 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Rewards via LLM-Generated Progress Functions
Oct 11, 2024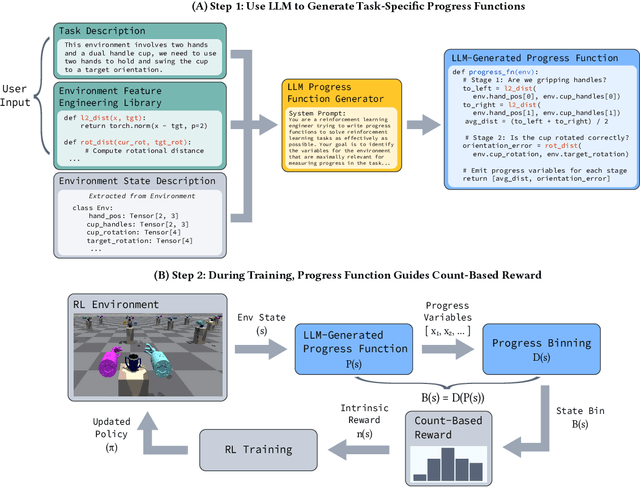
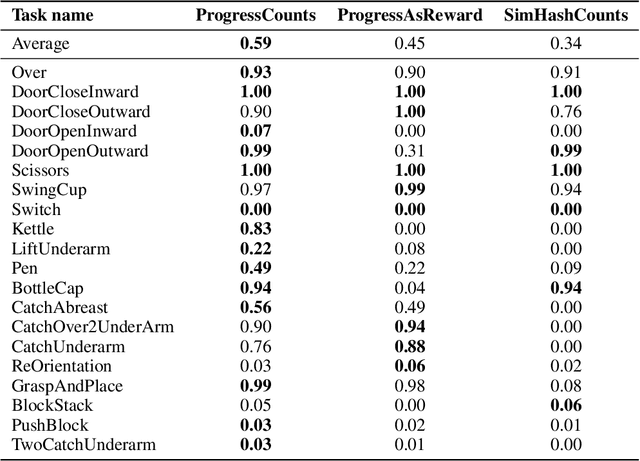
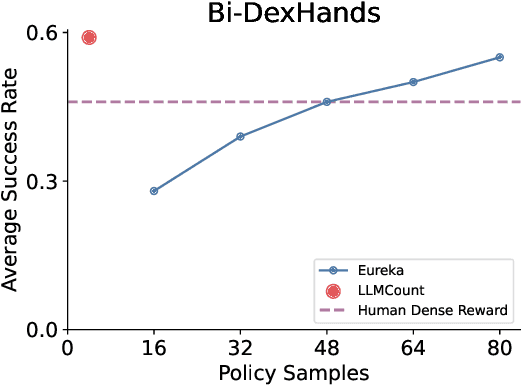

Large Language Models (LLMs) have the potential to automate reward engineering by leveraging their broad domain knowledge across various tasks. However, they often need many iterations of trial-and-error to generate effective reward functions. This process is costly because evaluating every sampled reward function requires completing the full policy optimization process for each function. In this paper, we introduce an LLM-driven reward generation framework that is able to produce state-of-the-art policies on the challenging Bi-DexHands benchmark \textbf{with 20$\times$ fewer reward function samples} than the prior state-of-the-art work. Our key insight is that we reduce the problem of generating task-specific rewards to the problem of coarsely estimating \emph{task progress}. Our two-step solution leverages the task domain knowledge and the code synthesis abilities of LLMs to author \emph{progress functions} that estimate task progress from a given state. Then, we use this notion of progress to discretize states, and generate count-based intrinsic rewards using the low-dimensional state space. We show that the combination of LLM-generated progress functions and count-based intrinsic rewards is essential for our performance gains, while alternatives such as generic hash-based counts or using progress directly as a reward function fall short.
Learning to Move Like Professional Counter-Strike Players
Aug 25, 2024
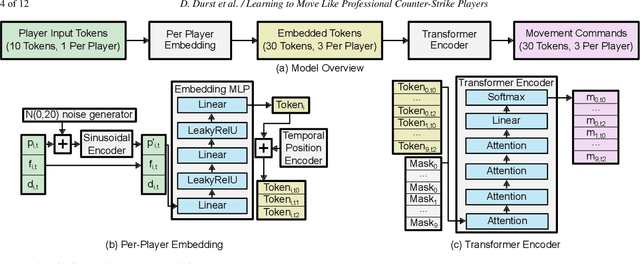
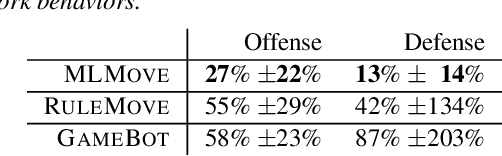
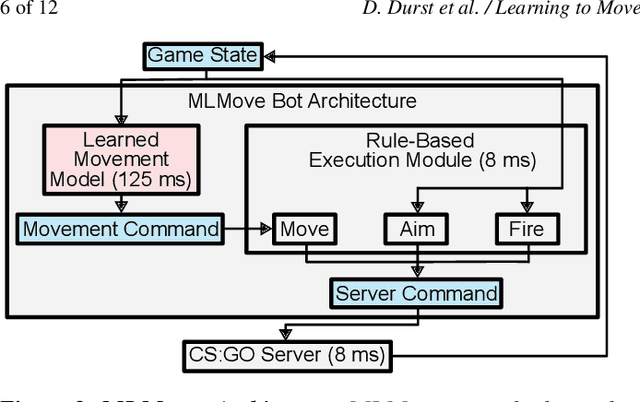
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS
Aug 02, 2024

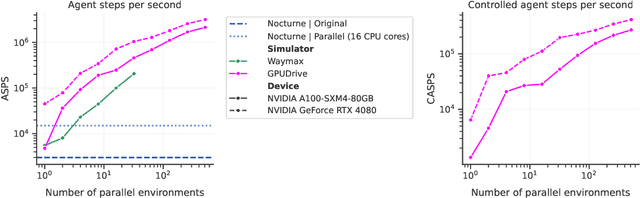

Multi-agent learning algorithms have been successful at generating superhuman planning in a wide variety of games but have had little impact on the design of deployed multi-agent planners. A key bottleneck in applying these techniques to multi-agent planning is that they require billions of steps of experience. To enable the study of multi-agent planning at this scale, we present GPUDrive, a GPU-accelerated, multi-agent simulator built on top of the Madrona Game Engine that can generate over a million steps of experience per second. Observation, reward, and dynamics functions are written directly in C++, allowing users to define complex, heterogeneous agent behaviors that are lowered to high-performance CUDA. We show that using GPUDrive we are able to effectively train reinforcement learning agents over many scenes in the Waymo Motion dataset, yielding highly effective goal-reaching agents in minutes for individual scenes and generally capable agents in a few hours. We ship these trained agents as part of the code base at https://github.com/Emerge-Lab/gpudrive.
Habitat Synthetic Scenes Dataset (HSSD-200): An Analysis of 3D Scene Scale and Realism Tradeoffs for ObjectGoal Navigation
Jun 21, 2023We contribute the Habitat Synthetic Scene Dataset, a dataset of 211 high-quality 3D scenes, and use it to test navigation agent generalization to realistic 3D environments. Our dataset represents real interiors and contains a diverse set of 18,656 models of real-world objects. We investigate the impact of synthetic 3D scene dataset scale and realism on the task of training embodied agents to find and navigate to objects (ObjectGoal navigation). By comparing to synthetic 3D scene datasets from prior work, we find that scale helps in generalization, but the benefits quickly saturate, making visual fidelity and correlation to real-world scenes more important. Our experiments show that agents trained on our smaller-scale dataset can match or outperform agents trained on much larger datasets. Surprisingly, we observe that agents trained on just 122 scenes from our dataset outperform agents trained on 10,000 scenes from the ProcTHOR-10K dataset in terms of zero-shot generalization in real-world scanned environments.
Megaverse: Simulating Embodied Agents at One Million Experiences per Second
Jul 21, 2021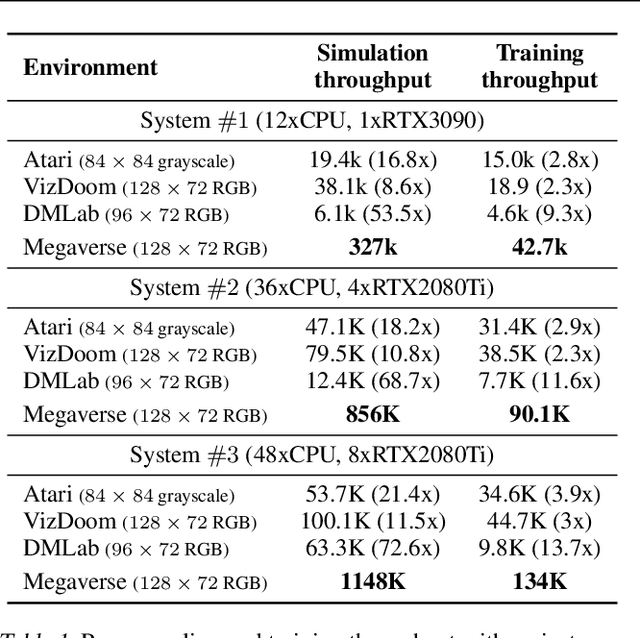
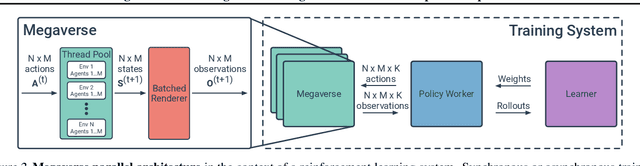
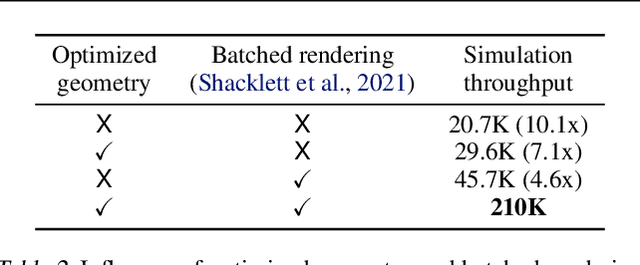
We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research. The source code is available at https://www.megaverse.info
Large Batch Simulation for Deep Reinforcement Learning
Mar 12, 2021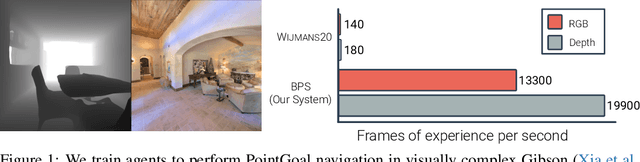
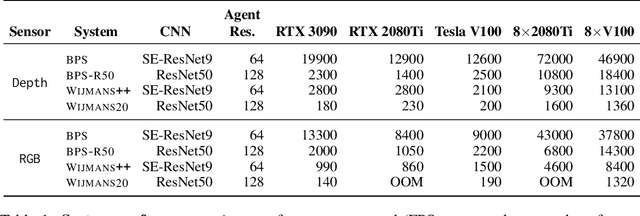
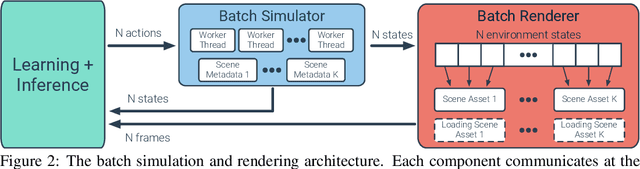
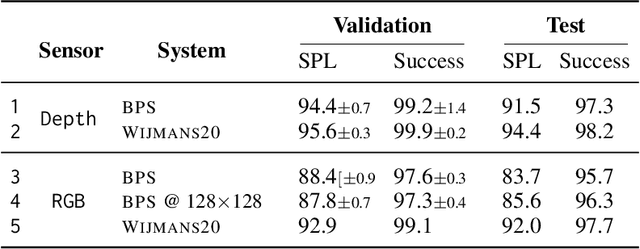
We accelerate deep reinforcement learning-based training in visually complex 3D environments by two orders of magnitude over prior work, realizing end-to-end training speeds of over 19,000 frames of experience per second on a single GPU and up to 72,000 frames per second on a single eight-GPU machine. The key idea of our approach is to design a 3D renderer and embodied navigation simulator around the principle of "batch simulation": accepting and executing large batches of requests simultaneously. Beyond exposing large amounts of work at once, batch simulation allows implementations to amortize in-memory storage of scene assets, rendering work, data loading, and synchronization costs across many simulation requests, dramatically improving the number of simulated agents per GPU and overall simulation throughput. To balance DNN inference and training costs with faster simulation, we also build a computationally efficient policy DNN that maintains high task performance, and modify training algorithms to maintain sample efficiency when training with large mini-batches. By combining batch simulation and DNN performance optimizations, we demonstrate that PointGoal navigation agents can be trained in complex 3D environments on a single GPU in 1.5 days to 97% of the accuracy of agents trained on a prior state-of-the-art system using a 64-GPU cluster over three days. We provide open-source reference implementations of our batch 3D renderer and simulator to facilitate incorporation of these ideas into RL systems.