 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuncFooler: A Practical Black-box Attack Against Learning-based Binary Code Similarity Detection Methods
Aug 26, 2022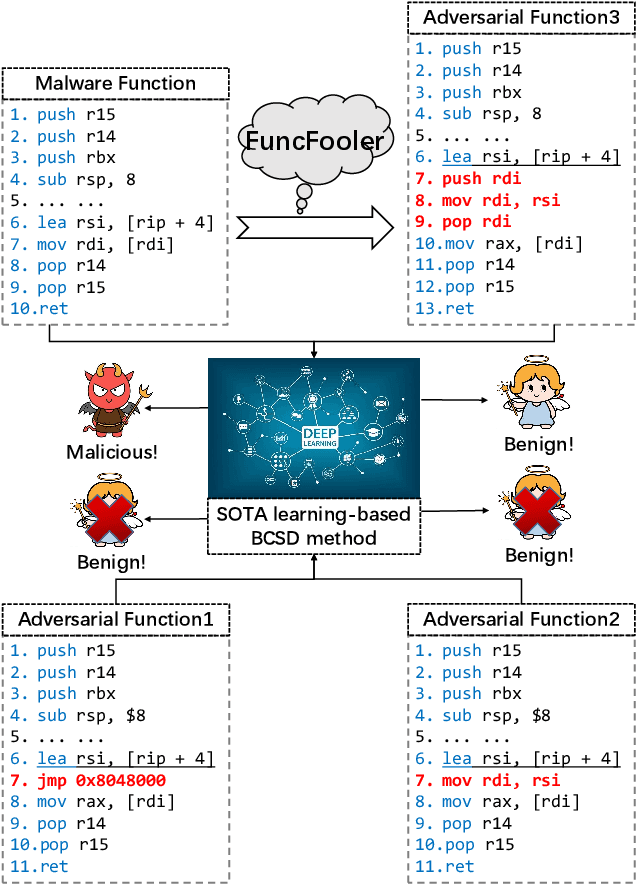
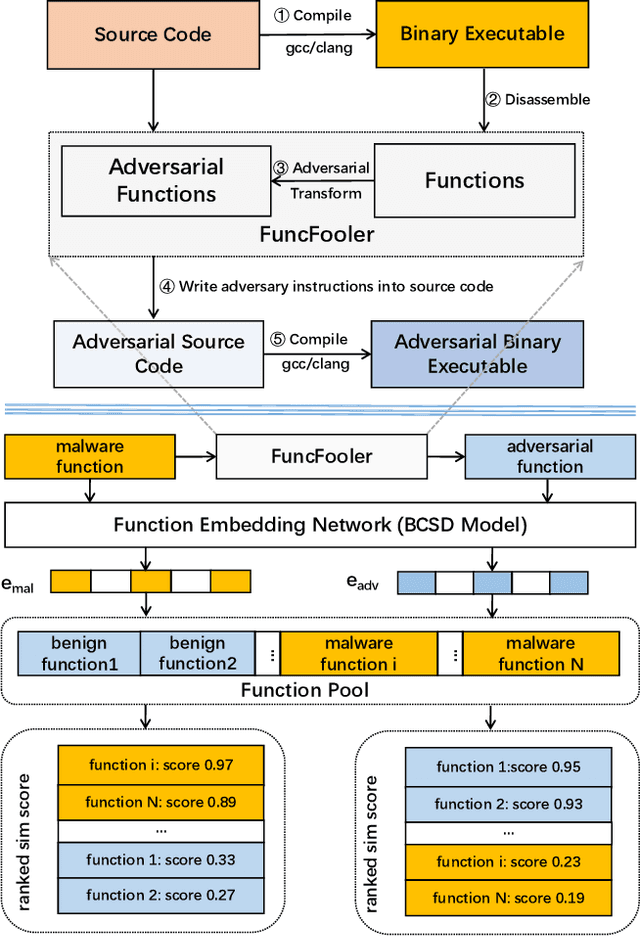
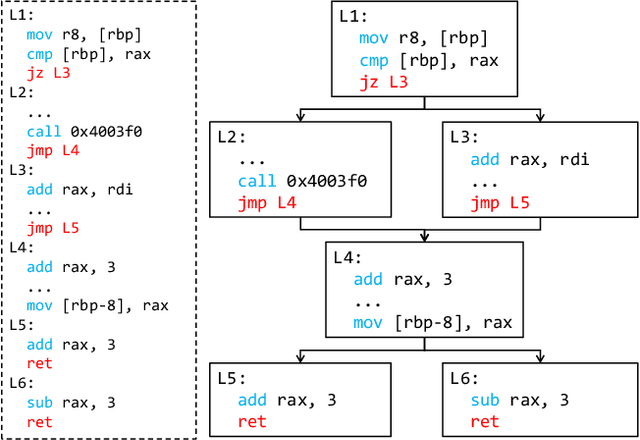

The binary code similarity detection (BCSD) method measures the similarity of two binary executable codes. Recently, the learning-based BCSD methods have achieved great success, outperforming traditional BCSD in detection accuracy and efficiency. However, the existing studies are rather sparse on the adversarial vulnerability of the learning-based BCSD methods, which cause hazards in security-related applications. To evaluate the adversarial robustness, this paper designs an efficient and black-box adversarial code generation algorithm, namely, FuncFooler. FuncFooler constrains the adversarial codes 1) to keep unchanged the program's control flow graph (CFG), and 2) to preserve the same semantic meaning. Specifically, FuncFooler consecutively 1) determines vulnerable candidates in the malicious code, 2) chooses and inserts the adversarial instructions from the benign code, and 3) corrects the semantic side effect of the adversarial code to meet the constraints. Empirically, our FuncFooler can successfully attack the three learning-based BCSD models, including SAFE, Asm2Vec, and jTrans, which calls into question whether the learning-based BCSD is desirable.
DVHN: A Deep Hashing Framework for Large-scale Vehicle Re-identification
Dec 09, 2021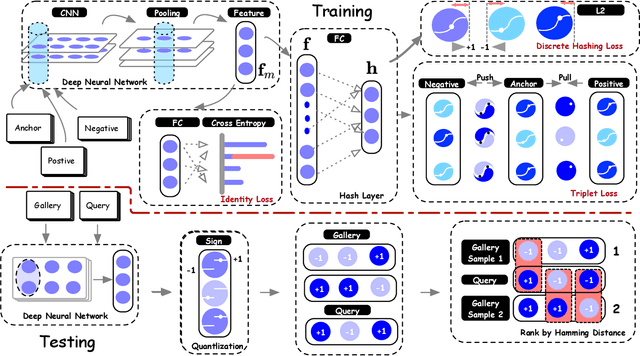
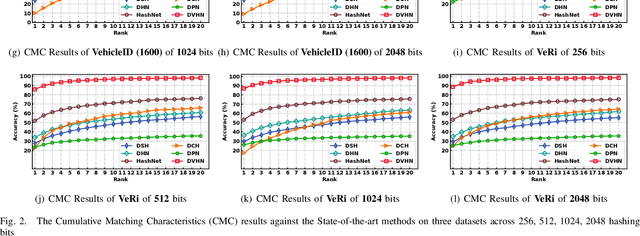
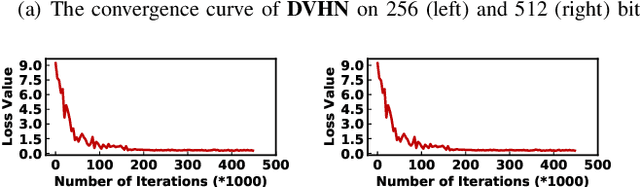
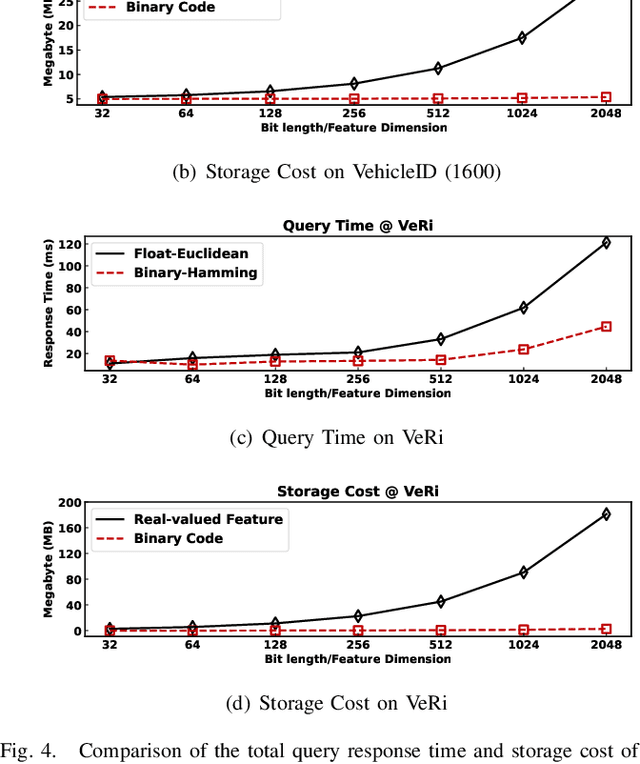
In this paper, we make the very first attempt to investigate the integration of deep hash learning with vehicle re-identification. We propose a deep hash-based vehicle re-identification framework, dubbed DVHN, which substantially reduces memory usage and promotes retrieval efficiency while reserving nearest neighbor search accuracy. Concretely,~DVHN directly learns discrete compact binary hash codes for each image by jointly optimizing the feature learning network and the hash code generating module. Specifically, we directly constrain the output from the convolutional neural network to be discrete binary codes and ensure the learned binary codes are optimal for classification. To optimize the deep discrete hashing framework, we further propose an alternating minimization method for learning binary similarity-preserved hashing codes. Extensive experiments on two widely-studied vehicle re-identification datasets- \textbf{VehicleID} and \textbf{VeRi}-~have demonstrated the superiority of our method against the state-of-the-art deep hash methods. \textbf{DVHN} of $2048$ bits can achieve 13.94\% and 10.21\% accuracy improvement in terms of \textbf{mAP} and \textbf{Rank@1} for \textbf{VehicleID (800)} dataset. For \textbf{VeRi}, we achieve 35.45\% and 32.72\% performance gains for \textbf{Rank@1} and \textbf{mAP}, respectively.
Selectivity Estimation with Deep Likelihood Models
May 10, 2019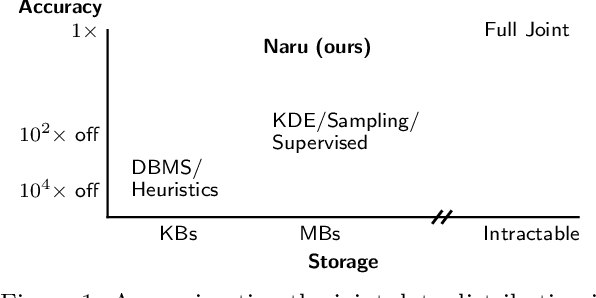
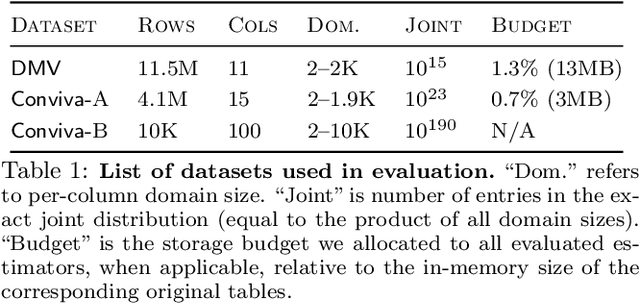
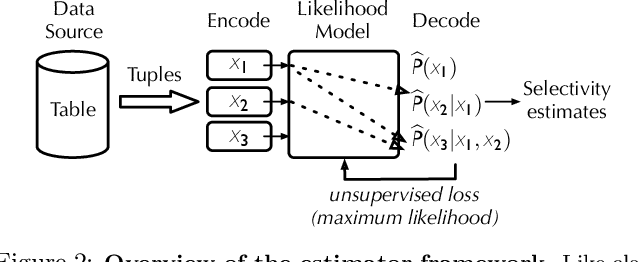
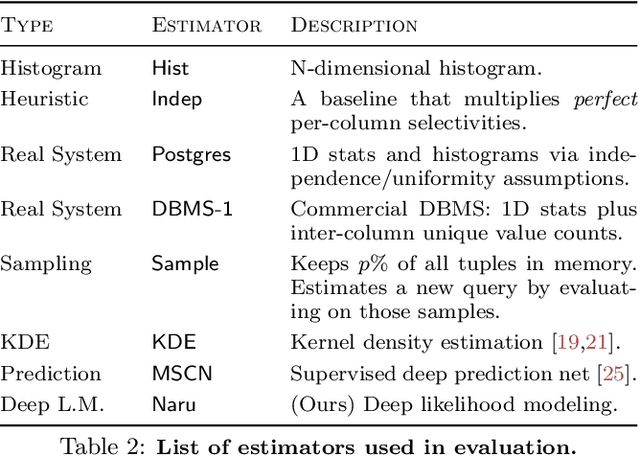
Selectivity estimation has long been grounded in statistical tools for density estimation. To capture the rich multivariate distributions of relational tables, we propose the use of a new type of high-capacity statistical model: deep likelihood models. However, direct application of these models leads to a limited estimator that is prohibitively expensive to evaluate for range and wildcard predicates. To make a truly usable estimator, we develop a Monte Carlo integration scheme on top of likelihood models that can efficiently handle range queries with dozens of filters or more. Like classical synopses, our estimator summarizes the data without supervision. Unlike previous solutions, our estimator approximates the joint data distribution without any independence assumptions. When evaluated on real-world datasets and compared against real systems and dominant families of techniques, our likelihood model based estimator achieves single-digit multiplicative error at tail, a 40-200$\times$ accuracy improvement over the second best method, and is space- and runtime-efficient.