 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnycast Performance in Context
Jun 02, 2026IP anycast lets a service advertise one address from many physical sites, leaving BGP to map each client to a site. It is central to the DNS root server system, public resolvers, and some content delivery networks, yet the same routing mechanism has very different consequences across applications. This paper compares anycast latency in two settings: root DNS, where recursive caching amortizes root-server delay over many users and long time-to-live values, and CDNs, where each additional round trip can directly affect page-load, video-start, or API latency. The synthesis finds that root DNS anycast can exhibit substantial path inflation while still producing limited user-visible delay, whereas CDN anycast requires active engineering of peering, route policy, catchment scope, and measurement feedback to keep inflation small. The paper contributes a comparative latency model, a reproducible measurement design, and an optimization framework that separates resilience-driven anycast objectives from latency-driven objectives. The central conclusion is practical: operators should not optimize root DNS and CDN anycast with the same objective function. For root DNS, robustness, reachability, and cache behavior dominate; for CDN services, tail latency, catchment correctness, and policy control dominate.
Acceptance-Test-Driven Evaluation Protocols for Business-Centric LLM Systems
Jun 01, 2026Large language model (LLM) applications are increasingly expected to satisfy deterministic institutional requirements while relying on probabilistic generative components. This mismatch makes ordinary post-hoc benchmarking insufficient for systems that must be safe, reliable, auditable, and economically useful. This paper contributes an evaluation-protocol extension for operational LLM systems grounded in acceptance-test-driven development, safety engineering, and business-centric validation. The extension translates stakeholder goals into executable behavioral contracts, release gates, monitoring signals, and evidence artifacts before prompt, model, retrieval, or agent changes are accepted. It adapts the red-green-refactor discipline of test-driven development to a red-train-green lifecycle: first define failing acceptance tests for desired behavior, then improve the LLM system through prompt changes, retrieval design, fine-tuning, guardrails, or data augmentation, and finally release only when multidimensional gates are satisfied. The contribution is a governance-oriented metric stack, reference architecture, and empirical protocol for comparing acceptance-test-driven LLM development against prompt-first and benchmark-after workflows.
SECUREVENT: Hybrid AI/ML Security Monitoring for Distributed Event-Based Systems
Jun 01, 2026Distributed event-based systems have become a common substrate for Internet-scale publish/subscribe services, IoT telemetry, cloud-native microservices, and security operations pipelines. Their loose coupling and asynchronous delivery improve scalability, but they also expand the attack surface: publishers, brokers, subscribers, topics, schemas, and temporal ordering can each be abused without a single component observing the whole behavior. This paper proposes SECUREVENT, a hybrid AI/ML security-monitoring architecture for distributed event-based systems. The architecture combines traditional protections such as authenticated transport, topic-level authorization, and signed events with online anomaly detection, graph-aware behavioral features, complex-event policy rules, federated learning, and adversarial-ML governance. A deterministic prototype study over synthetic event-stream attacks illustrates how a hybrid AI/CEP monitor can improve recall over static rules while retaining a low false-positive rate. The central claim is not that machine learning replaces cryptographic and access-control mechanisms, but that model-based security monitoring is necessary when event flows, identities, schemas, and timing relationships are too dynamic for static controls alone.
SPECTRA: Synthetic IR Test Collections with Relevance Oracles and Controlled Distractor Diagnostics
May 29, 2026Scalable information retrieval testing needs corpora that are large enough to stress index construction, ranking latency, query routing, and evaluation tooling, yet human-judged test collections remain expensive and may be unavailable when documents are private or still under design. This paper introduces SPECTRA, a reproducible framework for generating synthetic text corpora and retrieval test collections through a separation of latent topical structure, surface text realization, metadata controls, query intent generation, and deterministic relevance oracles. The framework is intended as a diagnostic complement to Cranfield-style and TREC-style evaluation, not as a replacement for human assessment. A single-process Python prototype generated corpora up to 60,000 documents and 9.61 million tokens while preserving controllable long-tail vocabulary growth and producing graded relevance labels for 96 queries. In the local simulation study, generation remained close to linear at roughly 12K to 14K documents per second, estimated Zipf slopes stayed near 0.86 in absolute value, and increasing cross-topic distractor text reduced BM25 nDCG@10 from 1.00 at 2% distractors to 0.43 at 36% distractors. These results show that lightweight synthetic corpora can expose retrieval-system scaling and failure modes before costly collection construction begins.
Feature-Optimized Vision for Adaptive 3D Scene Reconstruction
May 29, 2026Three-dimensional scene reconstruction depends on local image evidence that is both visually discriminative and geometrically useful. Fixed feature thresholds and uniform feature budgets are easy to deploy, but they can waste computation on repeated texture, low-parallax regions, or unstable points. This paper proposes an adaptive feature-optimized vision front end for 3D reconstruction. The method scores candidate features by texture, repeatability, distinctiveness, expected triangulation angle, and spatial coverage, then allocates a per-view feature budget to maximize useful tracks under a fixed reconstruction pipeline. A small synthetic multi-view prototype evaluates four selection policies across corridor, facade, object-table, and cluttered scenes. Compared with random, texture-only, and uniform-grid baselines, the adaptive policy obtains the best quality-aware completeness and the lowest aggregate reconstruction RMSE while preserving broad image coverage. The result is not a replacement for modern learned matching or neural reconstruction systems; it is a modular front-end policy that can make classical and learned 3D pipelines more deliberate about which visual evidence they spend compute on.
SEMBridge: Tagless-Final Program Semantics with Weakest-Precondition and Bounded-Checking Interpretations
May 29, 2026Formal methods provide rigorous accounts of program behavior, but practical software engineering often works through executable libraries, tests, and incremental design. This paper presents SEMBridge, a small tagless-final framework for generating weakest-precondition and bounded-checking interpretations from the same executable object programs. Instead of committing a program semantics to one abstract syntax tree and then writing separate traversals, object programs are written once against a semantic interface and interpreted into multiple meanings: readable code, concrete execution, predicate transformers, bounded counterexample search, and future proof-assistant or SMT back ends. The Python prototype implements a loop-free imperative core with assignments, conditionals, assumptions, and assertions. Across five example programs, the same tagless-final definitions generated executable state transformers and verification conditions that passed bounded checking over domains up to 729 states. The contribution is not a Scala code-generation system or a new verifier, but a compact architecture for keeping executable semantics, weakest-precondition artifacts, and bounded validation synchronized.
Predicting Pedestrian Crosswalk Behavior Using Convolutional Neural Networks
Aug 08, 2022


A common yet potentially dangerous task is the act of crossing the street. Pedestrian accidents contribute a significant amount to the high number of annual traffic casualties, which is why it is crucial for pedestrians to use safety measures such as a crosswalk. However, people often forget to activate a crosswalk light or are unable to do so -- such as those who are visually impaired or have occupied hands. Other pedestrians are simply careless and find the crosswalk signals a hassle, which can result in an accident where a car hits them. In this paper, we consider an improvement to the crosswalk system by designing a system that can detect pedestrians and triggering the crosswalk signal automatically. We collect a dataset of images that we then use to train a convolutional neural network to distinguish between pedestrians (including bicycle riders) and various false alarms. The resulting system can capture and evaluate images in real time, and the result can be used to automatically activate systems a crosswalk light. After extensive testing of our system in real-world environments, we conclude that it is feasible as a back-up system that can compliment existing crosswalk buttons, and thereby improve the overall safety of crossing the street.
Distributed Reinforcement Learning is a Dataflow Problem
Dec 03, 2020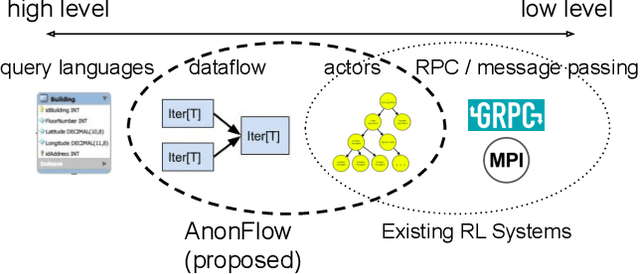
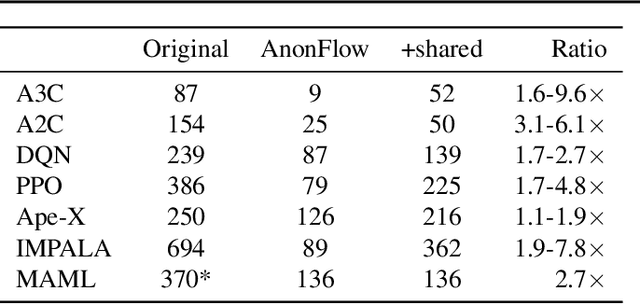
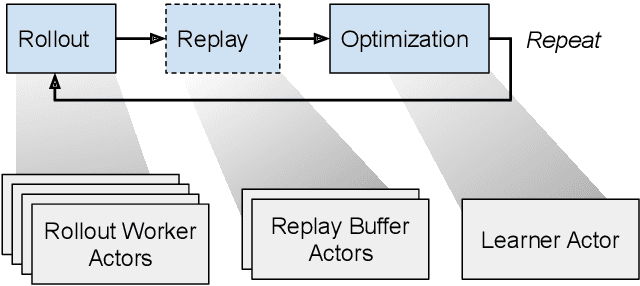
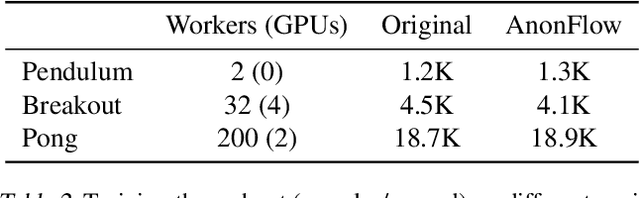
Researchers and practitioners in the field of reinforcement learning (RL) frequently leverage parallel computation, which has led to a plethora of new algorithms and systems in the last few years. In this paper, we re-examine the challenges posed by distributed RL and try to view it through the lens of an old idea: distributed dataflow. We show that viewing RL as a dataflow problem leads to highly composable and performant implementations. We propose AnonFlow, a hybrid actor-dataflow programming model for distributed RL, and validate its practicality by porting the full suite of algorithms in AnonLib, a widely-adopted distributed RL library.
Variable Skipping for Autoregressive Range Density Estimation
Jul 10, 2020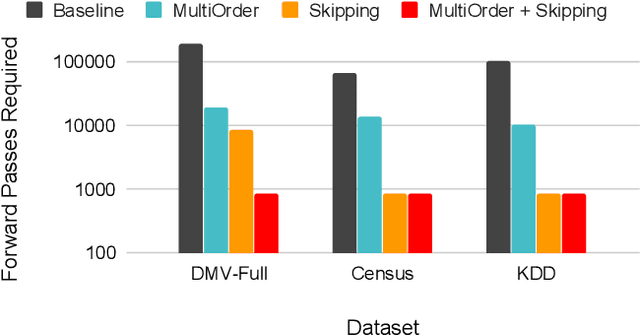
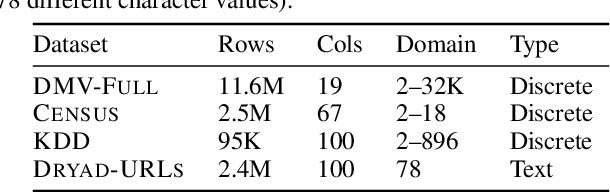
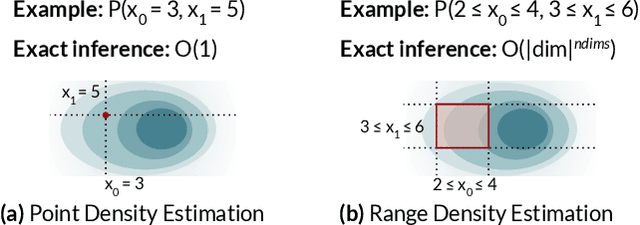
Deep autoregressive models compute point likelihood estimates of individual data points. However, many applications (i.e., database cardinality estimation) require estimating range densities, a capability that is under-explored by current neural density estimation literature. In these applications, fast and accurate range density estimates over high-dimensional data directly impact user-perceived performance. In this paper, we explore a technique, variable skipping, for accelerating range density estimation over deep autoregressive models. This technique exploits the sparse structure of range density queries to avoid sampling unnecessary variables during approximate inference. We show that variable skipping provides 10-100$\times$ efficiency improvements when targeting challenging high-quantile error metrics, enables complex applications such as text pattern matching, and can be realized via a simple data augmentation procedure without changing the usual maximum likelihood objective.
NeuroCard: One Cardinality Estimator for All Tables
Jun 15, 2020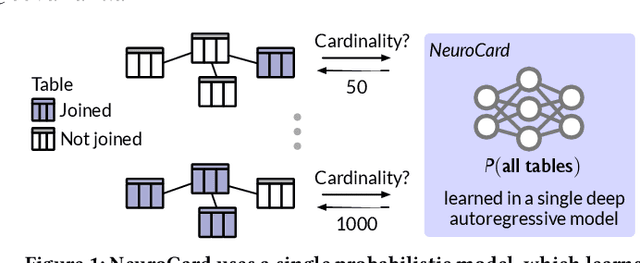
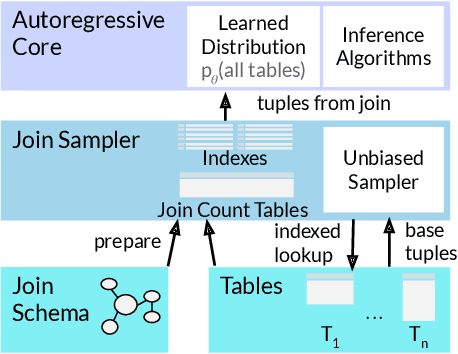
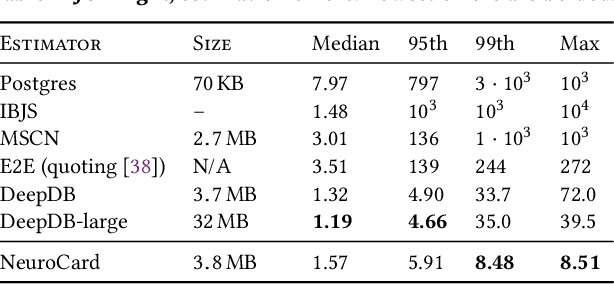
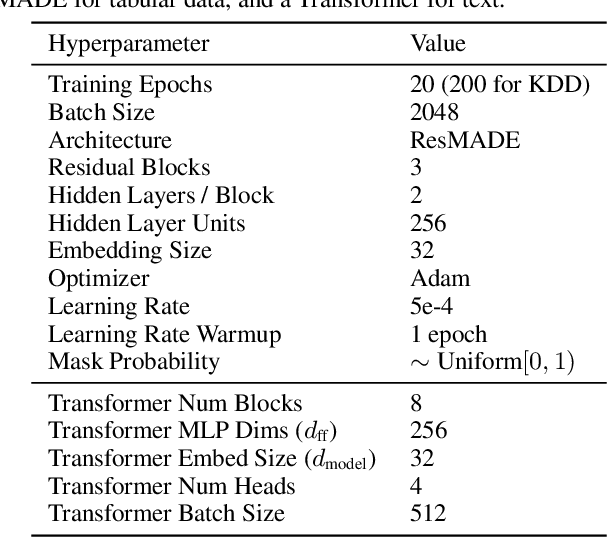
Query optimizers rely on accurate cardinality estimates to produce good execution plans. Despite decades of research, existing cardinality estimators are inaccurate for complex queries, due to making lossy modeling assumptions and not capturing inter-table correlations. In this work, we show that it is possible to learn the correlations across all tables in a database without any independence assumptions. We present NeuroCard, a join cardinality estimator that builds a single neural density estimator over an entire database. Leveraging join sampling and modern deep autoregressive models, NeuroCard makes no inter-table or inter-column independence assumptions in its probabilistic modeling. NeuroCard achieves orders of magnitude higher accuracy than the best prior methods (a new state-of-the-art result of 8.5$\times$ maximum error on JOB-light), scales to dozens of tables, while being compact in space (several MBs) and efficient to construct or update (seconds to minutes).