 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning
Jan 13, 2025



Teaching robots to autonomously complete everyday tasks remains a challenge. Imitation Learning (IL) is a powerful approach that imbues robots with skills via demonstrations, but is limited by the labor-intensive process of collecting teleoperated robot data. Human videos offer a scalable alternative, but it remains difficult to directly train IL policies from them due to the lack of robot action labels. To address this, we propose to represent actions as short-horizon 2D trajectories on an image. These actions, or motion tracks, capture the predicted direction of motion for either human hands or robot end-effectors. We instantiate an IL policy called Motion Track Policy (MT-pi) which receives image observations and outputs motion tracks as actions. By leveraging this unified, cross-embodiment action space, MT-pi completes tasks with high success given just minutes of human video and limited additional robot demonstrations. At test time, we predict motion tracks from two camera views, recovering 6DoF trajectories via multi-view synthesis. MT-pi achieves an average success rate of 86.5% across 4 real-world tasks, outperforming state-of-the-art IL baselines which do not leverage human data or our action space by 40%, and generalizes to scenarios seen only in human videos. Code and videos are available on our website https://portal-cornell.github.io/motion_track_policy/.
What's the Move? Hybrid Imitation Learning via Salient Points
Dec 06, 2024



While imitation learning (IL) offers a promising framework for teaching robots various behaviors, learning complex tasks remains challenging. Existing IL policies struggle to generalize effectively across visual and spatial variations even for simple tasks. In this work, we introduce SPHINX: Salient Point-based Hybrid ImitatioN and eXecution, a flexible IL policy that leverages multimodal observations (point clouds and wrist images), along with a hybrid action space of low-frequency, sparse waypoints and high-frequency, dense end effector movements. Given 3D point cloud observations, SPHINX learns to infer task-relevant points within a point cloud, or salient points, which support spatial generalization by focusing on semantically meaningful features. These salient points serve as anchor points to predict waypoints for long-range movement, such as reaching target poses in free-space. Once near a salient point, SPHINX learns to switch to predicting dense end-effector movements given close-up wrist images for precise phases of a task. By exploiting the strengths of different input modalities and action representations for different manipulation phases, SPHINX tackles complex tasks in a sample-efficient, generalizable manner. Our method achieves 86.7% success across 4 real-world and 2 simulated tasks, outperforming the next best state-of-the-art IL baseline by 41.1% on average across 440 real world trials. SPHINX additionally generalizes to novel viewpoints, visual distractors, spatial arrangements, and execution speeds with a 1.7x speedup over the most competitive baseline. Our website (http://sphinx-manip.github.io) provides open-sourced code for data collection, training, and evaluation, along with supplementary videos.
FLAIR: Feeding via Long-horizon AcquIsition of Realistic dishes
Jul 10, 2024



Robot-assisted feeding has the potential to improve the quality of life for individuals with mobility limitations who are unable to feed themselves independently. However, there exists a large gap between the homogeneous, curated plates existing feeding systems can handle, and truly in-the-wild meals. Feeding realistic plates is immensely challenging due to the sheer range of food items that a robot may encounter, each requiring specialized manipulation strategies which must be sequenced over a long horizon to feed an entire meal. An assistive feeding system should not only be able to sequence different strategies efficiently in order to feed an entire meal, but also be mindful of user preferences given the personalized nature of the task. We address this with FLAIR, a system for long-horizon feeding which leverages the commonsense and few-shot reasoning capabilities of foundation models, along with a library of parameterized skills, to plan and execute user-preferred and efficient bite sequences. In real-world evaluations across 6 realistic plates, we find that FLAIR can effectively tap into a varied library of skills for efficient food pickup, while adhering to the diverse preferences of 42 participants without mobility limitations as evaluated in a user study. We demonstrate the seamless integration of FLAIR with existing bite transfer methods [19, 28], and deploy it across 2 institutions and 3 robots, illustrating its adaptability. Finally, we illustrate the real-world efficacy of our system by successfully feeding a care recipient with severe mobility limitations. Supplementary materials and videos can be found at: https://emprise.cs.cornell.edu/flair .
Learning Correspondence for Deformable Objects
May 14, 2024
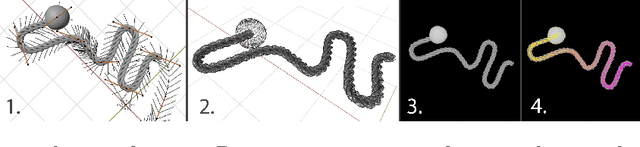


We investigate the problem of pixelwise correspondence for deformable objects, namely cloth and rope, by comparing both classical and learning-based methods. We choose cloth and rope because they are traditionally some of the most difficult deformable objects to analytically model with their large configuration space, and they are meaningful in the context of robotic tasks like cloth folding, rope knot-tying, T-shirt folding, curtain closing, etc. The correspondence problem is heavily motivated in robotics, with wide-ranging applications including semantic grasping, object tracking, and manipulation policies built on top of correspondences. We present an exhaustive survey of existing classical methods for doing correspondence via feature-matching, including SIFT, SURF, and ORB, and two recently published learning-based methods including TimeCycle and Dense Object Nets. We make three main contributions: (1) a framework for simulating and rendering synthetic images of deformable objects, with qualitative results demonstrating transfer between our simulated and real domains (2) a new learning-based correspondence method extending Dense Object Nets, and (3) a standardized comparison across state-of-the-art correspondence methods. Our proposed method provides a flexible, general formulation for learning temporally and spatially continuous correspondences for nonrigid (and rigid) objects. We report root mean squared error statistics for all methods and find that Dense Object Nets outperforms baseline classical methods for correspondence, and our proposed extension of Dense Object Nets performs similarly.
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024



Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
Nov 06, 2023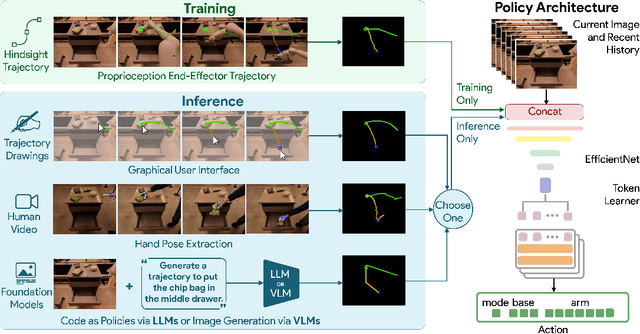
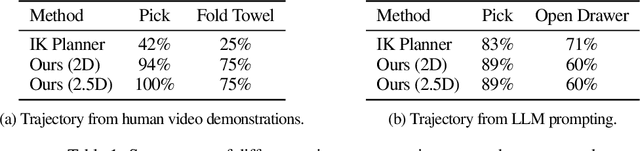
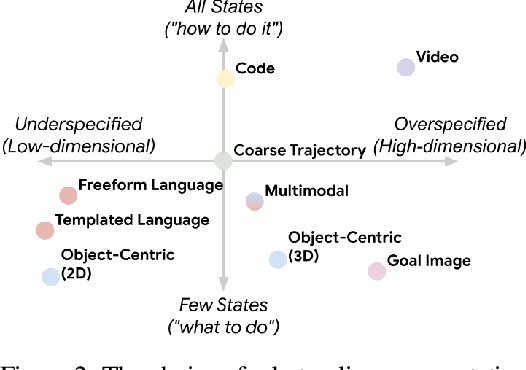

Generalization remains one of the most important desiderata for robust robot learning systems. While recently proposed approaches show promise in generalization to novel objects, semantic concepts, or visual distribution shifts, generalization to new tasks remains challenging. For example, a language-conditioned policy trained on pick-and-place tasks will not be able to generalize to a folding task, even if the arm trajectory of folding is similar to pick-and-place. Our key insight is that this kind of generalization becomes feasible if we represent the task through rough trajectory sketches. We propose a policy conditioning method using such rough trajectory sketches, which we call RT-Trajectory, that is practical, easy to specify, and allows the policy to effectively perform new tasks that would otherwise be challenging to perform. We find that trajectory sketches strike a balance between being detailed enough to express low-level motion-centric guidance while being coarse enough to allow the learned policy to interpret the trajectory sketch in the context of situational visual observations. In addition, we show how trajectory sketches can provide a useful interface to communicate with robotic policies: they can be specified through simple human inputs like drawings or videos, or through automated methods such as modern image-generating or waypoint-generating methods. We evaluate RT-Trajectory at scale on a variety of real-world robotic tasks, and find that RT-Trajectory is able to perform a wider range of tasks compared to language-conditioned and goal-conditioned policies, when provided the same training data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Learning Sequential Acquisition Policies for Robot-Assisted Feeding
Sep 11, 2023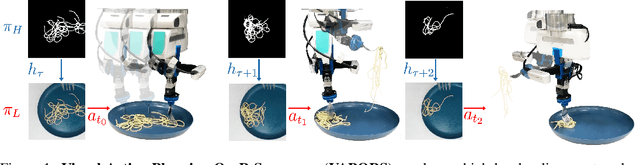
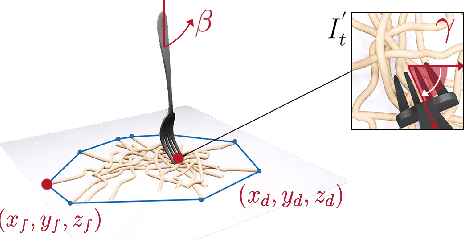
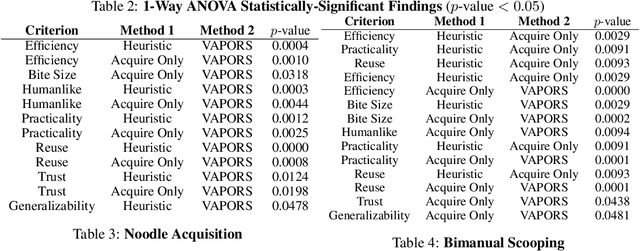
A robot providing mealtime assistance must perform specialized maneuvers with various utensils in order to pick up and feed a range of food items. Beyond these dexterous low-level skills, an assistive robot must also plan these strategies in sequence over a long horizon to clear a plate and complete a meal. Previous methods in robot-assisted feeding introduce highly specialized primitives for food handling without a means to compose them together. Meanwhile, existing approaches to long-horizon manipulation lack the flexibility to embed highly specialized primitives into their frameworks. We propose Visual Action Planning OveR Sequences (VAPORS), a framework for long-horizon food acquisition. VAPORS learns a policy for high-level action selection by leveraging learned latent plate dynamics in simulation. To carry out sequential plans in the real world, VAPORS delegates action execution to visually parameterized primitives. We validate our approach on complex real-world acquisition trials involving noodle acquisition and bimanual scooping of jelly beans. Across 38 plates, VAPORS acquires much more efficiently than baselines, generalizes across realistic plate variations such as toppings and sauces, and qualitatively appeals to user feeding preferences in a survey conducted across 49 individuals. Code, datasets, videos, and supplementary materials can be found on our website: https://sites.google.com/view/vaporsbot.
KITE: Keypoint-Conditioned Policies for Semantic Manipulation
Jul 06, 2023



While natural language offers a convenient shared interface for humans and robots, enabling robots to interpret and follow language commands remains a longstanding challenge in manipulation. A crucial step to realizing a performant instruction-following robot is achieving semantic manipulation, where a robot interprets language at different specificities, from high-level instructions like "Pick up the stuffed animal" to more detailed inputs like "Grab the left ear of the elephant." To tackle this, we propose Keypoints + Instructions to Execution (KITE), a two-step framework for semantic manipulation which attends to both scene semantics (distinguishing between different objects in a visual scene) and object semantics (precisely localizing different parts within an object instance). KITE first grounds an input instruction in a visual scene through 2D image keypoints, providing a highly accurate object-centric bias for downstream action inference. Provided an RGB-D scene observation, KITE then executes a learned keypoint-conditioned skill to carry out the instruction. The combined precision of keypoints and parameterized skills enables fine-grained manipulation with generalization to scene and object variations. Empirically, we demonstrate KITE in 3 real-world environments: long-horizon 6-DoF tabletop manipulation, semantic grasping, and a high-precision coffee-making task. In these settings, KITE achieves a 75%, 70%, and 71% overall success rate for instruction-following, respectively. KITE outperforms frameworks that opt for pre-trained visual language models over keypoint-based grounding, or omit skills in favor of end-to-end visuomotor control, all while being trained from fewer or comparable amounts of demonstrations. Supplementary material, datasets, code, and videos can be found on our website: http://tinyurl.com/kite-site.
Learning Visuo-Haptic Skewering Strategies for Robot-Assisted Feeding
Nov 30, 2022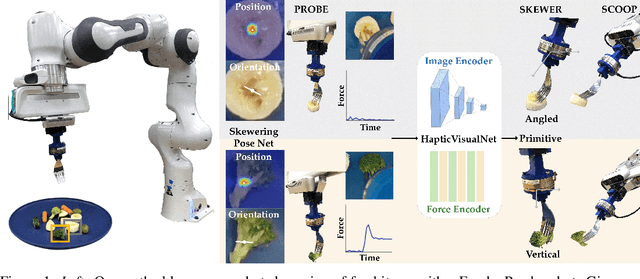

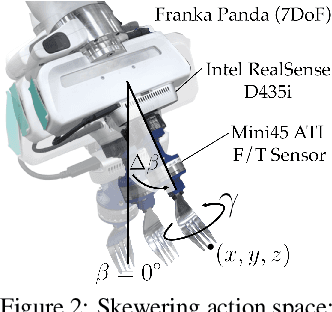

Acquiring food items with a fork poses an immense challenge to a robot-assisted feeding system, due to the wide range of material properties and visual appearances present across food groups. Deformable foods necessitate different skewering strategies than firm ones, but inferring such characteristics for several previously unseen items on a plate remains nontrivial. Our key insight is to leverage visual and haptic observations during interaction with an item to rapidly and reactively plan skewering motions. We learn a generalizable, multimodal representation for a food item from raw sensory inputs which informs the optimal skewering strategy. Given this representation, we propose a zero-shot framework to sense visuo-haptic properties of a previously unseen item and reactively skewer it, all within a single interaction. Real-robot experiments with foods of varying levels of visual and textural diversity demonstrate that our multimodal policy outperforms baselines which do not exploit both visual and haptic cues or do not reactively plan. Across 6 plates of different food items, our proposed framework achieves 71% success over 69 skewering attempts total. Supplementary material, datasets, code, and videos are available on our website: https://sites.google.com/view/hapticvisualnet-corl22/home