 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction for Policy Gradient with Action-Dependent Factorized Baselines
Mar 20, 2018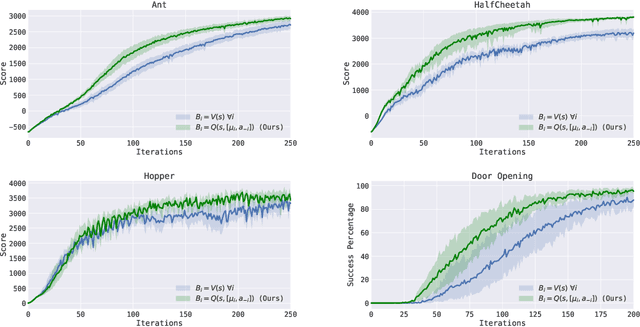

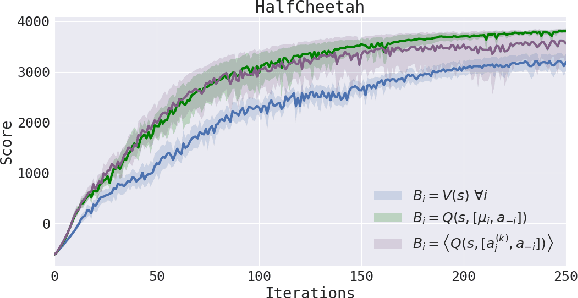
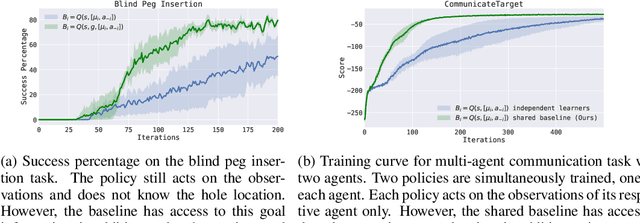
Policy gradient methods have enjoyed great success in deep reinforcement learning but suffer from high variance of gradient estimates. The high variance problem is particularly exasperated in problems with long horizons or high-dimensional action spaces. To mitigate this issue, we derive a bias-free action-dependent baseline for variance reduction which fully exploits the structural form of the stochastic policy itself and does not make any additional assumptions about the MDP. We demonstrate and quantify the benefit of the action-dependent baseline through both theoretical analysis as well as numerical results, including an analysis of the suboptimality of the optimal state-dependent baseline. The result is a computationally efficient policy gradient algorithm, which scales to high-dimensional control problems, as demonstrated by a synthetic 2000-dimensional target matching task. Our experimental results indicate that action-dependent baselines allow for faster learning on standard reinforcement learning benchmarks and high-dimensional hand manipulation and synthetic tasks. Finally, we show that the general idea of including additional information in baselines for improved variance reduction can be extended to partially observed and multi-agent tasks.
Flow: Architecture and Benchmarking for Reinforcement Learning in Traffic Control
Oct 16, 2017
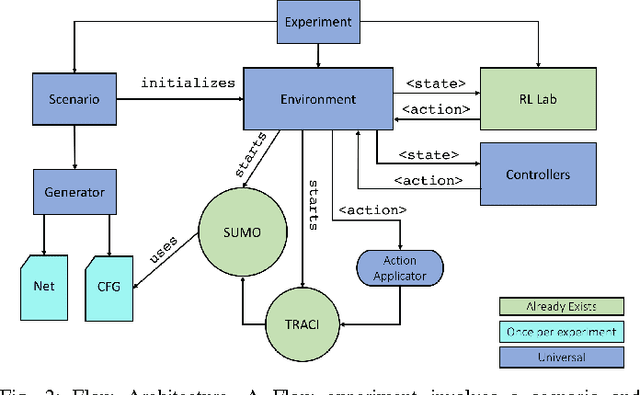

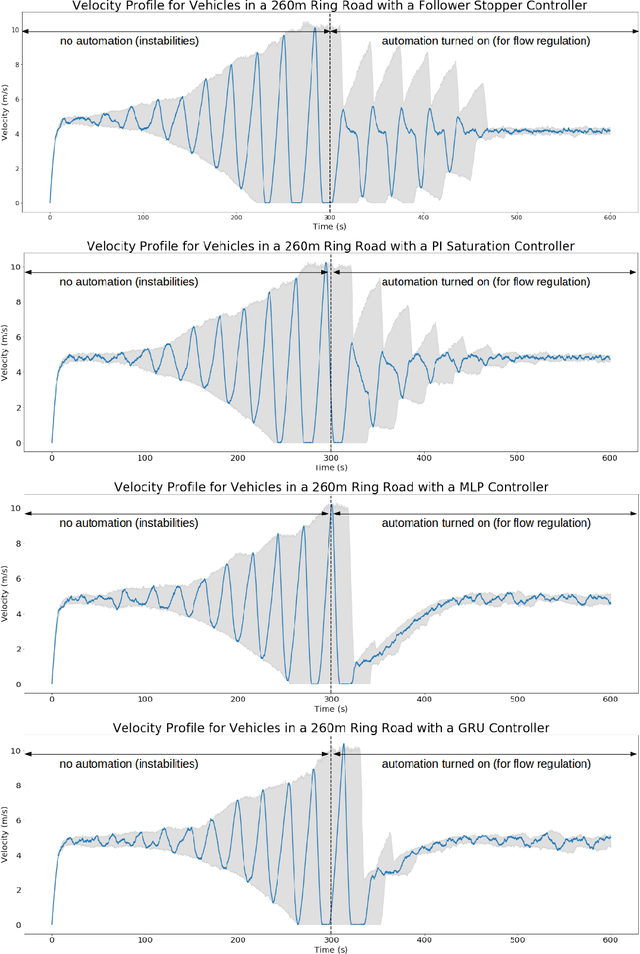
Flow is a new computational framework, built to support a key need triggered by the rapid growth of autonomy in ground traffic: controllers for autonomous vehicles in the presence of complex nonlinear dynamics in traffic. Leveraging recent advances in deep Reinforcement Learning (RL), Flow enables the use of RL methods such as policy gradient for traffic control and enables benchmarking the performance of classical (including hand-designed) controllers with learned policies (control laws). Flow integrates traffic microsimulator SUMO with deep reinforcement learning library rllab and enables the easy design of traffic tasks, including different networks configurations and vehicle dynamics. We use Flow to develop reliable controllers for complex problems, such as controlling mixed-autonomy traffic (involving both autonomous and human-driven vehicles) in a ring road. For this, we first show that state-of-the-art hand-designed controllers excel when in-distribution, but fail to generalize; then, we show that even simple neural network policies can solve the stabilization task across density settings and generalize to out-of-distribution settings.