 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRA: Boosting Time Series Foundation Models for Multivariate Forecasting through Correlation-aware Adapter
Mar 23, 2026Most existing Time Series Foundation Models (TSFMs) use channel independent modeling and focus on capturing and generalizing temporal dependencies, while neglecting the correlations among channels or overlooking the different aspects of correlations. However, these correlations play a vital role in Multivariate time series forecasting. To address this, we propose a CoRrelation-aware Adapter (CoRA), a lightweight plug-and-play method that requires only fine-tuning with TSFMs and is able to capture different types of correlations, so as to improve forecast performance. Specifically, to reduce complexity, we innovatively decompose the correlation matrix into low-rank Time-Varying and Time-Invariant components. For the Time-Varying component, we further design learnable polynomials to learn dynamic correlations by capturing trends or periodic patterns. To learn positive and negative correlations that appear only among some channels, we introduce a novel dual contrastive learning method that identifies correlations through projection layers, regulated by a Heterogeneous-Partial contrastive loss during training, without introducing additional complexity in the inference stage. Extensive experiments on 10 real-world datasets demonstrate that CoRA can improve TSFMs in multivariate forecasting performance.
Towards Multimodal Time Series Anomaly Detection with Semantic Alignment and Condensed Interaction
Mar 23, 2026Time series anomaly detection plays a critical role in many dynamic systems. Despite its importance, previous approaches have primarily relied on unimodal numerical data, overlooking the importance of complementary information from other modalities. In this paper, we propose a novel multimodal time series anomaly detection model (MindTS) that focuses on addressing two key challenges: (1) how to achieve semantically consistent alignment across heterogeneous multimodal data, and (2) how to filter out redundant modality information to enhance cross-modal interaction effectively. To address the first challenge, we propose Fine-grained Time-text Semantic Alignment. It integrates exogenous and endogenous text information through cross-view text fusion and a multimodal alignment mechanism, achieving semantically consistent alignment between time and text modalities. For the second challenge, we introduce Content Condenser Reconstruction, which filters redundant information within the aligned text modality and performs cross-modal reconstruction to enable interaction. Extensive experiments on six real-world multimodal datasets demonstrate that the proposed MindTS achieves competitive or superior results compared to existing methods. The code is available at: https://github.com/decisionintelligence/MindTS.
Unlocking the Value of Text: Event-Driven Reasoning and Multi-Level Alignment for Time Series Forecasting
Mar 16, 2026Existing time series forecasting methods primarily rely on the numerical data itself. However, real-world time series exhibit complex patterns associated with multimodal information, making them difficult to predict with numerical data alone. While several multimodal time series forecasting methods have emerged, they either utilize text with limited supplementary information or focus merely on representation extraction, extracting minimal textual information for forecasting. To unlock the Value of Text, we propose VoT, a method with Event-driven Reasoning and Multi-level Alignment. Event-driven Reasoning combines the rich information in exogenous text with the powerful reasoning capabilities of LLMs for time series forecasting. To guide the LLMs in effective reasoning, we propose the Historical In-context Learning that retrieves and applies historical examples as in-context guidance. To maximize the utilization of text, we propose Multi-level Alignment. At the representation level, we utilize the Endogenous Text Alignment to integrate the endogenous text information with the time series. At the prediction level, we design the Adaptive Frequency Fusion to fuse the frequency components of event-driven prediction and numerical prediction to achieve complementary advantages. Experiments on real-world datasets across 10 domains demonstrate significant improvements over existing methods, validating the effectiveness of our approach in the utilization of text. The code is made available at https://github.com/decisionintelligence/VoT.
PATRA: Pattern-Aware Alignment and Balanced Reasoning for Time Series Question Answering
Feb 26, 2026Time series reasoning demands both the perception of complex dynamics and logical depth. However, existing LLM-based approaches exhibit two limitations: they often treat time series merely as text or images, failing to capture the patterns like trends and seasonalities needed to answer specific questions; and when trained on a mix of simple and complex tasks, simpler objectives often dominate the learning process, hindering the development of deep reasoning capabilities. To address these limitations, we propose the Pattern-Aware Alignment and Balanced Reasoning model (PATRA), introducing a pattern-aware mechanism that extracts trend and seasonality patterns from time series to achieve deep alignment. Furthermore, we design a task-aware balanced reward to harmonize learning across tasks of varying difficulty, incentivizing the generation of coherent Chains of Thought. Extensive experiments show that PATRA outperforms strong baselines across diverse Time Series Question Answering (TSQA) tasks, demonstrating superior cross-modal understanding and reasoning capability.
ST-EVO: Towards Generative Spatio-Temporal Evolution of Multi-Agent Communication Topologies
Feb 16, 2026LLM-powered Multi-Agent Systems (MAS) have emerged as an effective approach towards collaborative intelligence, and have attracted wide research interests. Among them, ``self-evolving'' MAS, treated as a more flexible and powerful technical route, can construct task-adaptive workflows or communication topologies, instead of relying on a predefined static structue template. Current self-evolving MAS mainly focus on Spatial Evolving or Temporal Evolving paradigm, which only considers the single dimension of evolution and does not fully incentivize LLMs' collaborative capability. In this work, we start from a novel Spatio-Temporal perspective by proposing ST-EVO, which supports dialogue-wise communication scheduling with a compact yet powerful flow-matching based Scheduler. To make precise Spatio-Temporal scheduling, ST-EVO can also perceive the uncertainty of MAS, and possesses self-feedback ability to learn from accumulated experience. Extensive experiments on nine benchmarks demonstrate the state-of-the-art performance of ST-EVO, achieving about 5%--25% accuracy improvement.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Towards Non-Stationary Time Series Forecasting with Temporal Stabilization and Frequency Differencing
Nov 17, 2025Time series forecasting is critical for decision-making across dynamic domains such as energy, finance, transportation, and cloud computing. However, real-world time series often exhibit non-stationarity, including temporal distribution shifts and spectral variability, which pose significant challenges for long-term time series forecasting. In this paper, we propose DTAF, a dual-branch framework that addresses non-stationarity in both the temporal and frequency domains. For the temporal domain, the Temporal Stabilizing Fusion (TFS) module employs a non-stationary mix of experts (MOE) filter to disentangle and suppress temporal non-stationary patterns while preserving long-term dependencies. For the frequency domain, the Frequency Wave Modeling (FWM) module applies frequency differencing to dynamically highlight components with significant spectral shifts. By fusing the complementary outputs of TFS and FWM, DTAF generates robust forecasts that adapt to both temporal and frequency domain non-stationarity. Extensive experiments on real-world benchmarks demonstrate that DTAF outperforms state-of-the-art baselines, yielding significant improvements in forecasting accuracy under non-stationary conditions. All codes are available at https://github.com/PandaJunk/DTAF.
SwiftTS: A Swift Selection Framework for Time Series Pre-trained Models via Multi-task Meta-Learning
Oct 27, 2025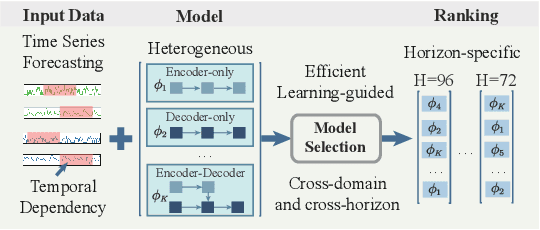
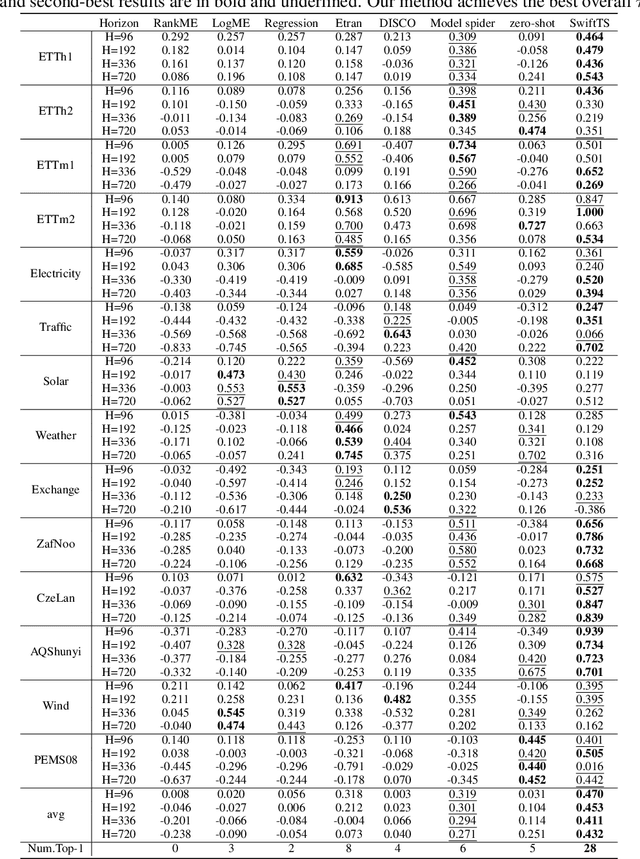
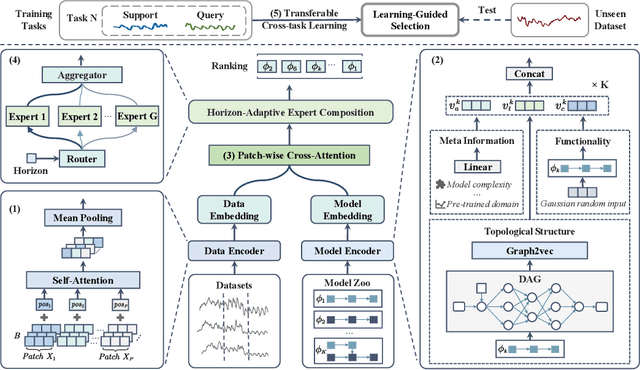
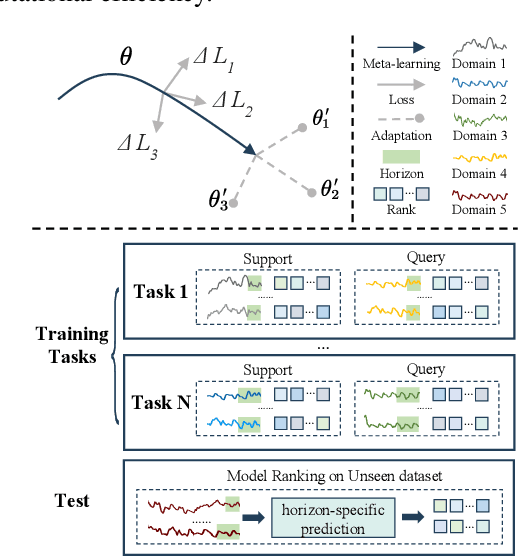
Pre-trained models exhibit strong generalization to various downstream tasks. However, given the numerous models available in the model hub, identifying the most suitable one by individually fine-tuning is time-consuming. In this paper, we propose \textbf{SwiftTS}, a swift selection framework for time series pre-trained models. To avoid expensive forward propagation through all candidates, SwiftTS adopts a learning-guided approach that leverages historical dataset-model performance pairs across diverse horizons to predict model performance on unseen datasets. It employs a lightweight dual-encoder architecture that embeds time series and candidate models with rich characteristics, computing patchwise compatibility scores between data and model embeddings for efficient selection. To further enhance the generalization across datasets and horizons, we introduce a horizon-adaptive expert composition module that dynamically adjusts expert weights, and the transferable cross-task learning with cross-dataset and cross-horizon task sampling to enhance out-of-distribution (OOD) robustness. Extensive experiments on 14 downstream datasets and 8 pre-trained models demonstrate that SwiftTS achieves state-of-the-art performance in time series pre-trained model selection.
CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025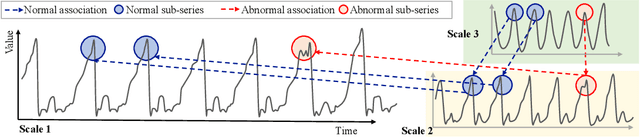
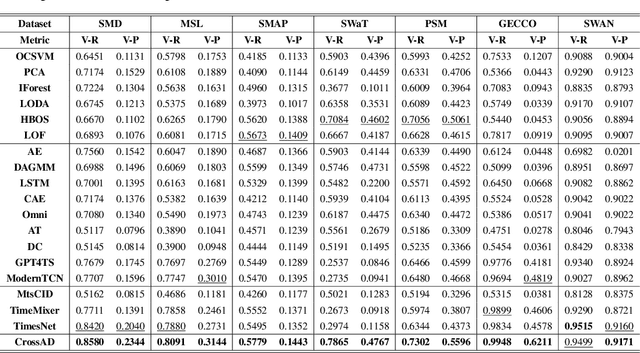
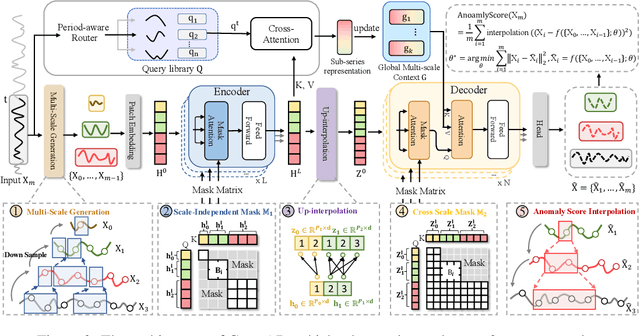
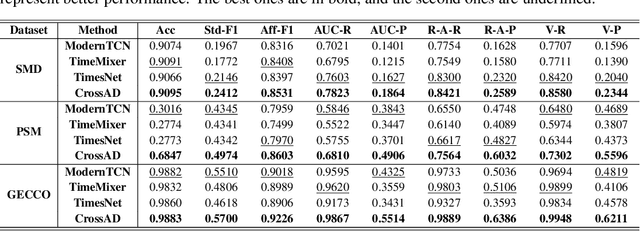
Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.
Aurora: Towards Universal Generative Multimodal Time Series Forecasting
Sep 26, 2025Cross-domain generalization is very important in Time Series Forecasting because similar historical information may lead to distinct future trends due to the domain-specific characteristics. Recent works focus on building unimodal time series foundation models and end-to-end multimodal supervised models. Since domain-specific knowledge is often contained in modalities like texts, the former lacks the explicit utilization of them, thus hindering the performance. The latter is tailored for end-to-end scenarios and does not support zero-shot inference for cross-domain scenarios. In this work, we introduce Aurora, a Multimodal Time Series Foundation Model, which supports multimodal inputs and zero-shot inference. Pretrained on Corss-domain Multimodal Time Series Corpus, Aurora can adaptively extract and focus on key domain knowledge contained in corrsponding text or image modalities, thus possessing strong Cross-domain generalization capability. Through tokenization, encoding, and distillation, Aurora can extract multimodal domain knowledge as guidance and then utilizes a Modality-Guided Multi-head Self-Attention to inject them into the modeling of temporal representations. In the decoding phase, the multimodal representations are used to generate the conditions and prototypes of future tokens, contributing to a novel Prototype-Guided Flow Matching for generative probabilistic forecasting. Comprehensive experiments on well-recognized benchmarks, including TimeMMD, TSFM-Bench and ProbTS, demonstrate the consistent state-of-the-art performance of Aurora on both unimodal and multimodal scenarios.