 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact-Aware Neural Dynamics
Jan 19, 2026High-fidelity physics simulation is essential for scalable robotic learning, but the sim-to-real gap persists, especially for tasks involving complex, dynamic, and discontinuous interactions like physical contacts. Explicit system identification, which tunes explicit simulator parameters, is often insufficient to align the intricate, high-dimensional, and state-dependent dynamics of the real world. To overcome this, we propose an implicit sim-to-real alignment framework that learns to directly align the simulator's dynamics with contact information. Our method treats the off-the-shelf simulator as a base prior and learns a contact-aware neural dynamics model to refine simulated states using real-world observations. We show that using tactile contact information from robotic hands can effectively model the non-smooth discontinuities inherent in contact-rich tasks, resulting in a neural dynamics model grounded by real-world data. We demonstrate that this learned forward dynamics model improves state prediction accuracy and can be effectively used to predict policy performance and refine policies trained purely in standard simulators, offering a scalable, data-driven approach to sim-to-real alignment.
Variable Skipping for Autoregressive Range Density Estimation
Jul 10, 2020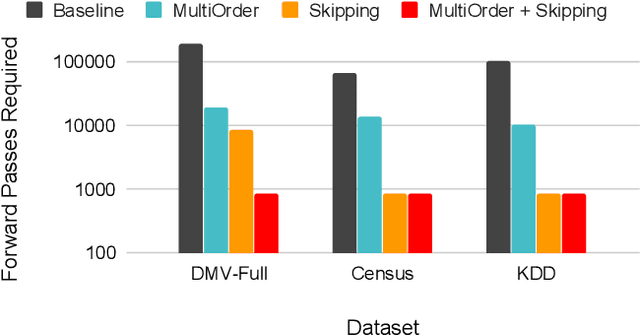
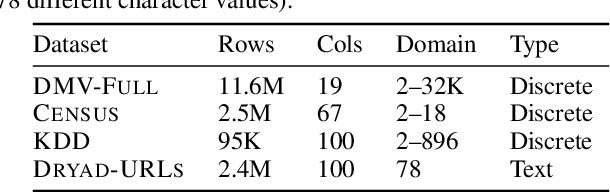
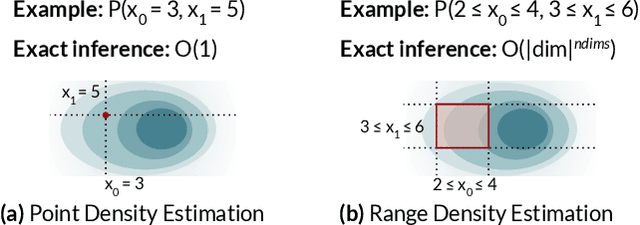
Deep autoregressive models compute point likelihood estimates of individual data points. However, many applications (i.e., database cardinality estimation) require estimating range densities, a capability that is under-explored by current neural density estimation literature. In these applications, fast and accurate range density estimates over high-dimensional data directly impact user-perceived performance. In this paper, we explore a technique, variable skipping, for accelerating range density estimation over deep autoregressive models. This technique exploits the sparse structure of range density queries to avoid sampling unnecessary variables during approximate inference. We show that variable skipping provides 10-100$\times$ efficiency improvements when targeting challenging high-quantile error metrics, enables complex applications such as text pattern matching, and can be realized via a simple data augmentation procedure without changing the usual maximum likelihood objective.
NeuroCard: One Cardinality Estimator for All Tables
Jun 15, 2020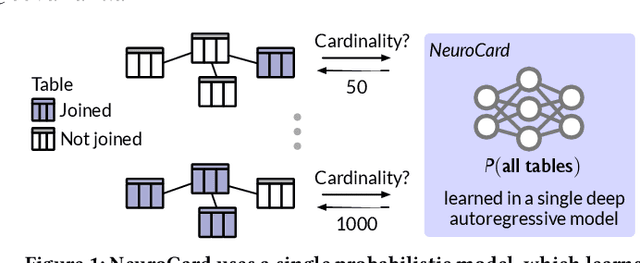
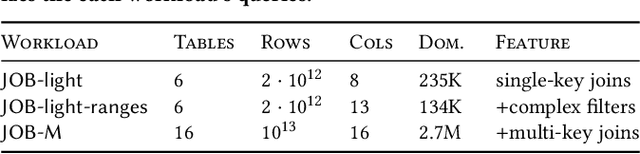
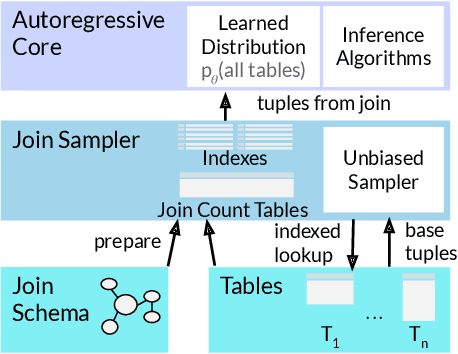
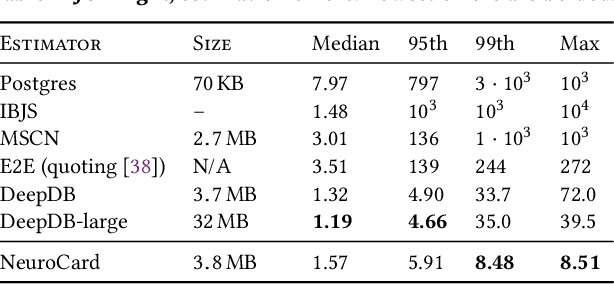
Query optimizers rely on accurate cardinality estimates to produce good execution plans. Despite decades of research, existing cardinality estimators are inaccurate for complex queries, due to making lossy modeling assumptions and not capturing inter-table correlations. In this work, we show that it is possible to learn the correlations across all tables in a database without any independence assumptions. We present NeuroCard, a join cardinality estimator that builds a single neural density estimator over an entire database. Leveraging join sampling and modern deep autoregressive models, NeuroCard makes no inter-table or inter-column independence assumptions in its probabilistic modeling. NeuroCard achieves orders of magnitude higher accuracy than the best prior methods (a new state-of-the-art result of 8.5$\times$ maximum error on JOB-light), scales to dozens of tables, while being compact in space (several MBs) and efficient to construct or update (seconds to minutes).
Evaluating Protein Transfer Learning with TAPE
Jun 19, 2019
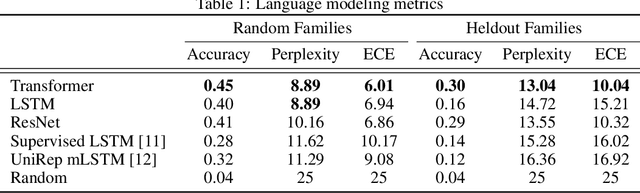
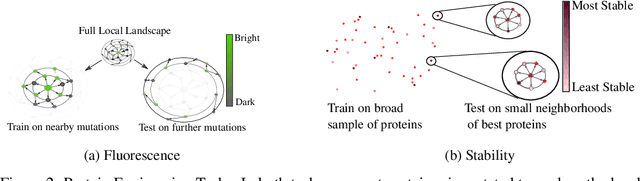
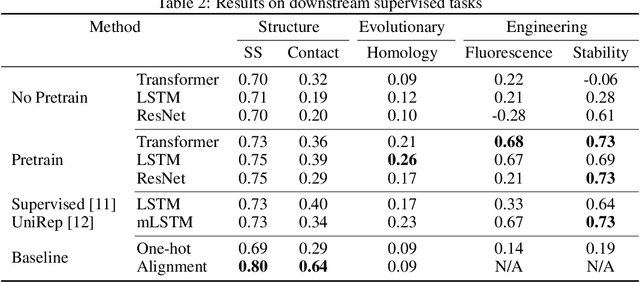
Protein modeling is an increasingly popular area of machine learning research. Semi-supervised learning has emerged as an important paradigm in protein modeling due to the high cost of acquiring supervised protein labels, but the current literature is fragmented when it comes to datasets and standardized evaluation techniques. To facilitate progress in this field, we introduce the Tasks Assessing Protein Embeddings (TAPE), a set of five biologically relevant semi-supervised learning tasks spread across different domains of protein biology. We curate tasks into specific training, validation, and test splits to ensure that each task tests biologically relevant generalization that transfers to real-life scenarios. We benchmark a range of approaches to semi-supervised protein representation learning, which span recent work as well as canonical sequence learning techniques. We find that self-supervised pretraining is helpful for almost all models on all tasks, more than doubling performance in some cases. Despite this increase, in several cases features learned by self-supervised pretraining still lag behind features extracted by state-of-the-art non-neural techniques. This gap in performance suggests a huge opportunity for innovative architecture design and improved modeling paradigms that better capture the signal in biological sequences. TAPE will help the machine learning community focus effort on scientifically relevant problems. Toward this end, all data and code used to run these experiments are available at https://github.com/songlab-cal/tape.
Selectivity Estimation with Deep Likelihood Models
May 10, 2019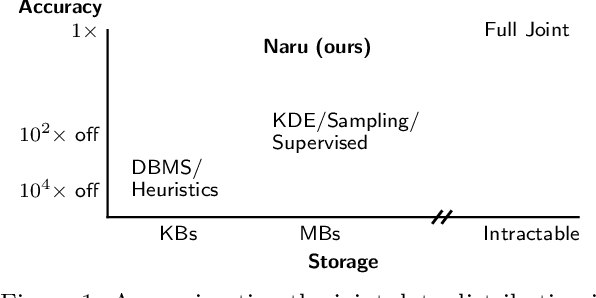
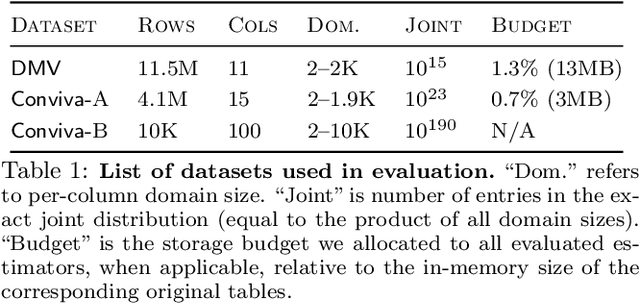
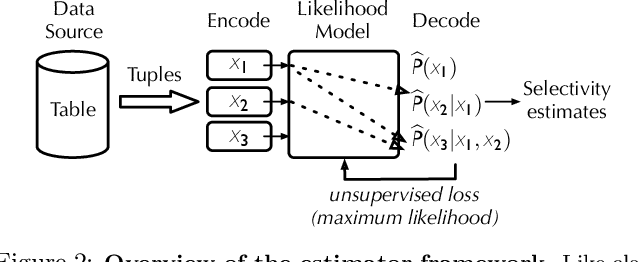
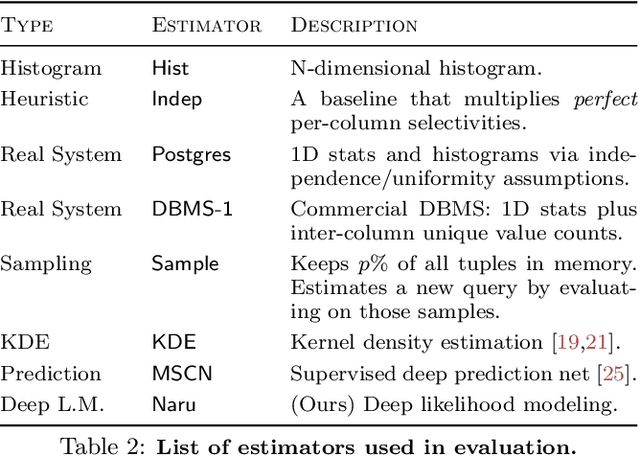
Selectivity estimation has long been grounded in statistical tools for density estimation. To capture the rich multivariate distributions of relational tables, we propose the use of a new type of high-capacity statistical model: deep likelihood models. However, direct application of these models leads to a limited estimator that is prohibitively expensive to evaluate for range and wildcard predicates. To make a truly usable estimator, we develop a Monte Carlo integration scheme on top of likelihood models that can efficiently handle range queries with dozens of filters or more. Like classical synopses, our estimator summarizes the data without supervision. Unlike previous solutions, our estimator approximates the joint data distribution without any independence assumptions. When evaluated on real-world datasets and compared against real systems and dominant families of techniques, our likelihood model based estimator achieves single-digit multiplicative error at tail, a 40-200$\times$ accuracy improvement over the second best method, and is space- and runtime-efficient.
Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design
Feb 01, 2019



Flow-based generative models are powerful exact likelihood models with efficient sampling and inference. Despite their computational efficiency, flow-based models generally have much worse density modeling performance compared to state-of-the-art autoregressive models. In this paper, we investigate and improve upon three limiting design choices employed by flow-based models in prior work: the use of uniform noise for dequantization, the use of inexpressive affine flows, and the use of purely convolutional conditioning networks in coupling layers. Based on our findings, we propose Flow++, a new flow-based model that is now the state-of-the-art non-autoregressive model for unconditional density estimation on standard image benchmarks. Our work has begun to close the significant performance gap that has so far existed between autoregressive models and flow-based models. Our implementation is available at https://github.com/aravind0706/flowpp.
Model-Ensemble Trust-Region Policy Optimization
Oct 05, 2018
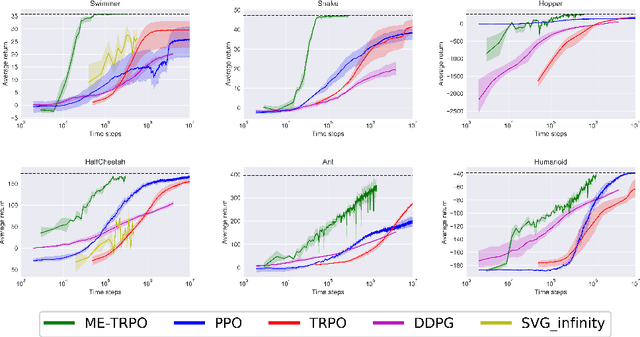
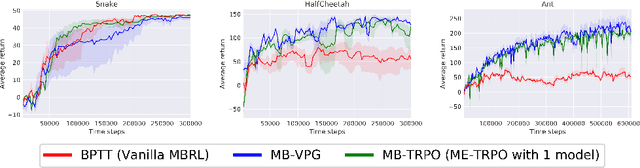
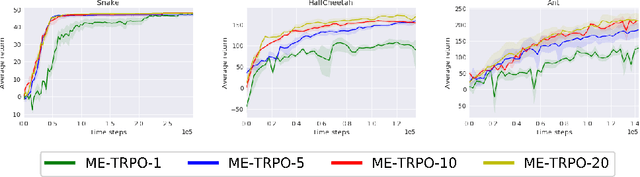
Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.
Variance Reduction for Policy Gradient with Action-Dependent Factorized Baselines
Mar 20, 2018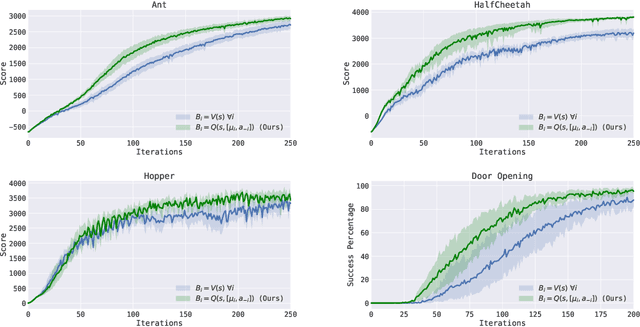

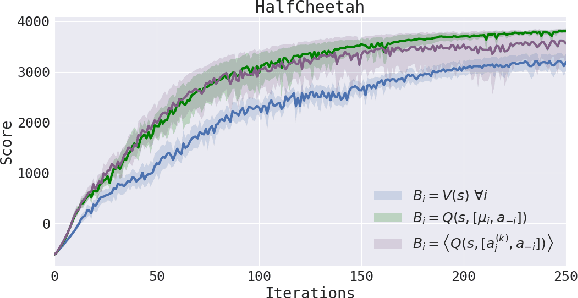
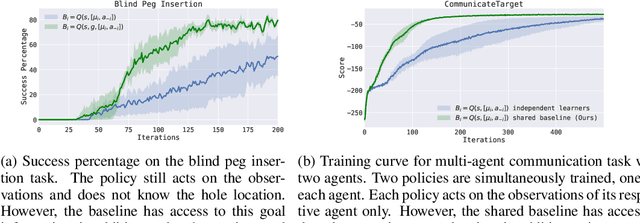
Policy gradient methods have enjoyed great success in deep reinforcement learning but suffer from high variance of gradient estimates. The high variance problem is particularly exasperated in problems with long horizons or high-dimensional action spaces. To mitigate this issue, we derive a bias-free action-dependent baseline for variance reduction which fully exploits the structural form of the stochastic policy itself and does not make any additional assumptions about the MDP. We demonstrate and quantify the benefit of the action-dependent baseline through both theoretical analysis as well as numerical results, including an analysis of the suboptimality of the optimal state-dependent baseline. The result is a computationally efficient policy gradient algorithm, which scales to high-dimensional control problems, as demonstrated by a synthetic 2000-dimensional target matching task. Our experimental results indicate that action-dependent baselines allow for faster learning on standard reinforcement learning benchmarks and high-dimensional hand manipulation and synthetic tasks. Finally, we show that the general idea of including additional information in baselines for improved variance reduction can be extended to partially observed and multi-agent tasks.
Some Considerations on Learning to Explore via Meta-Reinforcement Learning
Mar 03, 2018
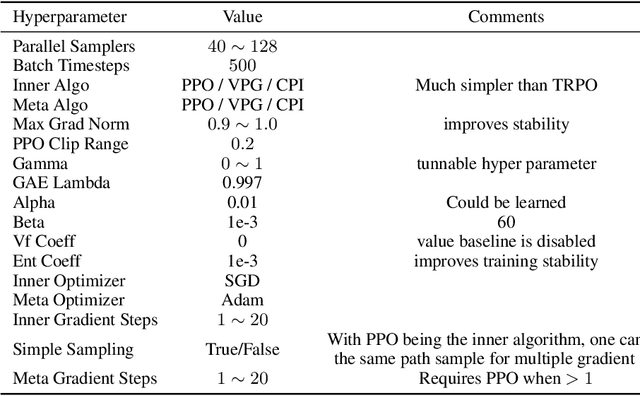
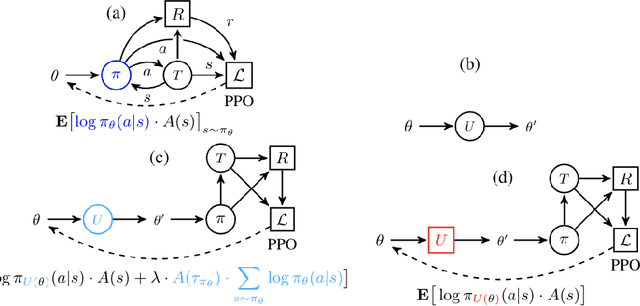

We consider the problem of exploration in meta reinforcement learning. Two new meta reinforcement learning algorithms are suggested: E-MAML and E-$\text{RL}^2$. Results are presented on a novel environment we call `Krazy World' and a set of maze environments. We show E-MAML and E-$\text{RL}^2$ deliver better performance on tasks where exploration is important.
#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning
Dec 05, 2017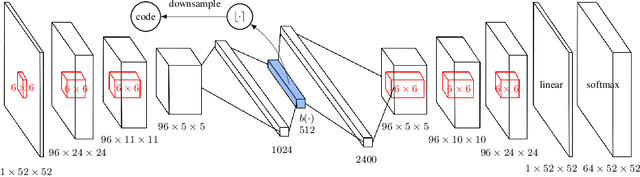
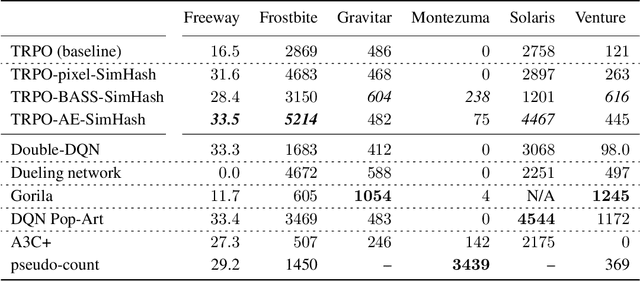
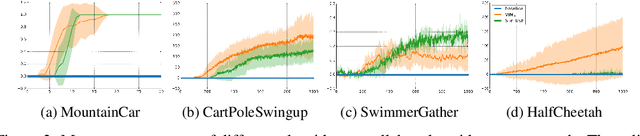
Count-based exploration algorithms are known to perform near-optimally when used in conjunction with tabular reinforcement learning (RL) methods for solving small discrete Markov decision processes (MDPs). It is generally thought that count-based methods cannot be applied in high-dimensional state spaces, since most states will only occur once. Recent deep RL exploration strategies are able to deal with high-dimensional continuous state spaces through complex heuristics, often relying on optimism in the face of uncertainty or intrinsic motivation. In this work, we describe a surprising finding: a simple generalization of the classic count-based approach can reach near state-of-the-art performance on various high-dimensional and/or continuous deep RL benchmarks. States are mapped to hash codes, which allows to count their occurrences with a hash table. These counts are then used to compute a reward bonus according to the classic count-based exploration theory. We find that simple hash functions can achieve surprisingly good results on many challenging tasks. Furthermore, we show that a domain-dependent learned hash code may further improve these results. Detailed analysis reveals important aspects of a good hash function: 1) having appropriate granularity and 2) encoding information relevant to solving the MDP. This exploration strategy achieves near state-of-the-art performance on both continuous control tasks and Atari 2600 games, hence providing a simple yet powerful baseline for solving MDPs that require considerable exploration.