 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAimTS: Augmented Series and Image Contrastive Learning for Time Series Classification
Apr 14, 2025Time series classification (TSC) is an important task in time series analysis. Existing TSC methods mainly train on each single domain separately, suffering from a degradation in accuracy when the samples for training are insufficient in certain domains. The pre-training and fine-tuning paradigm provides a promising direction for solving this problem. However, time series from different domains are substantially divergent, which challenges the effective pre-training on multi-source data and the generalization ability of pre-trained models. To handle this issue, we introduce Augmented Series and Image Contrastive Learning for Time Series Classification (AimTS), a pre-training framework that learns generalizable representations from multi-source time series data. We propose a two-level prototype-based contrastive learning method to effectively utilize various augmentations in multi-source pre-training, which learns representations for TSC that can be generalized to different domains. In addition, considering augmentations within the single time series modality are insufficient to fully address classification problems with distribution shift, we introduce the image modality to supplement structural information and establish a series-image contrastive learning to improve the generalization of the learned representations for TSC tasks. Extensive experiments show that after multi-source pre-training, AimTS achieves good generalization performance, enabling efficient learning and even few-shot learning on various downstream TSC datasets.
TARGA: Targeted Synthetic Data Generation for Practical Reasoning over Structured Data
Dec 27, 2024



Semantic parsing, which converts natural language questions into logic forms, plays a crucial role in reasoning within structured environments. However, existing methods encounter two significant challenges: reliance on extensive manually annotated datasets and limited generalization capability to unseen examples. To tackle these issues, we propose Targeted Synthetic Data Generation (TARGA), a practical framework that dynamically generates high-relevance synthetic data without manual annotation. Starting from the pertinent entities and relations of a given question, we probe for the potential relevant queries through layer-wise expansion and cross-layer combination. Then we generate corresponding natural language questions for these constructed queries to jointly serve as the synthetic demonstrations for in-context learning. Experiments on multiple knowledge base question answering (KBQA) datasets demonstrate that TARGA, using only a 7B-parameter model, substantially outperforms existing non-fine-tuned methods that utilize close-sourced model, achieving notable improvements in F1 scores on GrailQA(+7.7) and KBQA-Agent(+12.2). Furthermore, TARGA also exhibits superior sample efficiency, robustness, and generalization capabilities under non-I.I.D. settings.
Visual Perception in Text Strings
Oct 02, 2024



Understanding visual semantics embedded in consecutive characters is a crucial capability for both large language models (LLMs) and multi-modal large language models (MLLMs). This type of artifact possesses the unique characteristic that identical information can be readily formulated in both texts and images, making them a significant proxy for analyzing modern LLMs' and MLLMs' capabilities in modality-agnostic vision understanding. In this work, we select ASCII art as a representative artifact, where the lines and brightness used to depict each concept are rendered by characters, and we frame the problem as an ASCII art recognition task. We benchmark model performance on this task by constructing an evaluation dataset with an elaborate categorization tree and also collect a training set to elicit the models' visual perception ability. Through a comprehensive analysis of dozens of models, results reveal that although humans can achieve nearly 100% accuracy, the state-of-the-art LLMs and MLLMs lag far behind. Models are capable of recognizing concepts depicted in the ASCII arts given only text inputs indicated by over 60% accuracy for some concepts, but most of them achieves merely around 30% accuracy when averaged across all categories. When provided with images as inputs, GPT-4o gets 82.68%, outperforming the strongest open-source MLLM by 21.95%. Although models favor different kinds of ASCII art depending on the modality provided, none of the MLLMs successfully benefit when both modalities are supplied simultaneously. Moreover, supervised fine-tuning helps improve models' accuracy especially when provided with the image modality, but also highlights the need for better training techniques to enhance the information fusion among modalities.
QueryAgent: A Reliable and Efficient Reasoning Framework with Environmental Feedback based Self-Correction
Mar 18, 2024



Employing Large Language Models (LLMs) for semantic parsing has achieved remarkable success. However, we find existing methods fall short in terms of reliability and efficiency when hallucinations are encountered. In this paper, we address these challenges with a framework called QueryAgent, which solves a question step-by-step and performs step-wise self-correction. We introduce an environmental feedback-based self-correction method called ERASER. Unlike traditional approaches, ERASER leverages rich environmental feedback in the intermediate steps to perform selective and differentiated self-correction only when necessary. Experimental results demonstrate that QueryAgent notably outperforms all previous few-shot methods using only one example on GrailQA and GraphQ by 7.0 and 15.0 F1. Moreover, our approach exhibits superiority in terms of efficiency, including runtime, query overhead, and API invocation costs. By leveraging ERASER, we further improve another baseline (i.e., AgentBench) by approximately 10 points, revealing the strong transferability of our approach.
MarkQA: A large scale KBQA dataset with numerical reasoning
Oct 24, 2023


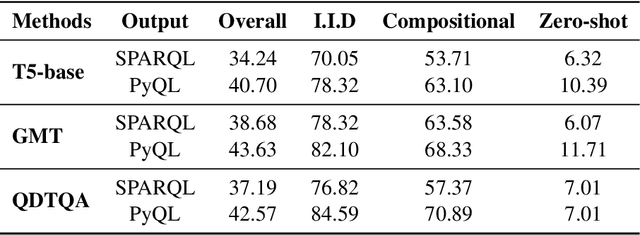
While question answering over knowledge bases (KBQA) has shown progress in addressing factoid questions, KBQA with numerical reasoning remains relatively unexplored. In this paper, we focus on the complex numerical reasoning in KBQA and propose a new task, NR-KBQA, which necessitates the ability to perform both multi-hop reasoning and numerical reasoning. We design a logic form in Python format called PyQL to represent the reasoning process of numerical reasoning questions. To facilitate the development of NR-KBQA, we present a large dataset called MarkQA, which is automatically constructed from a small set of seeds. Each question in MarkQA is equipped with its corresponding SPARQL query, alongside the step-by-step reasoning process in the QDMR format and PyQL program. Experimental results of some state-of-the-art QA methods on the MarkQA show that complex numerical reasoning in KBQA faces great challenges.
Pareto Invariant Representation Learning for Multimedia Recommendation
Aug 23, 2023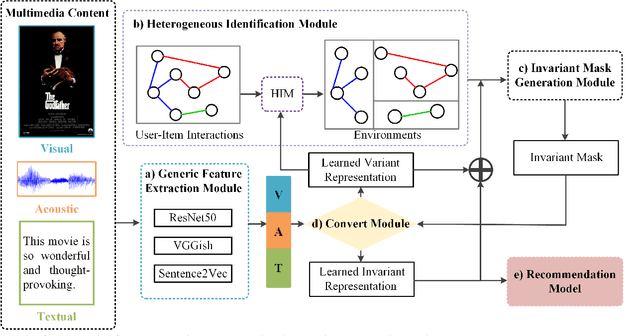
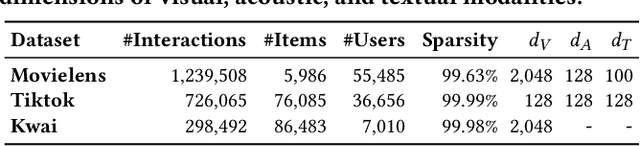
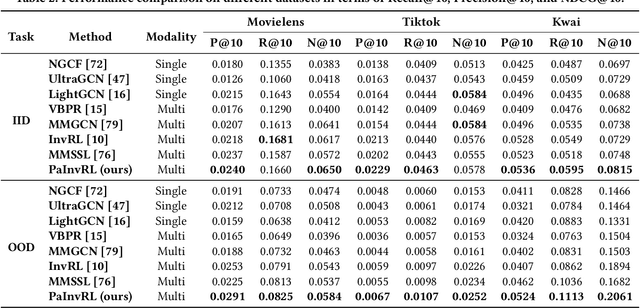
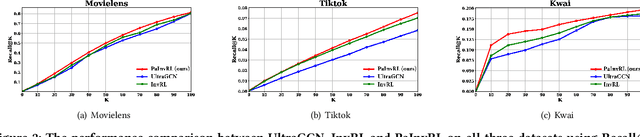
Multimedia recommendation involves personalized ranking tasks, where multimedia content is usually represented using a generic encoder. However, these generic representations introduce spurious correlations that fail to reveal users' true preferences. Existing works attempt to alleviate this problem by learning invariant representations, but overlook the balance between independent and identically distributed (IID) and out-of-distribution (OOD) generalization. In this paper, we propose a framework called Pareto Invariant Representation Learning (PaInvRL) to mitigate the impact of spurious correlations from an IID-OOD multi-objective optimization perspective, by learning invariant representations (intrinsic factors that attract user attention) and variant representations (other factors) simultaneously. Specifically, PaInvRL includes three iteratively executed modules: (i) heterogeneous identification module, which identifies the heterogeneous environments to reflect distributional shifts for user-item interactions; (ii) invariant mask generation module, which learns invariant masks based on the Pareto-optimal solutions that minimize the adaptive weighted Invariant Risk Minimization (IRM) and Empirical Risk (ERM) losses; (iii) convert module, which generates both variant representations and item-invariant representations for training a multi-modal recommendation model that mitigates spurious correlations and balances the generalization performance within and cross the environmental distributions. We compare the proposed PaInvRL with state-of-the-art recommendation models on three public multimedia recommendation datasets (Movielens, Tiktok, and Kwai), and the experimental results validate the effectiveness of PaInvRL for both within- and cross-environmental learning.
Statistically Profiling Biases in Natural Language Reasoning Datasets and Models
Feb 09, 2021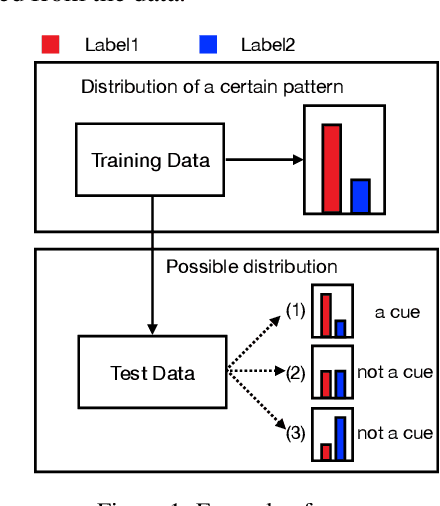

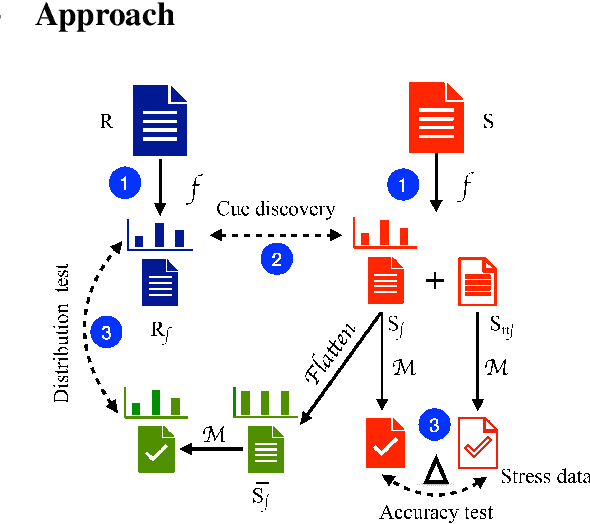
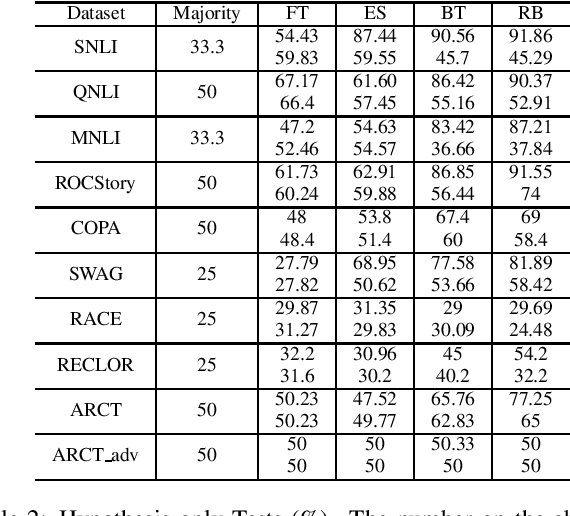
Recent work has indicated that many natural language understanding and reasoning datasets contain statistical cues that may be taken advantaged of by NLP models whose capability may thus be grossly overestimated. To discover the potential weakness in the models, some human-designed stress tests have been proposed but they are expensive to create and do not generalize to arbitrary models. We propose a light-weight and general statistical profiling framework, ICQ (I-See-Cue), which automatically identifies possible biases in any multiple-choice NLU datasets without the need to create any additional test cases, and further evaluates through blackbox testing the extent to which models may exploit these biases.
AMRec: An Intelligent System for Academic Method Recommendation
Apr 10, 2019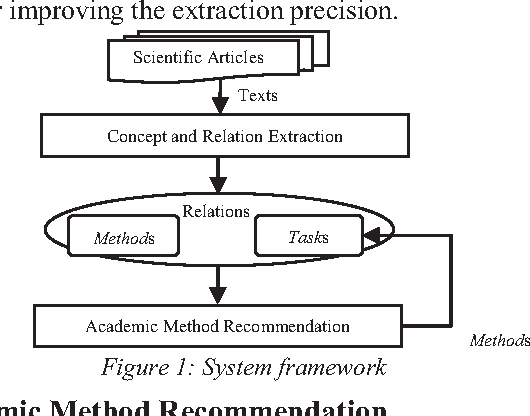
Finding new academic Methods for research problems is the key task in a researcher's research career. It is usually very difficult for new researchers to find good Methods for their research problems since they lack of research experiences. In order to help researchers carry out their researches in a more convenient way, we describe a novel recommendation system called AMRec to recommend new academic Methods for research problems in this paper. Our proposed system first extracts academic concepts (Tasks and Methods) and their relations from academic literatures, and then leverages the regularized matrix factorization Method for academic Method recommendation. Preliminary evaluation results verify the effectiveness of our proposed system.
Deep Hashing with Triplet Quantization Loss
Oct 31, 2017



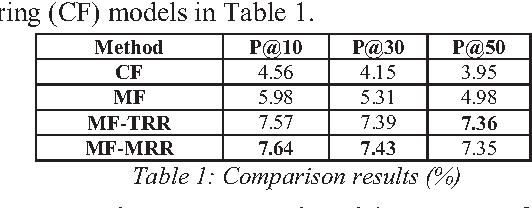
With the explosive growth of image databases, deep hashing, which learns compact binary descriptors for images, has become critical for fast image retrieval. Many existing deep hashing methods leverage quantization loss, defined as distance between the features before and after quantization, to reduce the error from binarizing features. While minimizing the quantization loss guarantees that quantization has minimal effect on retrieval accuracy, it unfortunately significantly reduces the expressiveness of features even before the quantization. In this paper, we show that the above definition of quantization loss is too restricted and in fact not necessary for maintaining high retrieval accuracy. We therefore propose a new form of quantization loss measured in triplets. The core idea of the triplet quantization loss is to learn discriminative real-valued descriptors which lead to minimal loss on retrieval accuracy after quantization. Extensive experiments on two widely used benchmark data sets of different scales, CIFAR-10 and In-shop, demonstrate that the proposed method outperforms the state-of-the-art deep hashing methods. Moreover, we show that the compact binary descriptors obtained with triplet quantization loss lead to very small performance drop after quantization.
Unsupervised Triplet Hashing for Fast Image Retrieval
Feb 28, 2017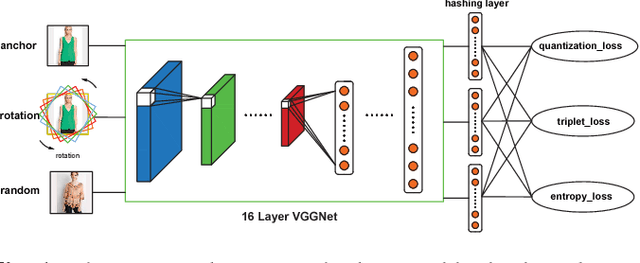
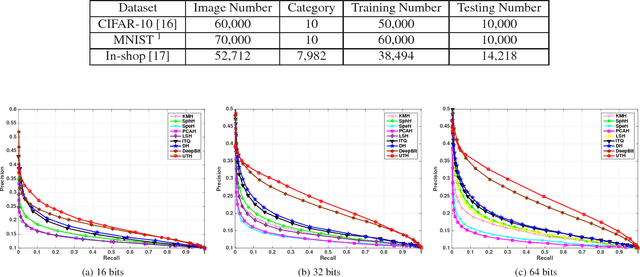
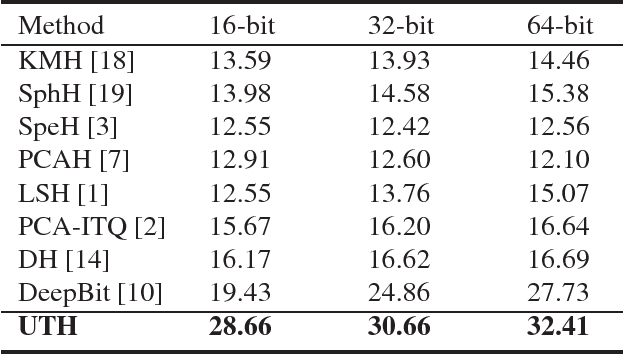
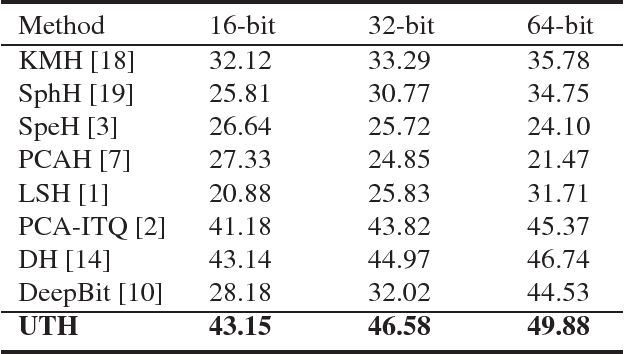
Hashing has played a pivotal role in large-scale image retrieval. With the development of Convolutional Neural Network (CNN), hashing learning has shown great promise. But existing methods are mostly tuned for classification, which are not optimized for retrieval tasks, especially for instance-level retrieval. In this study, we propose a novel hashing method for large-scale image retrieval. Considering the difficulty in obtaining labeled datasets for image retrieval task in large scale, we propose a novel CNN-based unsupervised hashing method, namely Unsupervised Triplet Hashing (UTH). The unsupervised hashing network is designed under the following three principles: 1) more discriminative representations for image retrieval; 2) minimum quantization loss between the original real-valued feature descriptors and the learned hash codes; 3) maximum information entropy for the learned hash codes. Extensive experiments on CIFAR-10, MNIST and In-shop datasets have shown that UTH outperforms several state-of-the-art unsupervised hashing methods in terms of retrieval accuracy.