 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightGTS-Cov: Covariate-Enhanced Time Series Forecasting
Feb 11, 2026Time series foundation models are typically pre-trained on large, multi-source datasets; however, they often ignore exogenous covariates or incorporate them via simple concatenation with the target series, which limits their effectiveness in covariate-rich applications such as electricity price forecasting and renewable energy forecasting. We introduce LightGTS-Cov, a covariate-enhanced extension of LightGTS that preserves its lightweight, period-aware backbone while explicitly incorporating both past and future-known covariates. Built on a $\sim$1M-parameter LightGTS backbone, LightGTS-Cov adds only a $\sim$0.1M-parameter MLP plug-in that integrates time-aligned covariates into the target forecasts by residually refining the outputs of the decoding process. Across covariate-aware benchmarks on electricity price and energy generation datasets, LightGTS-Cov consistently outperforms LightGTS and achieves superior performance over other covariate-aware baselines under both settings, regardless of whether future-known covariates are provided. We further demonstrate its practical value in two real-world energy case applications: long-term photovoltaic power forecasting with future weather forecasts and day-ahead electricity price forecasting with weather and dispatch-plan covariates. Across both applications, LightGTS-Cov achieves strong forecasting accuracy and stable operational performance after deployment, validating its effectiveness in real-world industrial settings.
CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025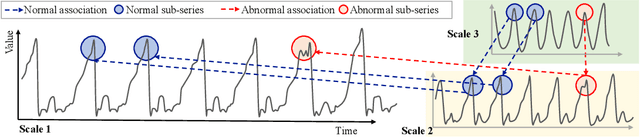
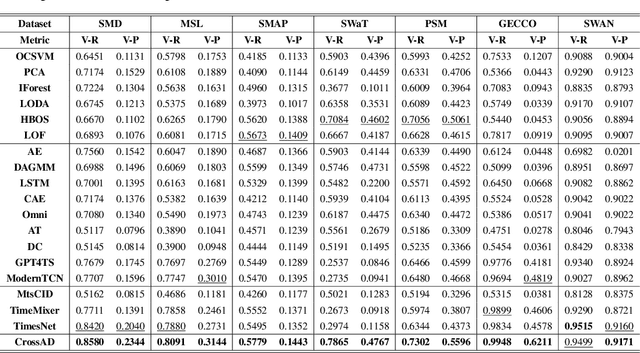
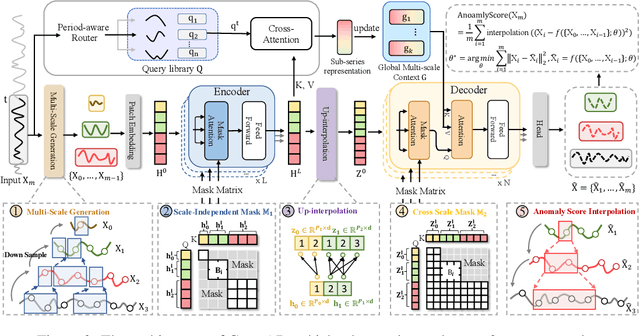
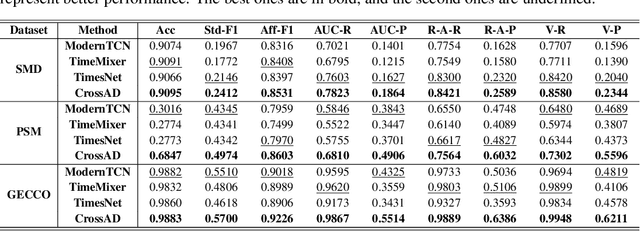
Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.
Cardiac and respiratory motion extraction for MRI using Pilot Tone-a patient study
Jan 31, 2022Background:The Pilot Tone (PT) technology allows contactless monitoring of physiological motion during the MRI scan. Several studies have shown that both respiratory and cardiac motion can be extracted from the PT signal successfully. However, most of these studies were performed in healthy volunteers. In this study, we seek to evaluate the accuracy and reliability of the cardiac and respiratory signals extracted from PT in patients clinically referred for cardiovascular MRI (CMR). Methods: Twenty-three patients were included in this study, each scanned under free-breathing conditions using a balanced steady-state free-precession real-time (RT) cine sequence on a 1.5T scanner. The PT signal was generated by a built-in PT transmitter integrated within the body array coil. For comparison, ECG and BioMatrix (BM) respiratory sensor signals were also synchronously recorded. To assess the performances of PT, ECG, and BM, cardiac and respiratory signals extracted from the RT cine images were used as the ground truth. Results: The respiratory motion extracted from PT correlated positively with the image-derived respiratory signal in all cases and showed a stronger correlation (absolute coefficient: 0.95-0.09) than BM (0.72-0.24). For the cardiac signal, the precision of PT-based triggers (standard deviation of PT trigger locations relative to ECG triggers) ranged from 6.6 to 81.2 ms (median 19.5 ms). Overall, the performance of PT-based trigger extraction was comparable to that of ECG. Conclusions: This study demonstrates the potential of PT to monitor both respiratory and cardiac motion in patients clinically referred for CMR.
Neural Retrieval for Question Answering with Cross-Attention Supervised Data Augmentation
Sep 29, 2020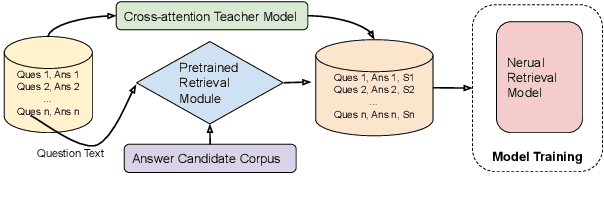
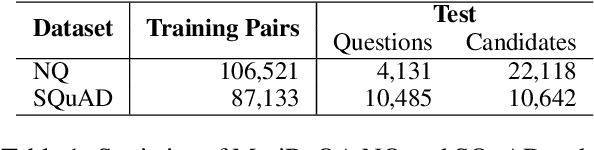
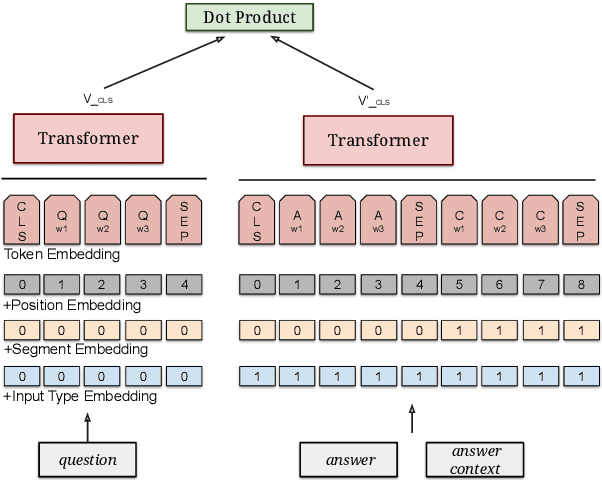
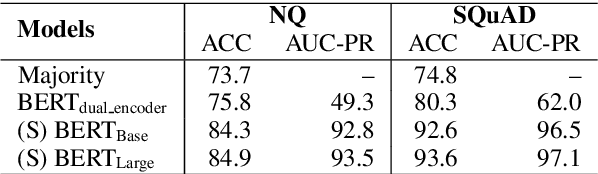
Neural models that independently project questions and answers into a shared embedding space allow for efficient continuous space retrieval from large corpora. Independently computing embeddings for questions and answers results in late fusion of information related to matching questions to their answers. While critical for efficient retrieval, late fusion underperforms models that make use of early fusion (e.g., a BERT based classifier with cross-attention between question-answer pairs). We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The accurate cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at $N$ (P@N) and Mean Reciprocal Rank (MRR).
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Nov 14, 2019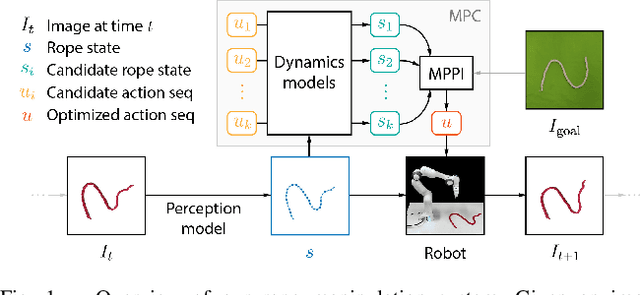
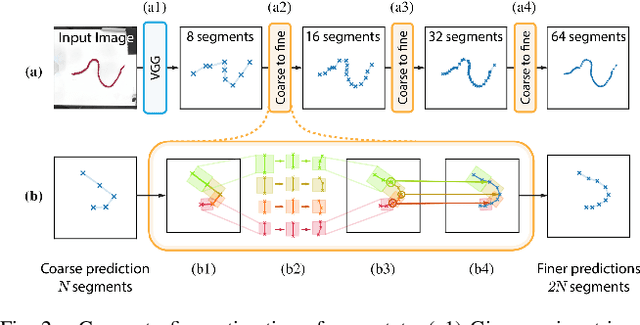
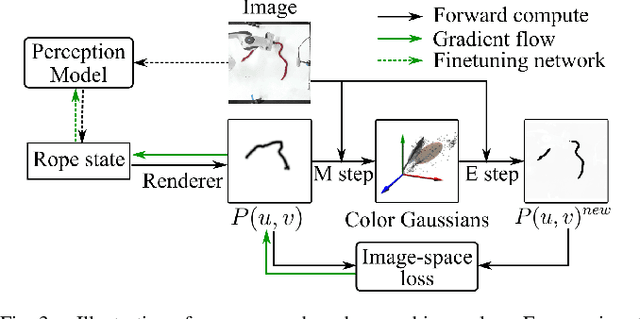
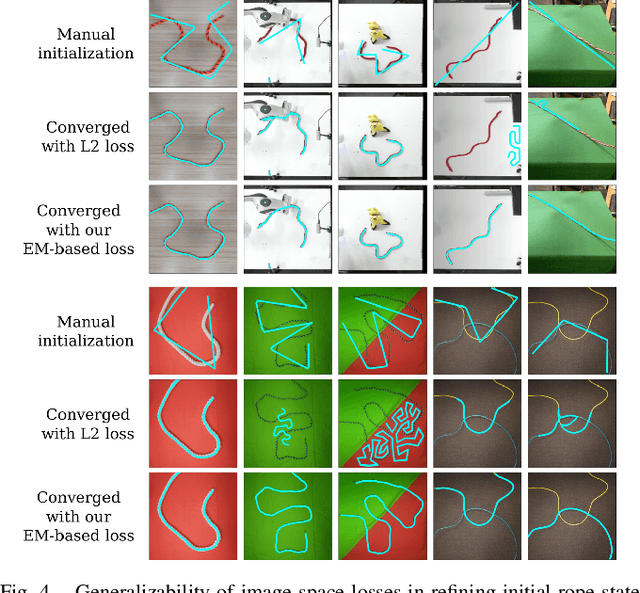
We demonstrate model-based, visual robot manipulation of linear deformable objects. Our approach is based on a state-space representation of the physical system that the robot aims to control. This choice has multiple advantages, including the ease of incorporating physical priors in the dynamics model and perception model, and the ease of planning manipulation actions. In addition, physical states can naturally represent object instances of different appearances. Therefore, dynamics in the state space can be learned in one setting and directly used in other visually different settings. This is in contrast to dynamics learned in pixel space or latent space, where generalization to visual differences are not guaranteed. Challenges in taking the state-space approach are the estimation of the high-dimensional state of a deformable object from raw images, where annotations are very expensive on real data, and finding a dynamics model that is both accurate, generalizable, and efficient to compute. We are the first to demonstrate self-supervised training of rope state estimation on real images, without requiring expensive annotations. This is achieved by our novel differentiable renderer and image loss, which are generalizable across a wide range of visual appearances. With estimated rope states, we train a fast and differentiable neural network dynamics model that encodes the physics of mass-spring systems. Our method has a higher accuracy in predicting future states compared to models that do not involve explicit state estimation and do not use any physics prior. We also show that our approach achieves more efficient manipulation, both in simulation and on a real robot, when used within a model predictive controller.
A Pixel-Based Framework for Data-Driven Clothing
Dec 03, 2018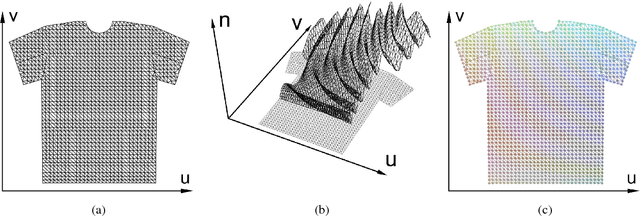
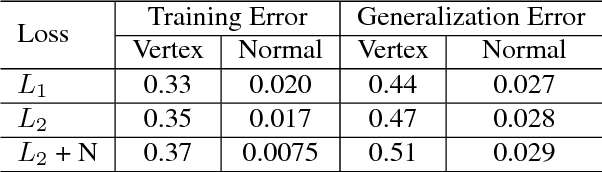
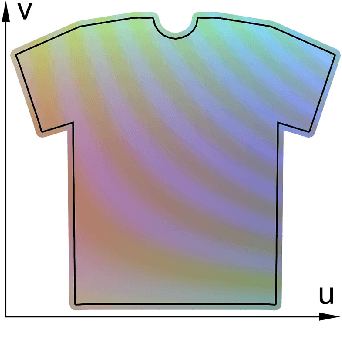
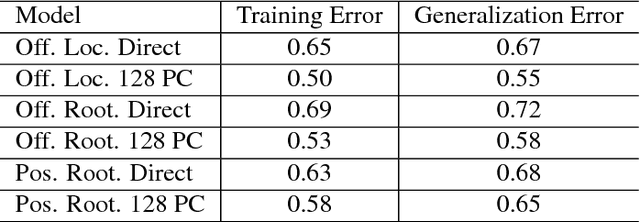
With the aim of creating virtual cloth deformations more similar to real world clothing, we propose a new computational framework that recasts three dimensional cloth deformation as an RGB image in a two dimensional pattern space. Then a three dimensional animation of cloth is equivalent to a sequence of two dimensional RGB images, which in turn are driven/choreographed via animation parameters such as joint angles. This allows us to leverage popular CNNs to learn cloth deformations in image space. The two dimensional cloth pixels are extended into the real world via standard body skinning techniques, after which the RGB values are interpreted as texture offsets and displacement maps. Notably, we illustrate that our approach does not require accurate unclothed body shapes or robust skinning techniques. Additionally, we discuss how standard image based techniques such as image partitioning for higher resolution, GANs for merging partitioned image regions back together, etc., can readily be incorporated into our framework.
Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos
Jun 09, 2017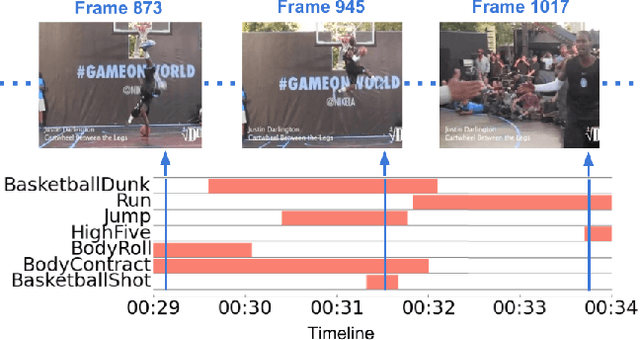
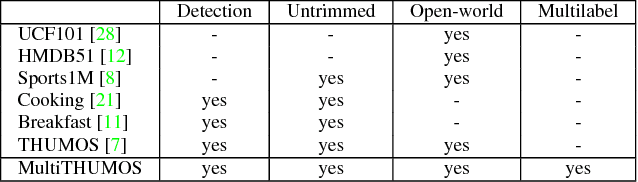

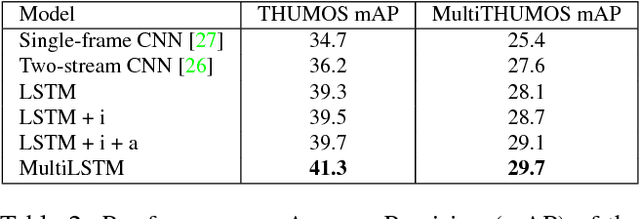
Every moment counts in action recognition. A comprehensive understanding of human activity in video requires labeling every frame according to the actions occurring, placing multiple labels densely over a video sequence. To study this problem we extend the existing THUMOS dataset and introduce MultiTHUMOS, a new dataset of dense labels over unconstrained internet videos. Modeling multiple, dense labels benefits from temporal relations within and across classes. We define a novel variant of long short-term memory (LSTM) deep networks for modeling these temporal relations via multiple input and output connections. We show that this model improves action labeling accuracy and further enables deeper understanding tasks ranging from structured retrieval to action prediction.