 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Multi-Robot Flocking with Gesture Responsiveness and Musical Accompaniment
Mar 30, 2024For decades, robotics researchers have pursued various tasks for multi-robot systems, from cooperative manipulation to search and rescue. These tasks are multi-robot extensions of classical robotic tasks and often optimized on dimensions such as speed or efficiency. As robots transition from commercial and research settings into everyday environments, social task aims such as engagement or entertainment become increasingly relevant. This work presents a compelling multi-robot task, in which the main aim is to enthrall and interest. In this task, the goal is for a human to be drawn to move alongside and participate in a dynamic, expressive robot flock. Towards this aim, the research team created algorithms for robot movements and engaging interaction modes such as gestures and sound. The contributions are as follows: (1) a novel group navigation algorithm involving human and robot agents, (2) a gesture responsive algorithm for real-time, human-robot flocking interaction, (3) a weight mode characterization system for modifying flocking behavior, and (4) a method of encoding a choreographer's preferences inside a dynamic, adaptive, learned system. An experiment was performed to understand individual human behavior while interacting with the flock under three conditions: weight modes selected by a human choreographer, a learned model, or subset list. Results from the experiment showed that the perception of the experience was not influenced by the weight mode selection. This work elucidates how differing task aims such as engagement manifest in multi-robot system design and execution, and broadens the domain of multi-robot tasks.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023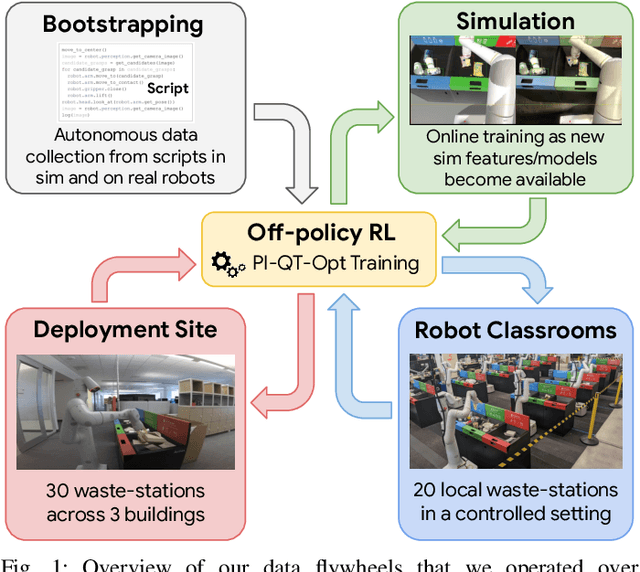

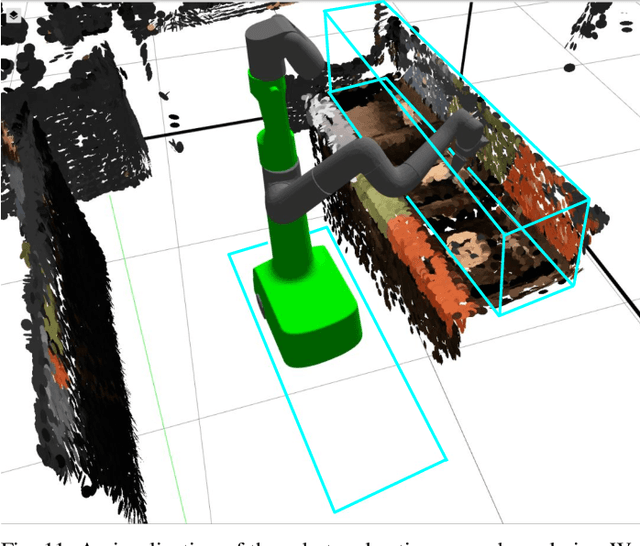

We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
PI-QT-Opt: Predictive Information Improves Multi-Task Robotic Reinforcement Learning at Scale
Oct 15, 2022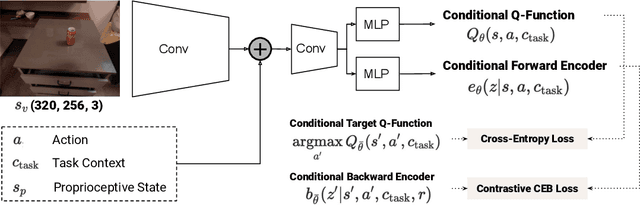



The predictive information, the mutual information between the past and future, has been shown to be a useful representation learning auxiliary loss for training reinforcement learning agents, as the ability to model what will happen next is critical to success on many control tasks. While existing studies are largely restricted to training specialist agents on single-task settings in simulation, in this work, we study modeling the predictive information for robotic agents and its importance for general-purpose agents that are trained to master a large repertoire of diverse skills from large amounts of data. Specifically, we introduce Predictive Information QT-Opt (PI-QT-Opt), a QT-Opt agent augmented with an auxiliary loss that learns representations of the predictive information to solve up to 297 vision-based robot manipulation tasks in simulation and the real world with a single set of parameters. We demonstrate that modeling the predictive information significantly improves success rates on the training tasks and leads to better zero-shot transfer to unseen novel tasks. Finally, we evaluate PI-QT-Opt on real robots, achieving substantial and consistent improvement over QT-Opt in multiple experimental settings of varying environments, skills, and multi-task configurations.
Quantile QT-Opt for Risk-Aware Vision-Based Robotic Grasping
Oct 01, 2019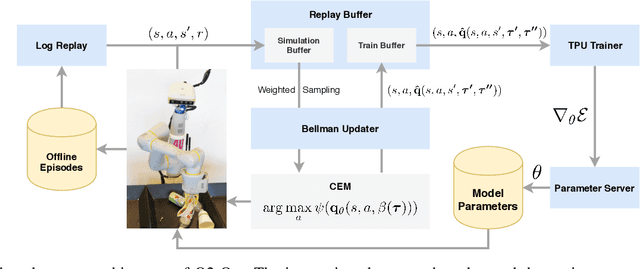
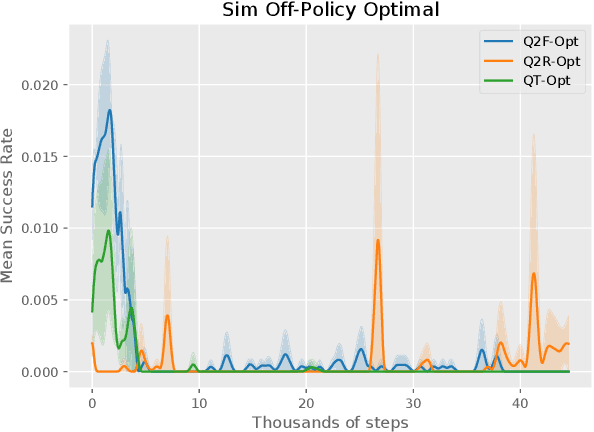
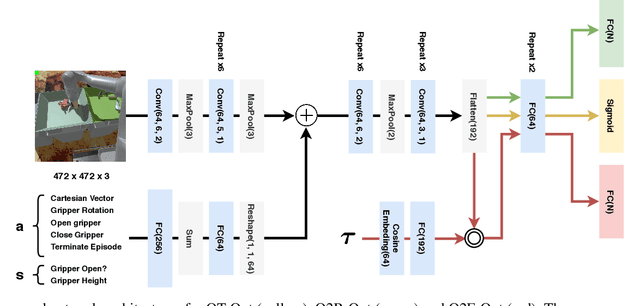
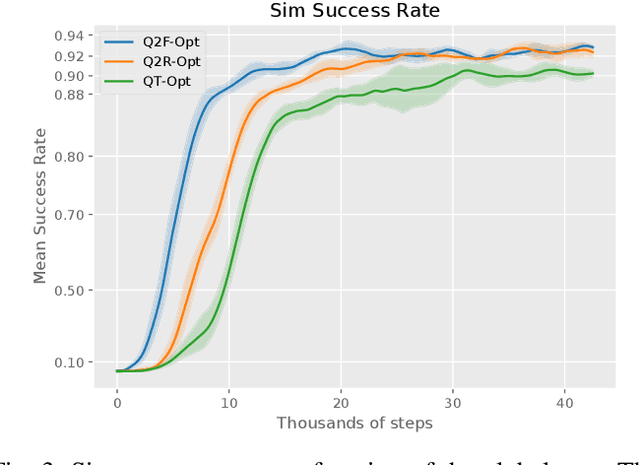
The distributional perspective on reinforcement learning (RL) has given rise to a series of successful Q-learning algorithms, resulting in state-of-the-art performance in arcade game environments. However, it has not yet been analyzed how these findings from a discrete setting translate to complex practical applications characterized by noisy, high dimensional and continuous state-action spaces. In this work, we propose Quantile QT-Opt (Q2-Opt), a distributional variant of the recently introduced distributed Q-learning algorithm for continuous domains, and examine its behaviour in a series of simulated and real vision-based robotic grasping tasks. The absence of an actor in Q2-Opt allows us to directly draw a parallel to the previous discrete experiments in the literature without the additional complexities induced by an actor-critic architecture. We demonstrate that Q2-Opt achieves a superior vision-based object grasping success rate, while also being more sample efficient. The distributional formulation also allows us to experiment with various risk-distortion metrics that give us an indication of how robots can concretely manage risk in practice using a Deep RL control policy. As an additional contribution, we perform experiments on offline datasets and compare them with the latest findings from discrete settings. Surprisingly, we find that there is a discrepancy between our results and the previous batch RL findings from the literature obtained on arcade game environments.
Learning Probabilistic Multi-Modal Actor Models for Vision-Based Robotic Grasping
Apr 15, 2019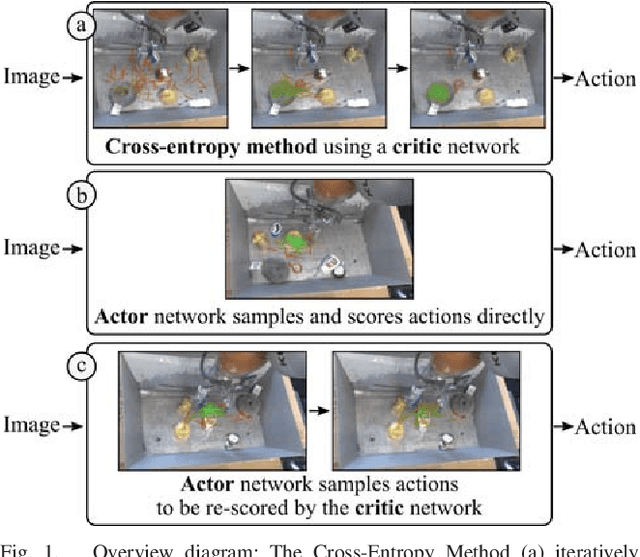
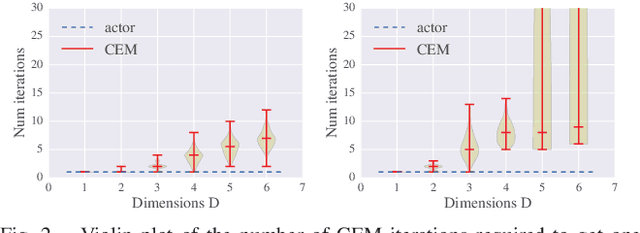
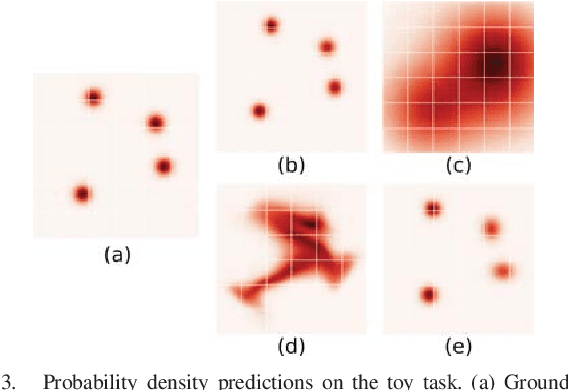

Many previous works approach vision-based robotic grasping by training a value network that evaluates grasp proposals. These approaches require an optimization process at run-time to infer the best action from the value network. As a result, the inference time grows exponentially as the dimension of action space increases. We propose an alternative method, by directly training a neural density model to approximate the conditional distribution of successful grasp poses from the input images. We construct a neural network that combines Gaussian mixture and normalizing flows, which is able to represent multi-modal, complex probability distributions. We demonstrate on both simulation and real robot that the proposed actor model achieves similar performance compared to the value network using the Cross-Entropy Method (CEM) for inference, on top-down grasping with a 4 dimensional action space. Our actor model reduces the inference time by 3 times compared to the state-of-the-art CEM method. We believe that actor models will play an important role when scaling up these approaches to higher dimensional action spaces.
Path Integral Guided Policy Search
Oct 11, 2018
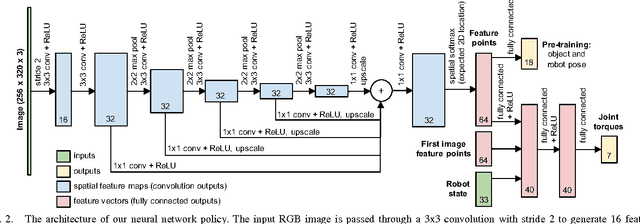

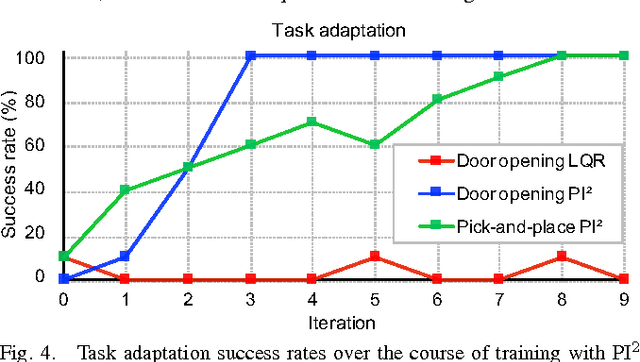
We present a policy search method for learning complex feedback control policies that map from high-dimensional sensory inputs to motor torques, for manipulation tasks with discontinuous contact dynamics. We build on a prior technique called guided policy search (GPS), which iteratively optimizes a set of local policies for specific instances of a task, and uses these to train a complex, high-dimensional global policy that generalizes across task instances. We extend GPS in the following ways: (1) we propose the use of a model-free local optimizer based on path integral stochastic optimal control (PI2), which enables us to learn local policies for tasks with highly discontinuous contact dynamics; and (2) we enable GPS to train on a new set of task instances in every iteration by using on-policy sampling: this increases the diversity of the instances that the policy is trained on, and is crucial for achieving good generalization. We show that these contributions enable us to learn deep neural network policies that can directly perform torque control from visual input. We validate the method on a challenging door opening task and a pick-and-place task, and we demonstrate that our approach substantially outperforms the prior LQR-based local policy optimizer on these tasks. Furthermore, we show that on-policy sampling significantly increases the generalization ability of these policies.
Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
Oct 03, 2016
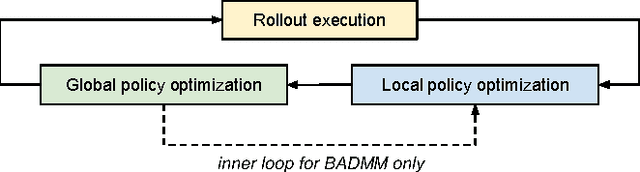
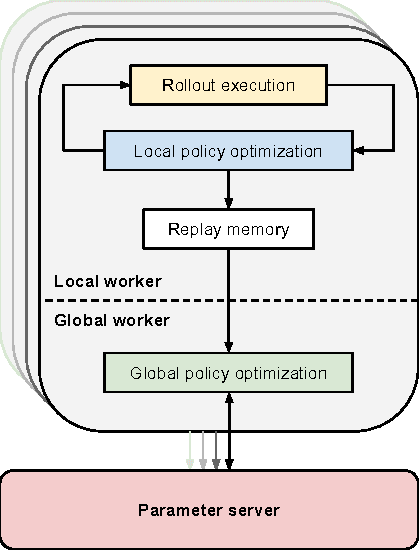
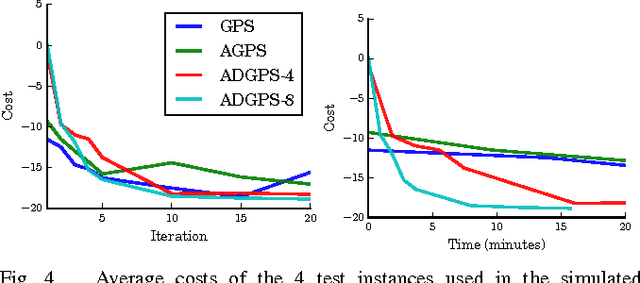
In principle, reinforcement learning and policy search methods can enable robots to learn highly complex and general skills that may allow them to function amid the complexity and diversity of the real world. However, training a policy that generalizes well across a wide range of real-world conditions requires far greater quantity and diversity of experience than is practical to collect with a single robot. Fortunately, it is possible for multiple robots to share their experience with one another, and thereby, learn a policy collectively. In this work, we explore distributed and asynchronous policy learning as a means to achieve generalization and improved training times on challenging, real-world manipulation tasks. We propose a distributed and asynchronous version of Guided Policy Search and use it to demonstrate collective policy learning on a vision-based door opening task using four robots. We show that it achieves better generalization, utilization, and training times than the single robot alternative.