 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023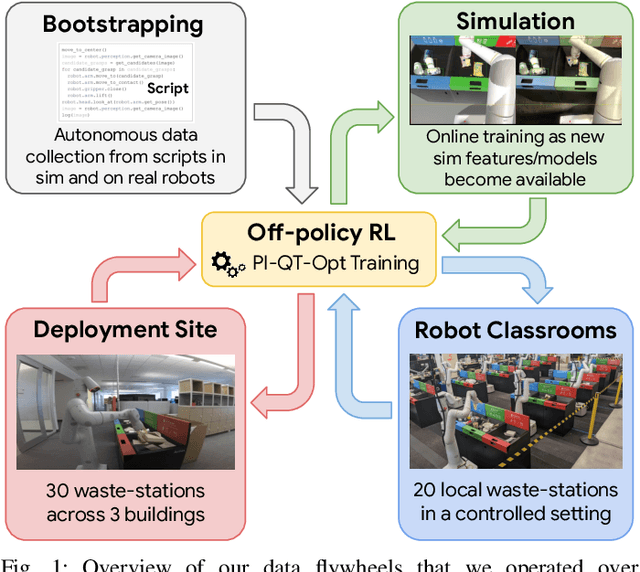

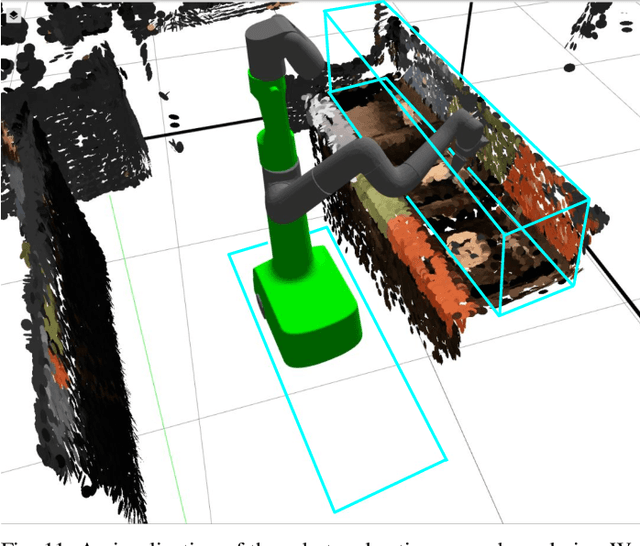

We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Jump-Start Reinforcement Learning
Apr 05, 2022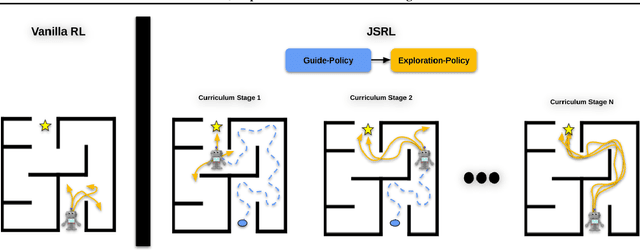
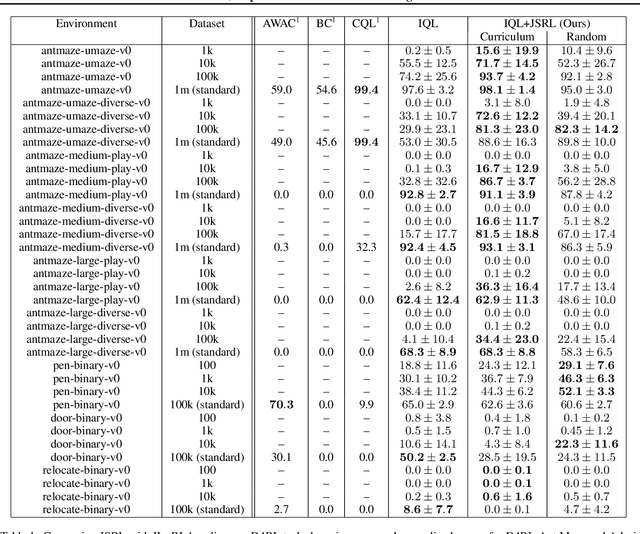
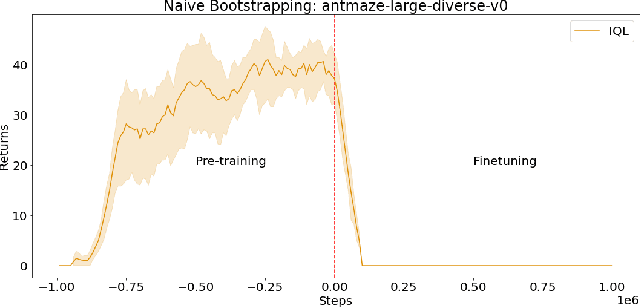
Reinforcement learning (RL) provides a theoretical framework for continuously improving an agent's behavior via trial and error. However, efficiently learning policies from scratch can be very difficult, particularly for tasks with exploration challenges. In such settings, it might be desirable to initialize RL with an existing policy, offline data, or demonstrations. However, naively performing such initialization in RL often works poorly, especially for value-based methods. In this paper, we present a meta algorithm that can use offline data, demonstrations, or a pre-existing policy to initialize an RL policy, and is compatible with any RL approach. In particular, we propose Jump-Start Reinforcement Learning (JSRL), an algorithm that employs two policies to solve tasks: a guide-policy, and an exploration-policy. By using the guide-policy to form a curriculum of starting states for the exploration-policy, we are able to efficiently improve performance on a set of simulated robotic tasks. We show via experiments that JSRL is able to significantly outperform existing imitation and reinforcement learning algorithms, particularly in the small-data regime. In addition, we provide an upper bound on the sample complexity of JSRL and show that with the help of a guide-policy, one can improve the sample complexity for non-optimism exploration methods from exponential in horizon to polynomial.
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022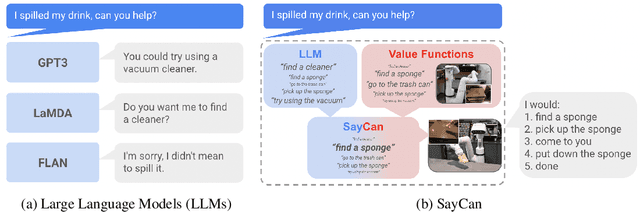
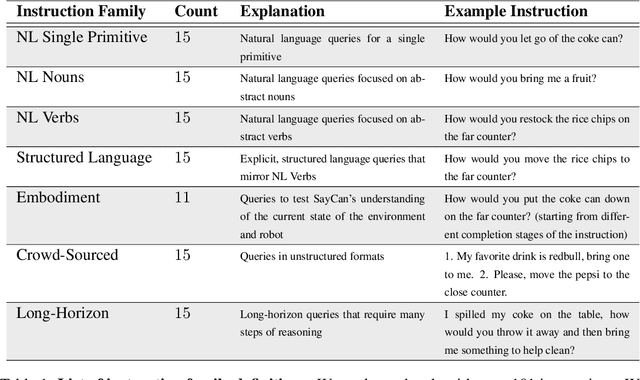
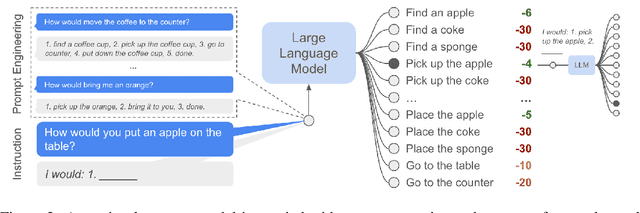
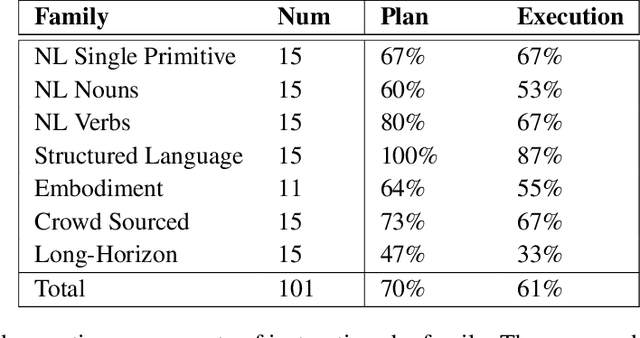
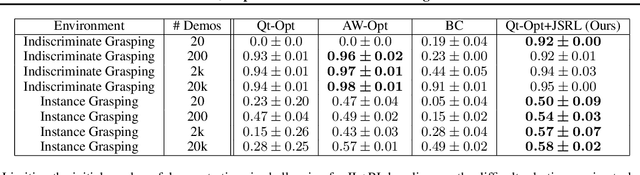
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021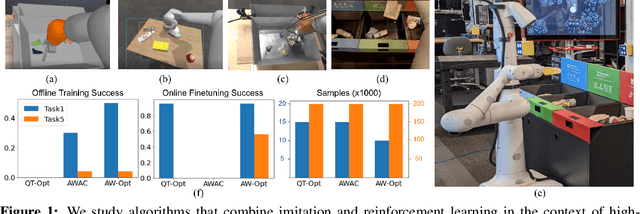
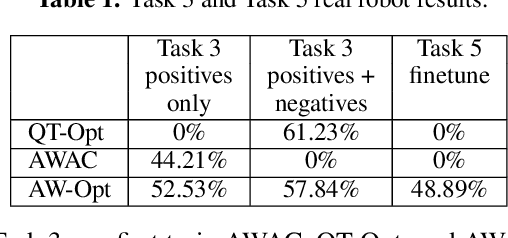
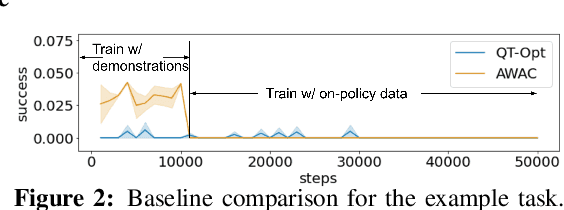
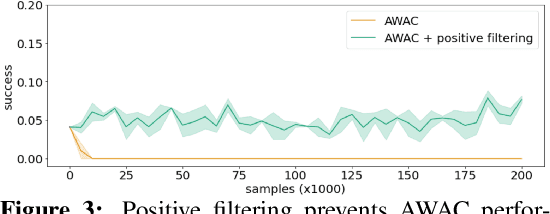
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
GRAC: Self-Guided and Self-Regularized Actor-Critic
Sep 18, 2020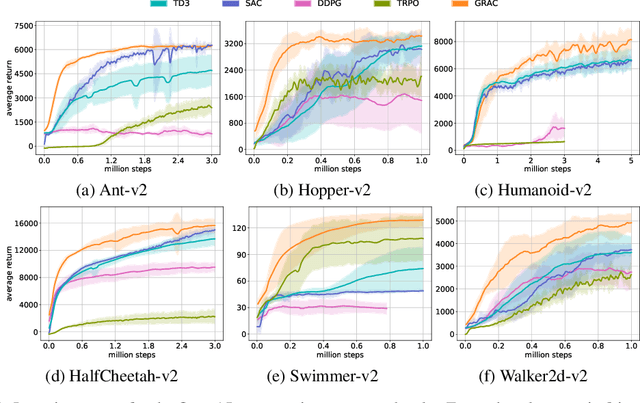
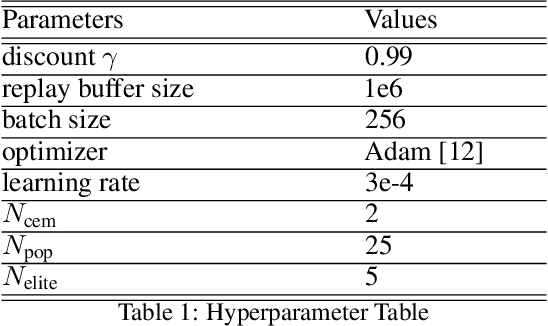
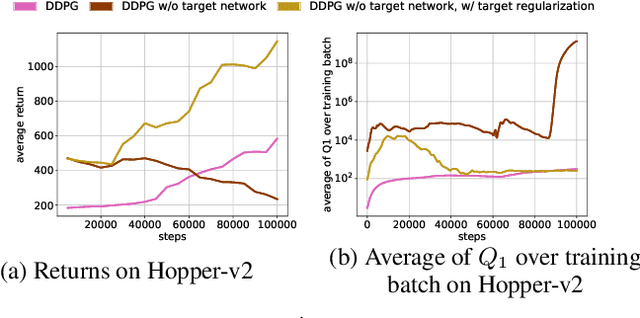
Deep reinforcement learning (DRL) algorithms have successfully been demonstrated on a range of challenging decision making and control tasks. One dominant component of recent deep reinforcement learning algorithms is the target network which mitigates the divergence when learning the Q function. However, target networks can slow down the learning process due to delayed function updates. Another dominant component especially in continuous domains is the policy gradient method which models and optimizes the policy directly. However, when Q functions are approximated with neural networks, their landscapes can be complex and therefore mislead the local gradient. In this work, we propose a self-regularized and self-guided actor-critic method. We introduce a self-regularization term within the TD-error minimization and remove the need for the target network. In addition, we propose a self-guided policy improvement method by combining policy-gradient with zero-order optimization such as the Cross Entropy Method. It helps to search for actions associated with higher Q-values in a broad neighborhood and is robust to local noise in the Q function approximation. These actions help to guide the updates of our actor network. We evaluate our method on the suite of OpenAI gym tasks, achieving or outperforming state of the art in every environment tested.
Learning Topological Motion Primitives for Knot Planning
Sep 05, 2020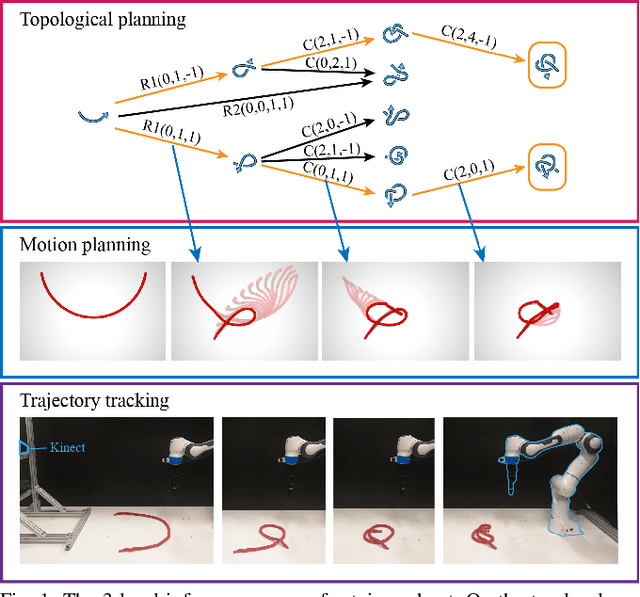
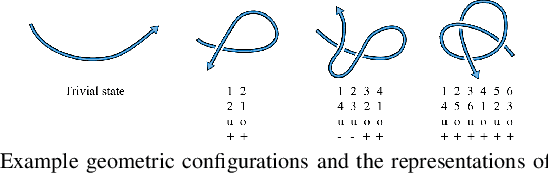
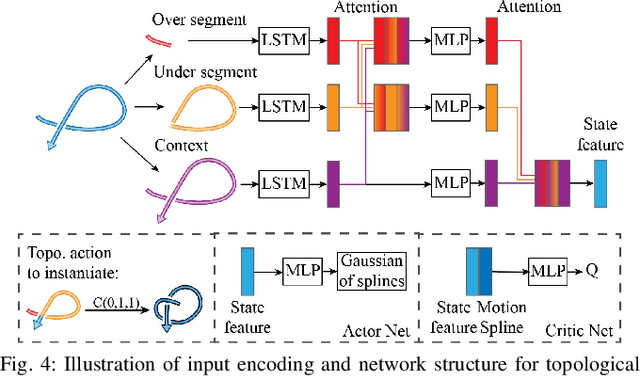
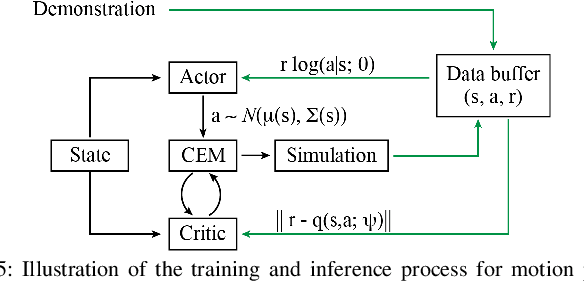
In this paper, we approach the challenging problem of motion planning for knot tying. We propose a hierarchical approach in which the top layer produces a topological plan and the bottom layer translates this plan into continuous robot motion. The top layer decomposes a knotting task into sequences of abstract topological actions based on knot theory. The bottom layer translates each of these abstract actions into robot motion trajectories through learned topological motion primitives. To adapt each topological action to the specific rope geometry, the motion primitives take the observed rope configuration as input. We train the motion primitives by imitating human demonstrations and reinforcement learning in simulation. To generalize human demonstrations of simple knots into more complex knots, we observe similarities in the motion strategies of different topological actions and design the neural network structure to exploit such similarities. We demonstrate that our learned motion primitives can be used to efficiently generate motion plans for tying the overhand knot. The motion plan can then be executed on a real robot using visual tracking and Model Predictive Control. We also demonstrate that our learned motion primitives can be composed to tie a more complex pentagram-like knot despite being only trained on human demonstrations of simpler knots.
How to Close Sim-Real Gap? Transfer with Segmentation!
May 14, 2020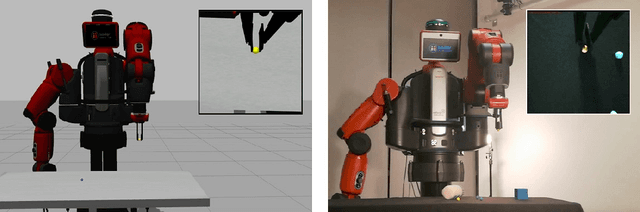
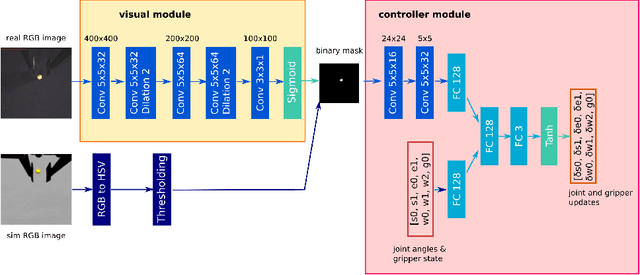
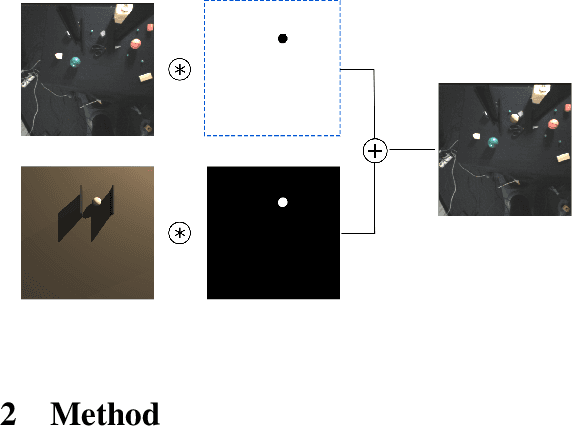
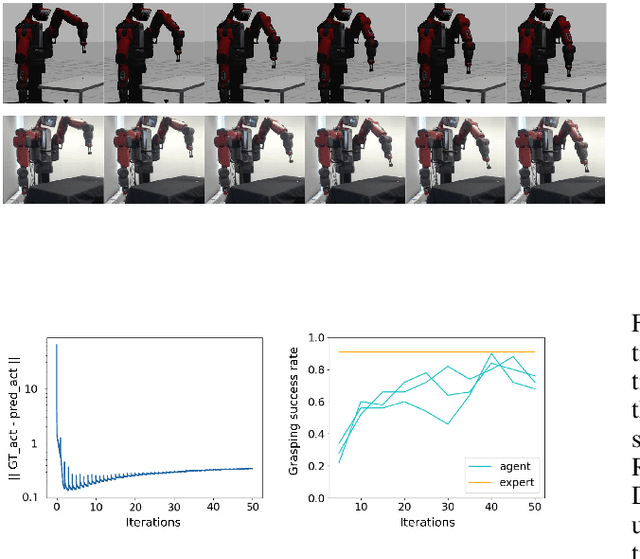
One fundamental difficulty in robotic learning is the sim-real gap problem. In this work, we propose to use segmentation as the interface between perception and control, as a domain-invariant state representation. We identify two sources of sim-real gap, one is dynamics sim-real gap, the other is visual sim-real gap. To close dynamics sim-real gap, we propose to use closed-loop control. For complex task with segmentation mask input, we further propose to learn a closed-loop model-free control policy with deep neural network using imitation learning. To close visual sim-real gap, we propose to learn a perception model in real environment using simulated target plus real background image, without using any real world supervision. We demonstrate this methodology in eye-in-hand grasping task. We train a closed-loop control policy model that taking the segmentation as input using simulation. We show that this control policy is able to transfer from simulation to real environment. The closed-loop control policy is not only robust with respect to discrepancies between the dynamic model of the simulated and real robot, but also is able to generalize to unseen scenarios where the target is moving and even learns to recover from failures. We train the perception segmentation model using training data generated by composing real background images with simulated images of the target. Combining the control policy learned from simulation with the perception model, we achieve an impressive $\bf{88\%}$ success rate in grasping a tiny sphere with a real robot.
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Nov 14, 2019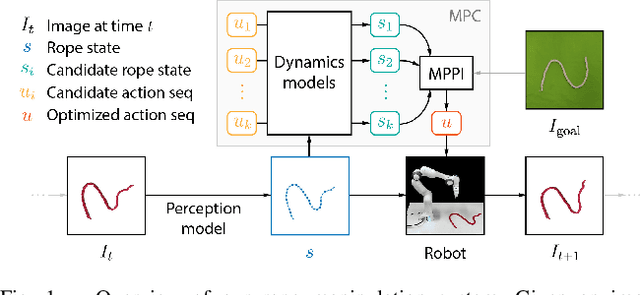
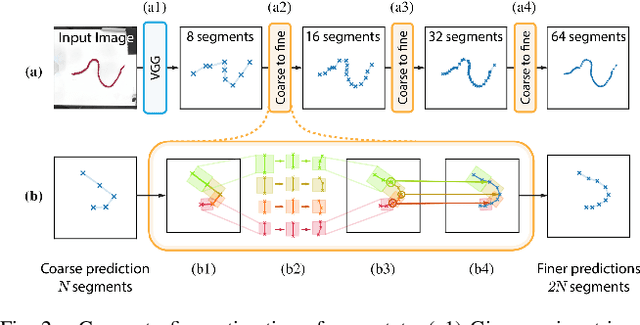
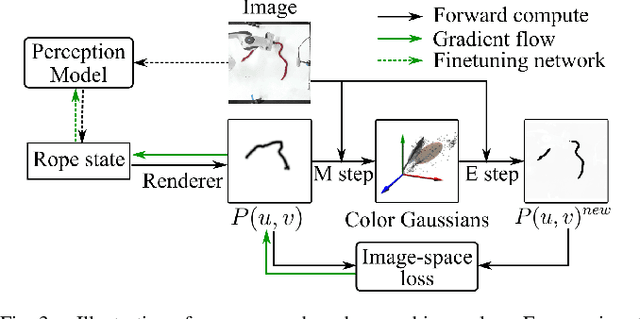
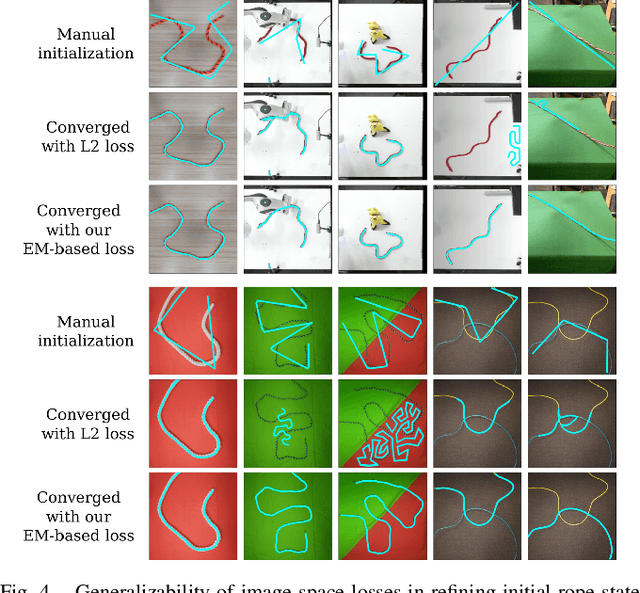
We demonstrate model-based, visual robot manipulation of linear deformable objects. Our approach is based on a state-space representation of the physical system that the robot aims to control. This choice has multiple advantages, including the ease of incorporating physical priors in the dynamics model and perception model, and the ease of planning manipulation actions. In addition, physical states can naturally represent object instances of different appearances. Therefore, dynamics in the state space can be learned in one setting and directly used in other visually different settings. This is in contrast to dynamics learned in pixel space or latent space, where generalization to visual differences are not guaranteed. Challenges in taking the state-space approach are the estimation of the high-dimensional state of a deformable object from raw images, where annotations are very expensive on real data, and finding a dynamics model that is both accurate, generalizable, and efficient to compute. We are the first to demonstrate self-supervised training of rope state estimation on real images, without requiring expensive annotations. This is achieved by our novel differentiable renderer and image loss, which are generalizable across a wide range of visual appearances. With estimated rope states, we train a fast and differentiable neural network dynamics model that encodes the physics of mass-spring systems. Our method has a higher accuracy in predicting future states compared to models that do not involve explicit state estimation and do not use any physics prior. We also show that our approach achieves more efficient manipulation, both in simulation and on a real robot, when used within a model predictive controller.
MeteorNet: Deep Learning on Dynamic 3D Point Cloud Sequences
Oct 21, 2019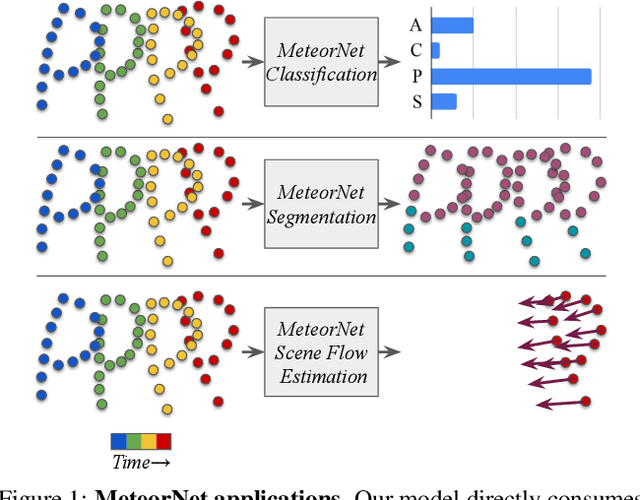
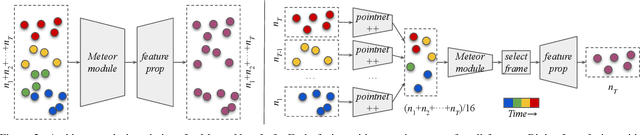
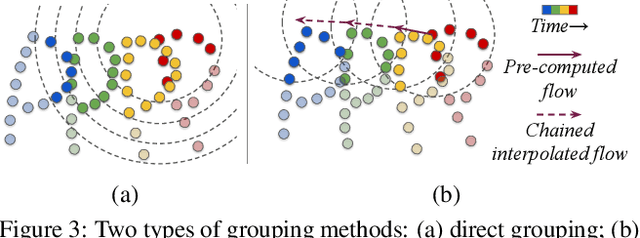
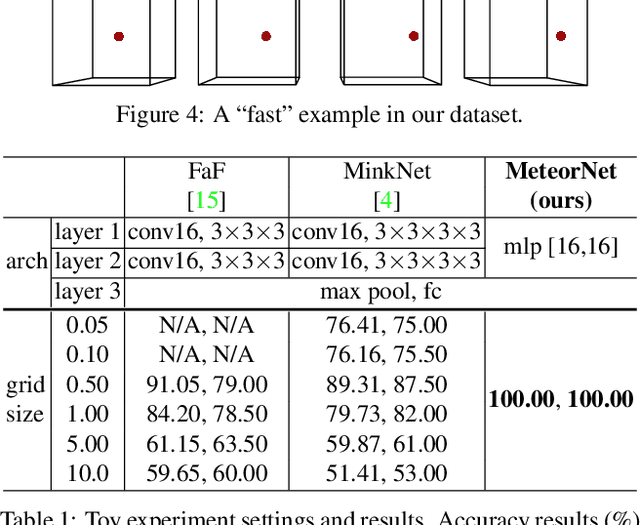
Understanding dynamic 3D environment is crucial for robotic agents and many other applications. We propose a novel neural network architecture called $MeteorNet$ for learning representations for dynamic 3D point cloud sequences. Different from previous work that adopts a grid-based representation and applies 3D or 4D convolutions, our network directly processes point clouds. We propose two ways to construct spatiotemporal neighborhoods for each point in the point cloud sequence. Information from these neighborhoods is aggregated to learn features per point. We benchmark our network on a variety of 3D recognition tasks including action recognition, semantic segmentation and scene flow estimation. MeteorNet shows stronger performance than previous grid-based methods while achieving state-of-the-art performance on Synthia. MeteorNet also outperforms previous baseline methods that are able to process at most two consecutive point clouds. To the best of our knowledge, this is the first work on deep learning for dynamic raw point cloud sequences.