 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
Nov 06, 2023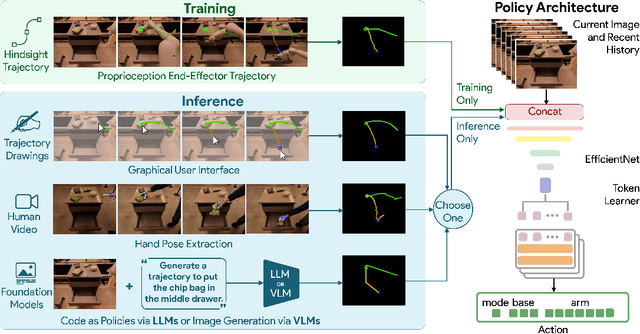
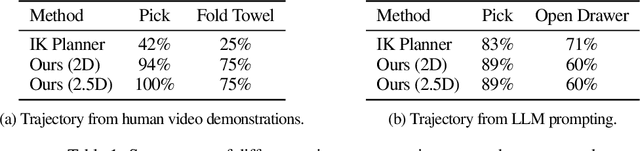
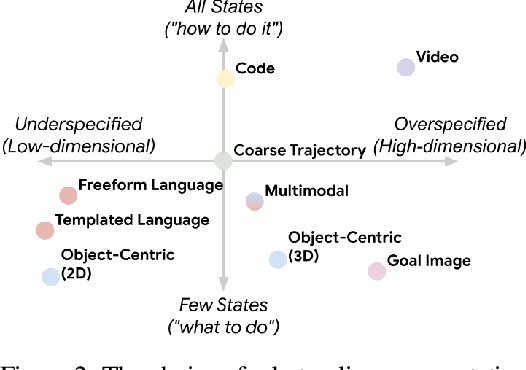

Generalization remains one of the most important desiderata for robust robot learning systems. While recently proposed approaches show promise in generalization to novel objects, semantic concepts, or visual distribution shifts, generalization to new tasks remains challenging. For example, a language-conditioned policy trained on pick-and-place tasks will not be able to generalize to a folding task, even if the arm trajectory of folding is similar to pick-and-place. Our key insight is that this kind of generalization becomes feasible if we represent the task through rough trajectory sketches. We propose a policy conditioning method using such rough trajectory sketches, which we call RT-Trajectory, that is practical, easy to specify, and allows the policy to effectively perform new tasks that would otherwise be challenging to perform. We find that trajectory sketches strike a balance between being detailed enough to express low-level motion-centric guidance while being coarse enough to allow the learned policy to interpret the trajectory sketch in the context of situational visual observations. In addition, we show how trajectory sketches can provide a useful interface to communicate with robotic policies: they can be specified through simple human inputs like drawings or videos, or through automated methods such as modern image-generating or waypoint-generating methods. We evaluate RT-Trajectory at scale on a variety of real-world robotic tasks, and find that RT-Trajectory is able to perform a wider range of tasks compared to language-conditioned and goal-conditioned policies, when provided the same training data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023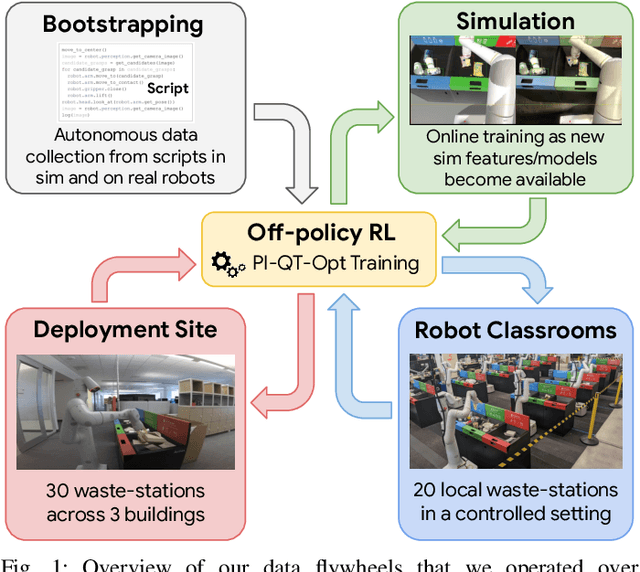


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Open-World Object Manipulation using Pre-trained Vision-Language Models
Mar 02, 2023



For robots to follow instructions from people, they must be able to connect the rich semantic information in human vocabulary, e.g. "can you get me the pink stuffed whale?" to their sensory observations and actions. This brings up a notably difficult challenge for robots: while robot learning approaches allow robots to learn many different behaviors from first-hand experience, it is impractical for robots to have first-hand experiences that span all of this semantic information. We would like a robot's policy to be able to perceive and pick up the pink stuffed whale, even if it has never seen any data interacting with a stuffed whale before. Fortunately, static data on the internet has vast semantic information, and this information is captured in pre-trained vision-language models. In this paper, we study whether we can interface robot policies with these pre-trained models, with the aim of allowing robots to complete instructions involving object categories that the robot has never seen first-hand. We develop a simple approach, which we call Manipulation of Open-World Objects (MOO), which leverages a pre-trained vision-language model to extract object-identifying information from the language command and image, and conditions the robot policy on the current image, the instruction, and the extracted object information. In a variety of experiments on a real mobile manipulator, we find that MOO generalizes zero-shot to a wide range of novel object categories and environments. In addition, we show how MOO generalizes to other, non-language-based input modalities to specify the object of interest such as finger pointing, and how it can be further extended to enable open-world navigation and manipulation. The project's website and evaluation videos can be found at https://robot-moo.github.io/
PI-QT-Opt: Predictive Information Improves Multi-Task Robotic Reinforcement Learning at Scale
Oct 15, 2022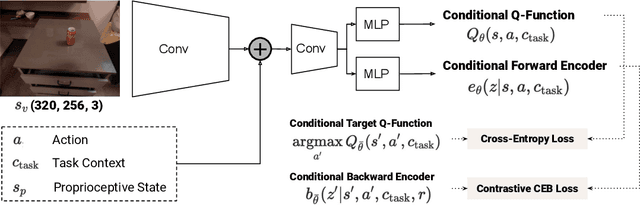



The predictive information, the mutual information between the past and future, has been shown to be a useful representation learning auxiliary loss for training reinforcement learning agents, as the ability to model what will happen next is critical to success on many control tasks. While existing studies are largely restricted to training specialist agents on single-task settings in simulation, in this work, we study modeling the predictive information for robotic agents and its importance for general-purpose agents that are trained to master a large repertoire of diverse skills from large amounts of data. Specifically, we introduce Predictive Information QT-Opt (PI-QT-Opt), a QT-Opt agent augmented with an auxiliary loss that learns representations of the predictive information to solve up to 297 vision-based robot manipulation tasks in simulation and the real world with a single set of parameters. We demonstrate that modeling the predictive information significantly improves success rates on the training tasks and leads to better zero-shot transfer to unseen novel tasks. Finally, we evaluate PI-QT-Opt on real robots, achieving substantial and consistent improvement over QT-Opt in multiple experimental settings of varying environments, skills, and multi-task configurations.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019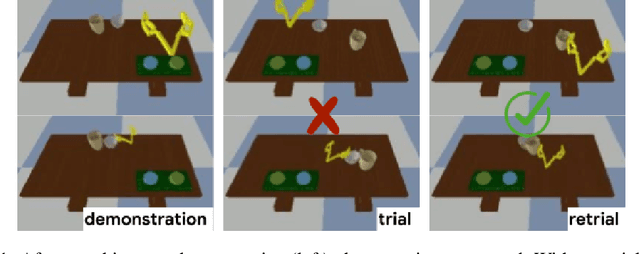
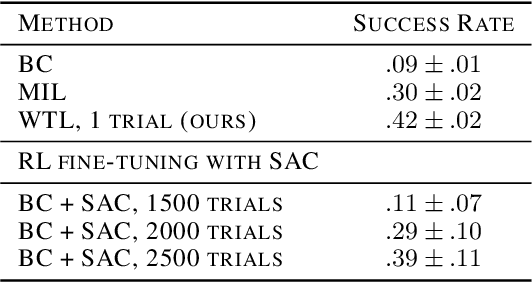
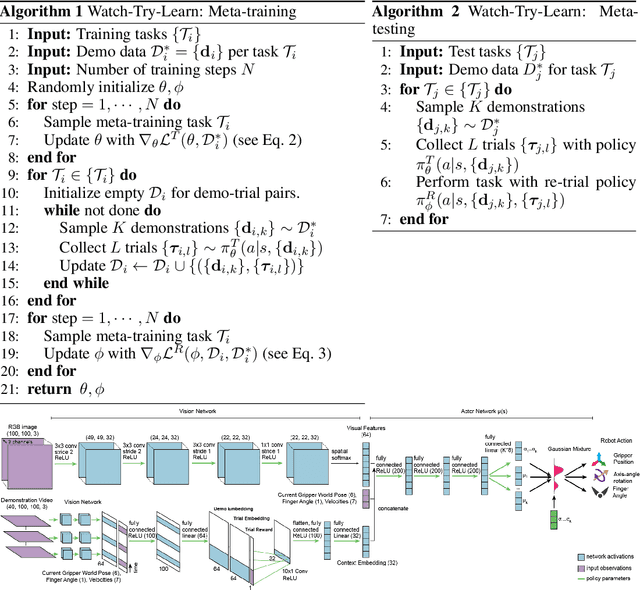
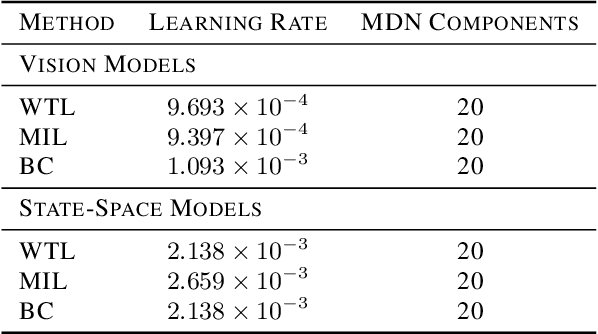
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Generalized Feedback Loop for Joint Hand-Object Pose Estimation
Mar 25, 2019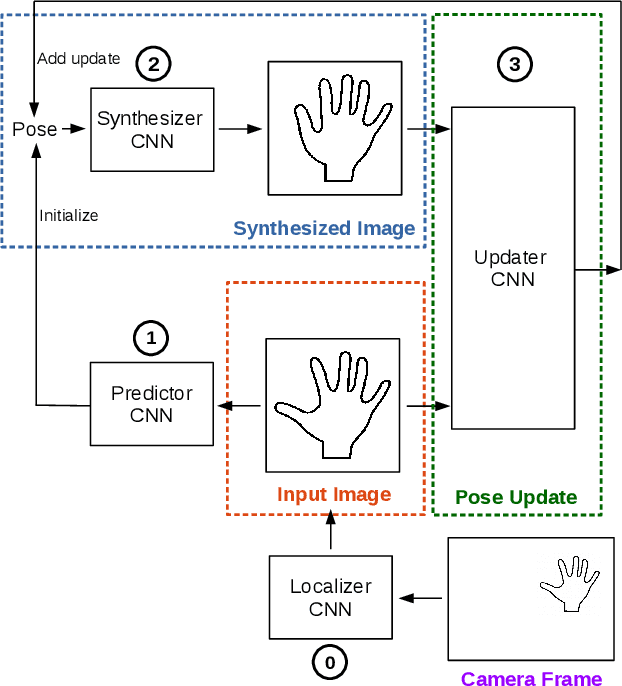
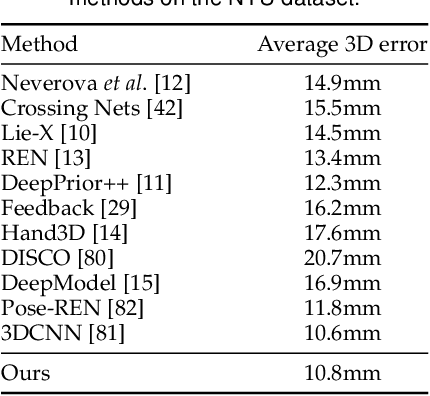
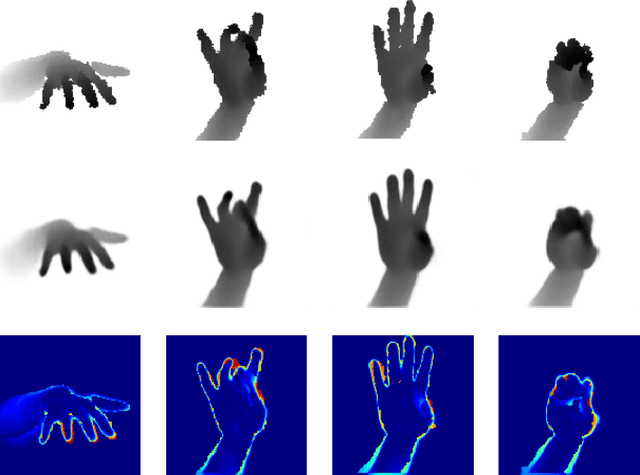
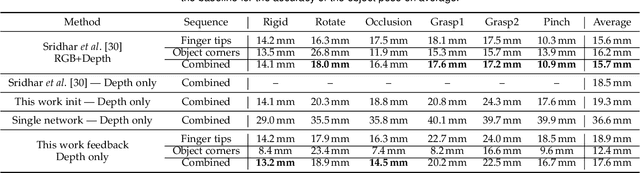
We propose an approach to estimating the 3D pose of a hand, possibly handling an object, given a depth image. We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop. The components of this feedback loop are also Deep Networks, optimized using training data. This approach can be generalized to a hand interacting with an object. Therefore, we jointly estimate the 3D pose of the hand and the 3D pose of the object. Our approach performs en-par with state-of-the-art methods for 3D hand pose estimation, and outperforms state-of-the-art methods for joint hand-object pose estimation when using depth images only. Also, our approach is efficient as our implementation runs in real-time on a single GPU.
* arXiv admin note: substantial text overlap with arXiv:1609.09698
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019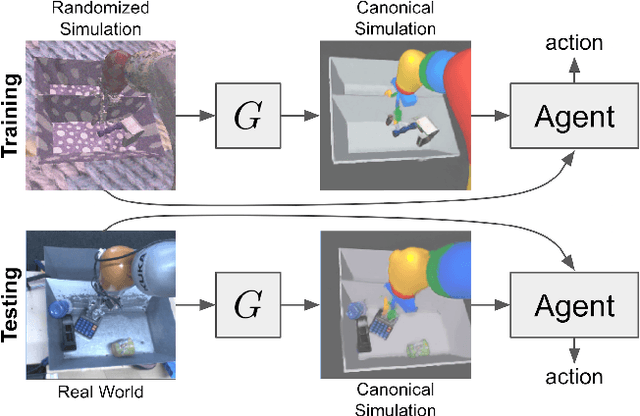
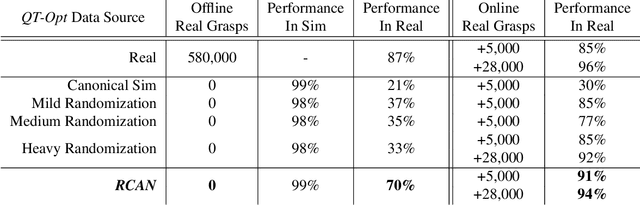


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.