 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025



The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Imitation Learning via Focused Satisficing
May 20, 2025

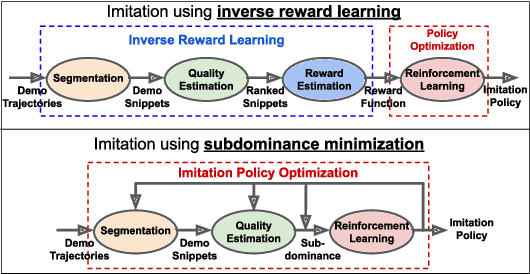

Imitation learning often assumes that demonstrations are close to optimal according to some fixed, but unknown, cost function. However, according to satisficing theory, humans often choose acceptable behavior based on their personal (and potentially dynamic) levels of aspiration, rather than achieving (near-) optimality. For example, a lunar lander demonstration that successfully lands without crashing might be acceptable to a novice despite being slow or jerky. Using a margin-based objective to guide deep reinforcement learning, our focused satisficing approach to imitation learning seeks a policy that surpasses the demonstrator's aspiration levels -- defined over trajectories or portions of trajectories -- on unseen demonstrations without explicitly learning those aspirations. We show experimentally that this focuses the policy to imitate the highest quality (portions of) demonstrations better than existing imitation learning methods, providing much higher rates of guaranteed acceptability to the demonstrator, and competitive true returns on a range of environments.
X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real
May 15, 2025Human videos offer a scalable way to train robot manipulation policies, but lack the action labels needed by standard imitation learning algorithms. Existing cross-embodiment approaches try to map human motion to robot actions, but often fail when the embodiments differ significantly. We propose X-Sim, a real-to-sim-to-real framework that uses object motion as a dense and transferable signal for learning robot policies. X-Sim starts by reconstructing a photorealistic simulation from an RGBD human video and tracking object trajectories to define object-centric rewards. These rewards are used to train a reinforcement learning (RL) policy in simulation. The learned policy is then distilled into an image-conditioned diffusion policy using synthetic rollouts rendered with varied viewpoints and lighting. To transfer to the real world, X-Sim introduces an online domain adaptation technique that aligns real and simulated observations during deployment. Importantly, X-Sim does not require any robot teleoperation data. We evaluate it across 5 manipulation tasks in 2 environments and show that it: (1) improves task progress by 30% on average over hand-tracking and sim-to-real baselines, (2) matches behavior cloning with 10x less data collection time, and (3) generalizes to new camera viewpoints and test-time changes. Code and videos are available at https://portal-cornell.github.io/X-Sim/.
Distilling Realizable Students from Unrealizable Teachers
May 14, 2025We study policy distillation under privileged information, where a student policy with only partial observations must learn from a teacher with full-state access. A key challenge is information asymmetry: the student cannot directly access the teacher's state space, leading to distributional shifts and policy degradation. Existing approaches either modify the teacher to produce realizable but sub-optimal demonstrations or rely on the student to explore missing information independently, both of which are inefficient. Our key insight is that the student should strategically interact with the teacher --querying only when necessary and resetting from recovery states --to stay on a recoverable path within its own observation space. We introduce two methods: (i) an imitation learning approach that adaptively determines when the student should query the teacher for corrections, and (ii) a reinforcement learning approach that selects where to initialize training for efficient exploration. We validate our methods in both simulated and real-world robotic tasks, demonstrating significant improvements over standard teacher-student baselines in training efficiency and final performance. The project website is available at : https://portal-cornell.github.io/CritiQ_ReTRy/
Efficient Imitation Under Misspecification
Mar 17, 2025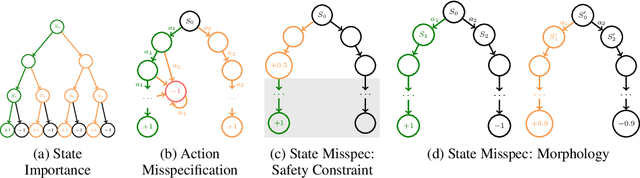
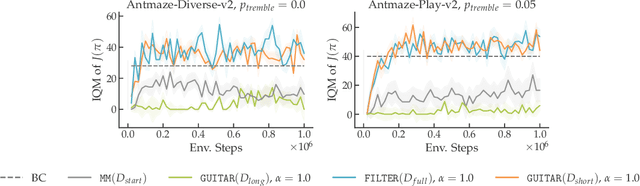

Interactive imitation learning (IL) is a powerful paradigm for learning to make sequences of decisions from an expert demonstrating how to perform a task. Prior work in efficient imitation learning has focused on the realizable setting, where the expert's policy lies within the learner's policy class (i.e. the learner can perfectly imitate the expert in all states). However, in practice, perfect imitation of the expert is often impossible due to differences in state information and action space expressiveness (e.g. morphological differences between robots and humans.) In this paper, we consider the more general misspecified setting, where no assumptions are made about the expert policy's realizability. We introduce a novel structural condition, reward-agnostic policy completeness, and prove that it is sufficient for interactive IL algorithms to efficiently avoid the quadratically compounding errors that stymie offline approaches like behavioral cloning. We address an additional practical constraint-the case of limited expert data-and propose a principled method for using additional offline data to further improve the sample-efficiency of interactive IL algorithms. Finally, we empirically investigate the optimal reset distribution in efficient IL under misspecification with a suite of continuous control tasks.
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning
Mar 03, 2025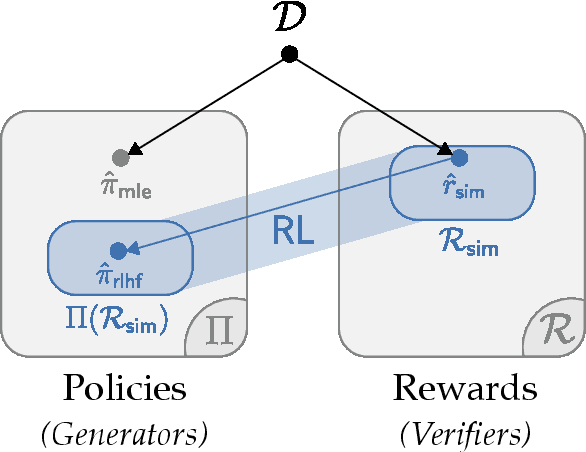

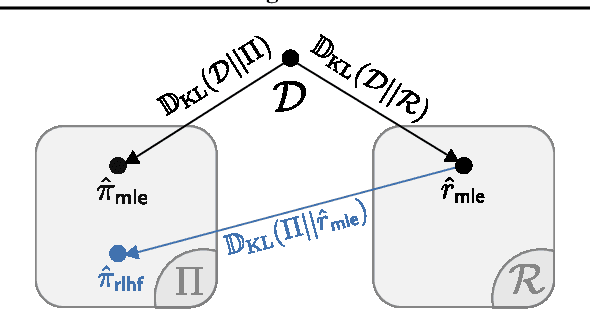

From a first-principles perspective, it may seem odd that the strongest results in foundation model fine-tuning (FT) are achieved via a relatively complex, two-stage training procedure. Specifically, one first trains a reward model (RM) on some dataset (e.g. human preferences) before using it to provide online feedback as part of a downstream reinforcement learning (RL) procedure, rather than directly optimizing the policy parameters on the dataset via offline maximum likelihood estimation. In fact, from an information-theoretic perspective, we can only lose information via passing through a reward model and cannot create any new information via on-policy sampling. To explain this discrepancy, we scrutinize several hypotheses on the value of RL in FT through both theoretical and empirical lenses. Of the hypotheses considered, we find the most support for the explanation that on problems with a generation-verification gap, the combination of the ease of learning the relatively simple RM (verifier) from the preference data, coupled with the ability of the downstream RL procedure to then filter its search space to the subset of policies (generators) that are optimal for relatively simple verifiers is what leads to the superior performance of online FT.
Multi-Turn Code Generation Through Single-Step Rewards
Feb 27, 2025We address the problem of code generation from multi-turn execution feedback. Existing methods either generate code without feedback or use complex, hierarchical reinforcement learning to optimize multi-turn rewards. We propose a simple yet scalable approach, $\mu$Code, that solves multi-turn code generation using only single-step rewards. Our key insight is that code generation is a one-step recoverable MDP, where the correct code can be recovered from any intermediate code state in a single turn. $\mu$Code iteratively trains both a generator to provide code solutions conditioned on multi-turn execution feedback and a verifier to score the newly generated code. Experimental evaluations show that our approach achieves significant improvements over the state-of-the-art baselines. We provide analysis of the design choices of the reward models and policy, and show the efficacy of $\mu$Code at utilizing the execution feedback. Our code is available at https://github.com/portal-cornell/muCode.
Imitation Learning from a Single Temporally Misaligned Video
Feb 08, 2025



We examine the problem of learning sequential tasks from a single visual demonstration. A key challenge arises when demonstrations are temporally misaligned due to variations in timing, differences in embodiment, or inconsistencies in execution. Existing approaches treat imitation as a distribution-matching problem, aligning individual frames between the agent and the demonstration. However, we show that such frame-level matching fails to enforce temporal ordering or ensure consistent progress. Our key insight is that matching should instead be defined at the level of sequences. We propose that perfect matching occurs when one sequence successfully covers all the subgoals in the same order as the other sequence. We present ORCA (ORdered Coverage Alignment), a dense per-timestep reward function that measures the probability of the agent covering demonstration frames in the correct order. On temporally misaligned demonstrations, we show that agents trained with the ORCA reward achieve $4.5$x improvement ($0.11 \rightarrow 0.50$ average normalized returns) for Meta-world tasks and $6.6$x improvement ($6.55 \rightarrow 43.3$ average returns) for Humanoid-v4 tasks compared to the best frame-level matching algorithms. We also provide empirical analysis showing that ORCA is robust to varying levels of temporal misalignment. Our code is available at https://github.com/portal-cornell/orca/
Robotouille: An Asynchronous Planning Benchmark for LLM Agents
Feb 06, 2025Effective asynchronous planning, or the ability to efficiently reason and plan over states and actions that must happen in parallel or sequentially, is essential for agents that must account for time delays, reason over diverse long-horizon tasks, and collaborate with other agents. While large language model (LLM) agents show promise in high-level task planning, current benchmarks focus primarily on short-horizon tasks and do not evaluate such asynchronous planning capabilities. We introduce Robotouille, a challenging benchmark environment designed to test LLM agents' ability to handle long-horizon asynchronous scenarios. Our synchronous and asynchronous datasets capture increasingly complex planning challenges that go beyond existing benchmarks, requiring agents to manage overlapping tasks and interruptions. Our results show that ReAct (gpt4-o) achieves 47% on synchronous tasks but only 11% on asynchronous tasks, highlighting significant room for improvement. We further analyze failure modes, demonstrating the need for LLM agents to better incorporate long-horizon feedback and self-audit their reasoning during task execution. Code is available at https://github.com/portal-cornell/robotouille.
Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning
Jan 13, 2025



Teaching robots to autonomously complete everyday tasks remains a challenge. Imitation Learning (IL) is a powerful approach that imbues robots with skills via demonstrations, but is limited by the labor-intensive process of collecting teleoperated robot data. Human videos offer a scalable alternative, but it remains difficult to directly train IL policies from them due to the lack of robot action labels. To address this, we propose to represent actions as short-horizon 2D trajectories on an image. These actions, or motion tracks, capture the predicted direction of motion for either human hands or robot end-effectors. We instantiate an IL policy called Motion Track Policy (MT-pi) which receives image observations and outputs motion tracks as actions. By leveraging this unified, cross-embodiment action space, MT-pi completes tasks with high success given just minutes of human video and limited additional robot demonstrations. At test time, we predict motion tracks from two camera views, recovering 6DoF trajectories via multi-view synthesis. MT-pi achieves an average success rate of 86.5% across 4 real-world tasks, outperforming state-of-the-art IL baselines which do not leverage human data or our action space by 40%, and generalizes to scenarios seen only in human videos. Code and videos are available on our website https://portal-cornell.github.io/motion_track_policy/.