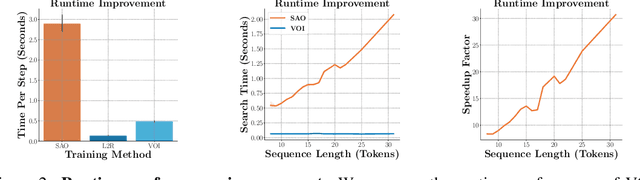

The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.
Accelerating Quadratic Optimization with Reinforcement Learning
Jul 22, 2021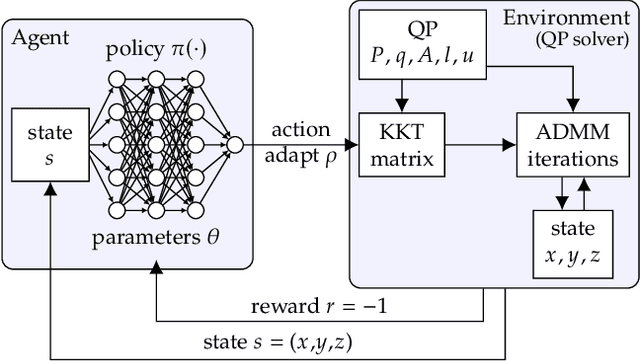

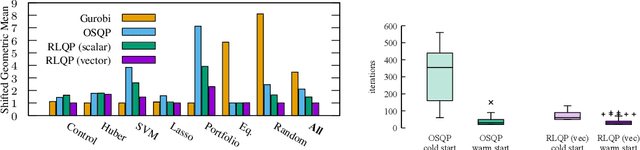

First-order methods for quadratic optimization such as OSQP are widely used for large-scale machine learning and embedded optimal control, where many related problems must be rapidly solved. These methods face two persistent challenges: manual hyperparameter tuning and convergence time to high-accuracy solutions. To address these, we explore how Reinforcement Learning (RL) can learn a policy to tune parameters to accelerate convergence. In experiments with well-known QP benchmarks we find that our RL policy, RLQP, significantly outperforms state-of-the-art QP solvers by up to 3x. RLQP generalizes surprisingly well to previously unseen problems with varying dimension and structure from different applications, including the QPLIB, Netlib LP and Maros-Meszaros problems. Code for RLQP is available at https://github.com/berkeleyautomation/rlqp.
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Mar 31, 2021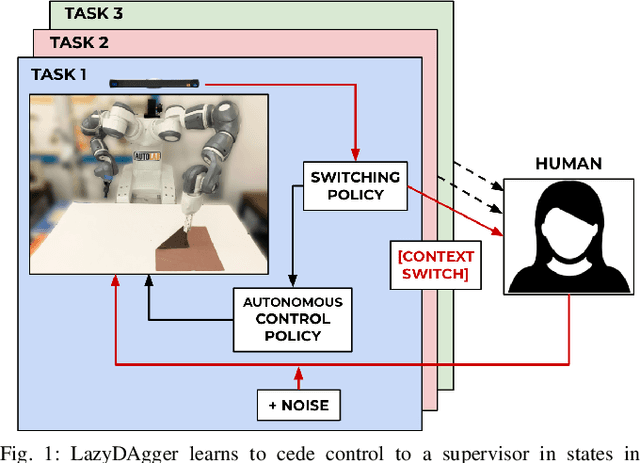
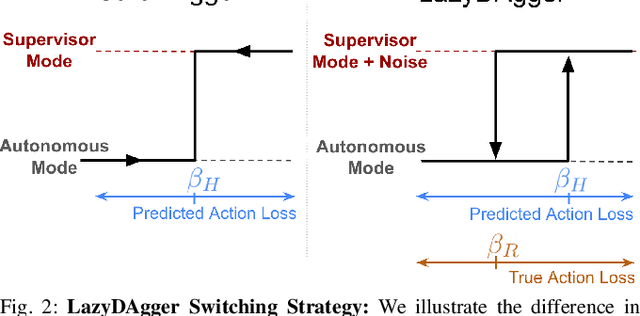
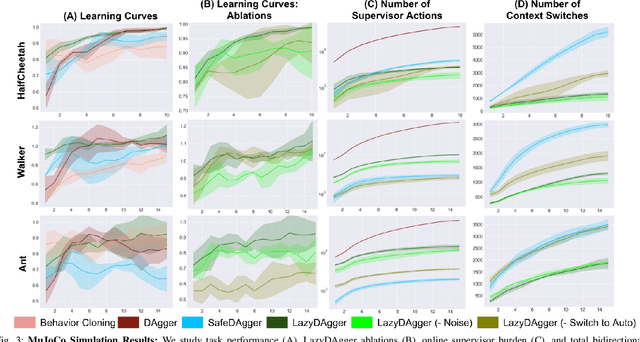
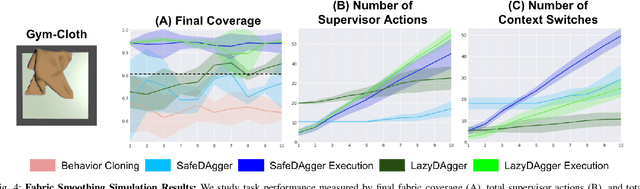
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.
Distributed Reinforcement Learning is a Dataflow Problem
Dec 03, 2020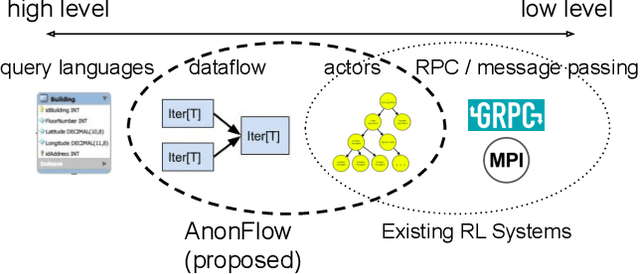
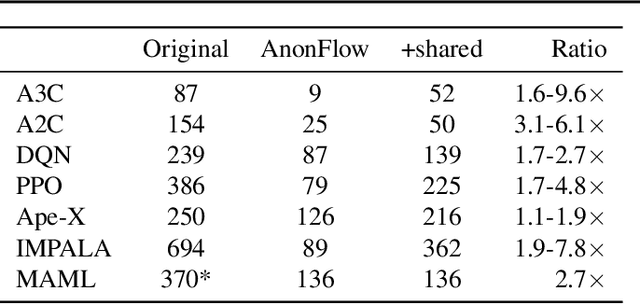
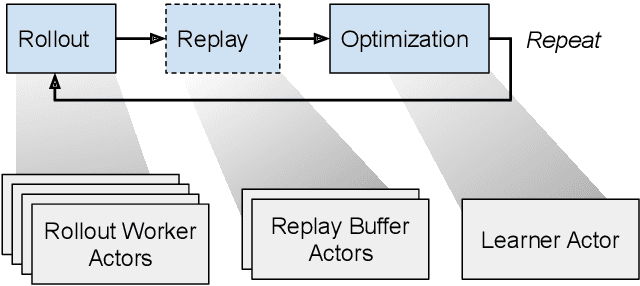
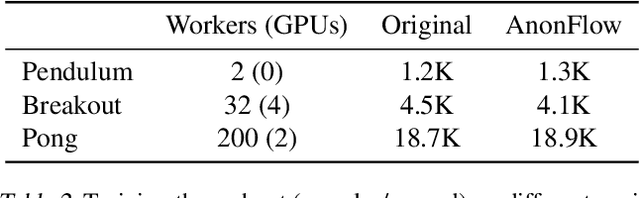
Researchers and practitioners in the field of reinforcement learning (RL) frequently leverage parallel computation, which has led to a plethora of new algorithms and systems in the last few years. In this paper, we re-examine the challenges posed by distributed RL and try to view it through the lens of an old idea: distributed dataflow. We show that viewing RL as a dataflow problem leads to highly composable and performant implementations. We propose AnonFlow, a hybrid actor-dataflow programming model for distributed RL, and validate its practicality by porting the full suite of algorithms in AnonLib, a widely-adopted distributed RL library.