 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMAgnet: Parameter-Space EMA Regularization for Policy Gradient Self-Play in Large Games
Jun 22, 2026Recent work has established that regularized policy gradient methods such as PPO, when used in self-play, can match or exceed specialized game-theoretic algorithms for solving two-player zero-sum imperfect-information games. The uniform distribution has emerged as a strong policy regularization target for this purpose, but it regularizes equally toward all actions regardless of their viability. We introduce EMAgnet, which instead regularizes toward an exponential moving average (EMA) of the last-iterate policy's parameters, providing an adaptive regularization target that evolves with the agent's improving strategy. We evaluate EMAgnet on both standard two-player zero-sum benchmarks and modified benchmarks with exploration challenges and large numbers of strictly dominated strategies. Relative to PPO self-play with uniform-magnet regularization under both linear and power-law annealing schedules, EMAgnet achieves lower exploitability in the majority of tested environments, with consistent performance gains across games containing strictly dominated strategies.
Scaling Self-Play for End-to-End Driving
Jun 17, 2026End-to-end autonomous driving models are typically trained on offline human-demonstration datasets that provide limited state coverage and often no closed-loop feedback, making them prone to compounding errors when deployed in closed-loop and brittle to long-tail agent interactions. To overcome these limitations, we propose an alternative strategy for training end-to-end driving models: large-scale self-play directly from pixels in simulation. While prior self-play approaches have shown promising transfer to real-world driving, they typically assume vectorized Bird's-Eye-View (BEV) observations that are incompatible with end-to-end policies operating directly on sensor observations. To this end, we introduce Gigapixel, a high-throughput batched driving simulator with perspective rendering, enabling scalable self-play directly from pixel observations. Rather than targeting compute-costly photorealistic sensor simulation, Gigapixel renders a simplified bounding-box world that preserves essential scene structure while achieving throughput at 50k agent steps per second. Since direct pixel-space self-play RL is prohibitively sample-inefficient at end-to-end model scale, we propose self-play DAgger training: we train pixel-based policies in self-play via on-policy distillation from a privileged RL teacher. To bridge the sim-to-real gap, we subsequently transfer the self-play trained policies to real-world sensor data through lightweight perception adaptation. Policies trained in Gigapixel and adapted to real-world sensor data achieve competitive performance on the HUGSIM and NAVSIM-v2 benchmarks without human trajectory supervision. Moreover, scaling self-play training yields proportional gains in policy performance, establishing self-play as a practical and scalable strategy for training end-to-end models.
Human-like autonomy emerges from self-play and a pinch of human data
Jun 11, 2026Self-play reinforcement learning has recently emerged as a way to train driving policies without any human data. It uses cheap, large-scale simulations to substitute expensive, large-scale human driving demonstrations. A key limitation of this approach is that policies trained through pure self-play can learn effective but alien driving conventions incompatible with people. Previous works attempt to mitigate such behavioral misalignments through extensive reward engineering and domain randomization, which are brittle and labor-intensive. Instead of completely discarding human demonstrations, our method treats them as a regularization objective on top of a minimal safe goal-reaching reward. Like the spice in a good stew, we find that a little human data goes a long way: our method uses only 30 minutes of human demonstrations, 2500x fewer than comparable imitation learning approaches. Resulting policies coordinate with held-out human trajectories and complete training in 15 hours on a single consumer-grade GPU. Videos and full source code are available at https://spiced-self-play.com/.
Beyond Self-Play and Scale: A Behavior Benchmark for Generalization in Autonomous Driving
May 11, 2026Recent Autonomous Driving (AD) works such as GigaFlow and PufferDrive have unlocked Reinforcement Learning (RL) at scale as a training strategy for driving policies. Yet such policies remain disconnected from established benchmarks, leaving the performance of large-scale RL for driving on standardized evaluations unknown. We present BehaviorBench -- a comprehensive test suite that closes this gap along three axes: Evaluation, Complexity, and Behavior Diversity. In terms of Evaluation, we provide an interface connecting PufferDrive to nuPlan, which, for the first time, enables policies trained via RL at scale to be evaluated on an established planning benchmark for autonomous driving. Complementarily, we offer an evaluation framework that allows planners to be benchmarked directly inside the PufferDrive simulation, at a fraction of the time. Regarding Complexity, we observe that today's standardized benchmarks are so simple that near-perfect scores are achievable by straight lane following with collision checking. We extract a meaningful, interaction-rich split from the Waymo Open Motion Dataset (WOMD) on which strong performance is impossible without multi-agent reasoning. Lastly, we address Behavior Diversity. Existing benchmarks commonly evaluate planners against a single rule-based traffic model, the Intelligent Driver Model (IDM). We provide a diverse suite of interactive traffic agents to stress-test policies under heterogeneous behaviors, beyond just using IDM. Overall, our benchmarking analysis uncovers the following insight: despite learning interactive behaviors in an emergent manner, policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors. Building on this observation, we propose a hybrid planner that combines a PPO policy with a rule-based planner.
Artificial Intelligence for Modeling and Simulation of Mixed Automated and Human Traffic
Apr 14, 2026Autonomous vehicles (AVs) are now operating on public roads, which makes their testing and validation more critical than ever. Simulation offers a safe and controlled environment for evaluating AV performance in varied conditions. However, existing simulation tools mainly focus on graphical realism and rely on simple rule-based models and therefore fail to accurately represent the complexity of driving behaviors and interactions. Artificial intelligence (AI) has shown strong potential to address these limitations; however, despite the rapid progress across AI methodologies, a comprehensive survey of their application to mixed autonomy traffic simulation remains lacking. Existing surveys either focus on simulation tools without examining the AI methods behind them, or cover ego-centric decision-making without addressing the broader challenge of modeling surrounding traffic. Moreover, they do not offer a unified taxonomy of AI methods covering individual behavior modeling to full scene simulation. To address these gaps, this survey provides a structured review and synthesis of AI methods for modeling AV and human driving behavior in mixed autonomy traffic simulation. We introduce a taxonomy that organizes methods into three families: agent-level behavior models, environment-level simulation methods, and cognitive and physics-informed methods. The survey analyzes how existing simulation platforms fall short of the needs of mixed autonomy research and outlines directions to narrow this gap. It also provides a chronological overview of AI methods and reviews evaluation protocols and metrics, simulation tools, and datasets. By covering both traffic engineering and computer science perspectives, we aim to bridge the gap between these two communities.
Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
Nov 10, 2025Few classical games have been regarded as such significant benchmarks of artificial intelligence as to have justified training costs in the millions of dollars. Among these, Stratego -- a board wargame exemplifying the challenge of strategic decision making under massive amounts of hidden information -- stands apart as a case where such efforts failed to produce performance at the level of top humans. This work establishes a step change in both performance and cost for Stratego, showing that it is now possible not only to reach the level of top humans, but to achieve vastly superhuman level -- and that doing so requires not an industrial budget, but merely a few thousand dollars. We achieved this result by developing general approaches for self-play reinforcement learning and test-time search under imperfect information.
Estimating cognitive biases with attention-aware inverse planning
Oct 29, 2025



People's goal-directed behaviors are influenced by their cognitive biases, and autonomous systems that interact with people should be aware of this. For example, people's attention to objects in their environment will be biased in a way that systematically affects how they perform everyday tasks such as driving to work. Here, building on recent work in computational cognitive science, we formally articulate the attention-aware inverse planning problem, in which the goal is to estimate a person's attentional biases from their actions. We demonstrate how attention-aware inverse planning systematically differs from standard inverse reinforcement learning and how cognitive biases can be inferred from behavior. Finally, we present an approach to attention-aware inverse planning that combines deep reinforcement learning with computational cognitive modeling. We use this approach to infer the attentional strategies of RL agents in real-life driving scenarios selected from the Waymo Open Dataset, demonstrating the scalability of estimating cognitive biases with attention-aware inverse planning.
Video Game Level Design as a Multi-Agent Reinforcement Learning Problem
Oct 06, 2025Procedural Content Generation via Reinforcement Learning (PCGRL) offers a method for training controllable level designer agents without the need for human datasets, using metrics that serve as proxies for level quality as rewards. Existing PCGRL research focuses on single generator agents, but are bottlenecked by the need to frequently recalculate heuristics of level quality and the agent's need to navigate around potentially large maps. By framing level generation as a multi-agent problem, we mitigate the efficiency bottleneck of single-agent PCGRL by reducing the number of reward calculations relative to the number of agent actions. We also find that multi-agent level generators are better able to generalize to out-of-distribution map shapes, which we argue is due to the generators' learning more local, modular design policies. We conclude that treating content generation as a distributed, multi-agent task is beneficial for generating functional artifacts at scale.
Building reliable sim driving agents by scaling self-play
Feb 20, 2025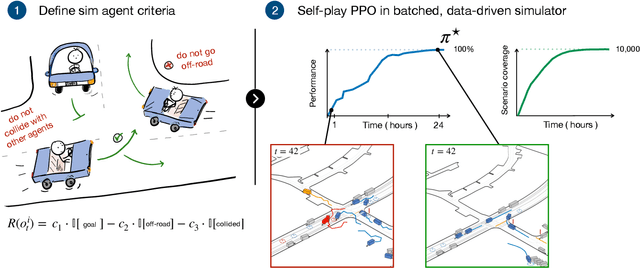

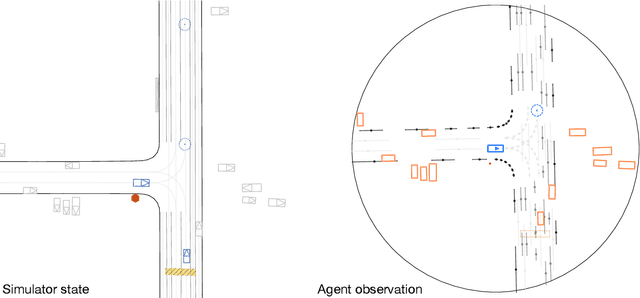

Simulation agents are essential for designing and testing systems that interact with humans, such as autonomous vehicles (AVs). These agents serve various purposes, from benchmarking AV performance to stress-testing the system's limits, but all use cases share a key requirement: reliability. A simulation agent should behave as intended by the designer, minimizing unintended actions like collisions that can compromise the signal-to-noise ratio of analyses. As a foundation for reliable sim agents, we propose scaling self-play to thousands of scenarios on the Waymo Open Motion Dataset under semi-realistic limits on human perception and control. Training from scratch on a single GPU, our agents nearly solve the full training set within a day. They generalize effectively to unseen test scenes, achieving a 99.8% goal completion rate with less than 0.8% combined collision and off-road incidents across 10,000 held-out scenarios. Beyond in-distribution generalization, our agents show partial robustness to out-of-distribution scenes and can be fine-tuned in minutes to reach near-perfect performance in those cases. Demonstrations of agent behaviors can be found at this link. We open-source both the pre-trained agents and the complete code base. Demonstrations of agent behaviors can be found at \url{https://sites.google.com/view/reliable-sim-agents}.
Reevaluating Policy Gradient Methods for Imperfect-Information Games
Feb 13, 2025In the past decade, motivated by the putative failure of naive self-play deep reinforcement learning (DRL) in adversarial imperfect-information games, researchers have developed numerous DRL algorithms based on fictitious play (FP), double oracle (DO), and counterfactual regret minimization (CFR). In light of recent results of the magnetic mirror descent algorithm, we hypothesize that simpler generic policy gradient methods like PPO are competitive with or superior to these FP, DO, and CFR-based DRL approaches. To facilitate the resolution of this hypothesis, we implement and release the first broadly accessible exact exploitability computations for four large games. Using these games, we conduct the largest-ever exploitability comparison of DRL algorithms for imperfect-information games. Over 5600 training runs, FP, DO, and CFR-based approaches fail to outperform generic policy gradient methods. Code is available at https://github.com/nathanlct/IIG-RL-Benchmark and https://github.com/gabrfarina/exp-a-spiel .